"An international team of researchers has successfully built the first
high-performance, commercial-scale tandem solar cell that does not rely on
indium, a scarce and expensive metal, replacing it instead with a material that
"“Wild claims” that fire fighters will not attend fires on properties hosting
power lines that form part of a contested transmission network upgrade in
regional Victoria have been called out as “disingenuous” and “potential
"It would be fair to say that the new Hilux electric ute has divided opinions
like few other EVs on offer in Australia, even before its first deliveries: Why
the limited range? Will it tow my boat? Can it carry a load?
"It’s Saturday night and you’ve downloaded a new food delivery app. You’ve
scanned the menus, picked some Mexican dishes, placed your order and are now
tracking the delivery. But your food never comes – and you never expected it
"In regional Victoria, 10 towns are currently getting a harsh preview of
Australia’s energy future. The local gas supplier announced it will shut down
its network by the end of 2026, leaving residents scrambling to replace their
"The sudden death of actor Sam Neill prompted tributes from colleagues and fans
worldwide. But the news also resonated strongly with many palaeontologists, for
whom Neill’s character in Jurassic Park, Dr Alan Grant, was a pivotal
Things are slowly getting back into gear after my trip and the last week being mostly for other life matters. Let’s share some code!
I’ve got half of the material for our sponsorship drive ready to go. On Friday I plan to write the kickoff post and then we can run this over August. A little later than I hoped, but worth it to get Hanami 3.0 out!
I merged this fix to avoid namespace conflicts for hanami generate commands. Thanks mddelk!
I started a big triage of all the open issues for dry-schema and dry-validation. There’s a bunch I can close already, and then the rest I plan to group into themes and work out how to address them. These two repos account for nearly half of dry-rb’s open issues, so work here will mean a lot for the health of our ecosystem! I haven’t done much beyond the triage yet, and I do want to be deliberate in working through everything—I expect this to be my slow burn project for the remainder of the year. It won’t happen overnight, but it will happen.
We’re due a patch release for a few different gems, matter of fact. But before I do any of those, I wanted to address some feedback about the noisiness of the release posts in our forum. So I updated our forum announcer to keep each gem’s patch releases together in a single topic, and all Hanami gem release announcements together in a single topic. I’ll try to exercise this soon!
A few times now I have worked for organizations that are basically IT shops — that is, their core business now depends on being very good at doing Computer Things. However, many of these places were pretty terrible at computers. Let’s keep picking on Telstra, because its an easier example.
Telstra was originally a part of the Post Master General’s Department of the Commonwealth of Australia’s government. That is, it was a branch of the Post Office. This means it inherited a lot of Government Culture, mostly around wearing suits and being terrible at making sensible business decisions.
Over time telephony became a big deal, and the phone branch was split out into what we called at the time Telecom Australia. Somewhere along the line it was rebranded to Telstra. I would say that was associated with the government selling it off into private hands, but I don’t think that is true — there was a long phase where the overseas operations of Telecom Australia operated under the name Telstra, and that all predated privatization.
Throughout this entire history the hard bits of telecommunications were switching (getting your call to the right place), and long distance (what AT&T called “long lines”). These things where done in chonky mechanical ways often with quite large amounts of electricity so the electrons wouldn’t fall out half way, if they weren’t done by a nice young lady sitting in a cupboard and manually moving cables on a plugboard. That is, telecommunications was a serious Electrical Engineering endeavor in a slightly weird relationship with really big construction projects like digging a hole between Sydney and Perth. Big buildings full of lots of electromechanical things making exciting clicking and clunking noises, except for the young ladies (who I assume did not run directly on electricity and did not click and clunk).
…and then one day Telstra woke up and all of that was no longer true. All the high voltage mechanical things had become packet switched networks (the Internet and friends), and either all the really long holes had been dug or the digging had been outsourced to three layers of subcontractors by some guy in accounting who probably thought Jack Welsh was a good person.
We should note that the telecommunications industry fought long and hard against TCP/IP and the Internet with things like Frame Relay and X.500. They just lost because their ideas were dumb. Mostly we suffer through the echoes of these battles with things like ITU standards that are both not freely available, and cover protocols people really care about like RDP, X.509 public key cryptography, and H.264 / H.265 video compression.
Now all of this is a slight ranty way of saying that this is why I think Telstra is so bad at computers now. They’re a government department that is not part of the government, who is good at things they don’t do any more, and is too arrogant to realize that perhaps they could steal some ideas from people who are int fact good at computers. That’s how you end up with a national phone network outage that might have killed people because of an ancient time server that no one has applied the vendor patches on.
The national Telstra outage last week was triggered by maintenance work that caused the system’s clocks to go back two decades, the telco says… Ms Brady told the hearing that the outage potentially could have been avoided had a 15-year-old server — which could have been replaced for $30,000 — been updated earlier.
…
Telstra executives said the SSU 2000 server that caused the outage was still supported by Scientific Devices, which supplies the technology from Microchip.
So this is Michael’s unifying theory of making good management decisions — it is important that an organization understand what it is now, not just what it might once have been.
Ok, so in a recent post I summarized some reading I had recently done about security harnesses. When I say “security harness” think “thingie which orchestrates many many LLM sessions to turn tokens and environmental stability into zero day vulnerabilities and dopamine”. That is, as Claude Code is to code generation, a security harness is to vulnerability hunting.
The next obvious step is to try one of these things and see if it does what it says it does on the tin. That is, do I get the dopamines? The problem of course is finding one.
A harness is the orchestration layer around an LLM. It controls the inputs, tools, prompts, models, state, validation gates and outputs for each stage of work. — ZephrSec
I am grateful to ZephrSec for their blog post by the way, because I was really struggling to find any good security harnesses apart from Anthropic’s reference implementation until I found this post. I also note that most of these security harness are currently C / C++ specific as best as I can tell, which is disappointing — that is, as someone interested in looking at the security of internet-facing services written in python, I am struggling a little to find good tooling.
# Clone the repo
git clone https://github.com/gadievron/raptor.git
cd raptor
# Install Python dependencies
pip install -r requirements.txt
# Install Claude Code and then make sure its on our path
curl -fsSL https://claude.ai/install.sh | bash
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrc
# Install a bunch of helpers. Fetch this gist to install-raptor-tools.sh:
# https://gist.github.com/mikalstill/2a89b59add4ec9e59986fa085ab8641d
./install-raptor-tools.sh
# Open RAPTOR from the folder RAPTOR was cloned to
bin/raptor
I decided a logical first target was instar, so I cloned it in my instance’s default user home directory, and then started a RAPTOR project:
/project create instar --target /home/debian/instar
/project use instar
/understand --map
This creates a new project, activates it, and then maps the codebase ready for scanning. instar is a fair bit of rust at about 136,000 lines of code, so the initial bootstrapping took a while.
Honestly RAPTOR felt pretty good — it didn’t consume my entire Anthropic quota, and it found something which is likely a real security bug in an allegedly security focused project within about ten minutes. I suspect its not as scalable as some of the other C / C++ harnesses, but it makes up for that by being language agnostic. I can see myself spending some more time playing with RAPTOR.
It seems like the workflow I naturally wanted to use in RAPTOR — an initial discovery phase, then fanning out to research agents, and finally coalescing down to a single conversation with the operator about what bugs were real and what issues to file — wasn’t represented in RAPTOR, so I asked Claude to add that as a new /triage command. This means I am now running a fork of RAPTOR, which you can find at github.com/mikalstill/raptor. It doesn’t feel “meaty” enough to consider contributing back just yet, but we’ll see what happens. Its entirely possible I am holding the tool wrong or something.
Now, RAPTOR doesn’t solve the massively parallel orchestration problems that Cloudflare alleged I would have in their blog posts, but even they started off with something simpler in Claude Code and then iterated. I therefore consider this a prototyping and learning phase for now.
Making a sign (or a policy) takes work. Therefore, this work is only done when some incident has caused someone somewhere to decide that the correct response is to expend effort ensuring this thing does not happen again. Now, one issue with this is that it is also a lot of effort largely in the form of risk acceptance to remove a policy or sign. So these things tend to accrue. It is rare for someone to ask if the number of mandatory training courses is still reasonable for example, because they don’t want to be the one to remove one and then eventually have to explain that in a lawsuit or coronial inquest.
So — that sign in the Telstra employee bathrooms that asks people to stop pooping on everything? That was presumably because someone decided the correct response when faced with poop all over the place was to make a sign. It is also why you should wash your hands when you leave the bathroom.
I guess as a follow-up as well — organizations should remember that visitors sometimes read their signs, even though they’re in the employee bathroom.
One of the features of systemd that is most controversial is the option to kill user processes when the user logs out. That initially killed screen/tmux/nohup processes too. In recent Debian releases the default configuration of systemd-logind (the login manager for systemd) is to allow processes to keep running, the configuration file /etc/systemd/logind.conf has an option KillUserProcesses that can be enabled to have user processes killed. If you do that then there are options to only kill processes for certain users and to exclude some users (default to excluding root). If using that option you can apparently use a systemd unit to start screen which prevents it being killed on logout.
This is a very handy feature for some particular user cases. One situation was that I was supporting some people who weren’t very good at computers on a system running KDE and some KDE processes would linger. So the option of logout and login again to deal with an issue of akonadi or some other KDE service misbehaving didn’t work. On that system I enabled the option to kill user processes which reduced the number of problems they had while not requiring rebooting.
It is widely believed that the “linger” feature is required to allow screen/tmux/nohup to work, in Debian (and probably most distributions) that is not the case. It might be that some combinations of configuration requires “linger” to allow screen/tmux to work but I am not interested in trying to discover them. Of all the people I have directly supported for Linux desktop use (which numbers in the hundreds) none of them have had the ability to use screen/tmux and also the cluelessnes that makes me want to automatically kill their processes when the logout.
Controlling Linger
You can enable and disable “linger” for your own account with the following commands if polkit is installed and in a typical configuration:
loginctl enable-linger
loginctl disable-linger
If running as root you can enable and disable it for another user with the following commands:
There doesn’t seem to be any documented way of discovering if an account has linger enabled or for listing accounts that have it, it seems that “ls /var/lib/systemd/linger” is the only option.
Linger on Debian
On a Debian system with close to default settings the processes won’t be killed on logout and the only difference “linger” makes is to start programs in the user’s context BEFORE they login. A friend was recently testing out a bunch of LLM programs on one of my servers and the account he used for that ended up with “linger” enabled, presumably one of the install scripts he ran was written on the assumption that enabling linger was necessary for nohup to work and it did so automatically without being asked.
One benefit I’ve found from this behaviour is on my laptop. I’m currently testing out new SE Linux policy on my laptop and rebooting it a lot. When I enabled linger on my account it caused the laptop to connect to wifi on boot without needing to login which is convenient. I can then ssh to it even when the X11/Wayland login configuration is broken.
I will leave it enabled after finishing these tests. Having background processes like Pipewire and Bluetooth start before I login will presumably make things slightly faster when I do login.
Related posts:
Systemd Notes A few months ago I gave a lecture about systemd...
In April last year I wrote about the failings of my Thinkpad Yoga Gen 3 and how I was going back to the Thinkpad X1 Carbon Gen5 [2]. The Gen5 in question has 8G of RAM and a 1920*1080 display compared to 16G and 2560*1440 for the Yoga but runs reliably on battery without crashing. The Yoga in question has been used by relatives who don’t need to do much when on battery and is currently being used by a relative who runs Windows so the occasional crash is something they are used to.
In mid last year I bought a Thinkpad X1 Carbon Gen6 for $350 which has 16G of RAM and a 2560*1440 display. The higher resolution display is a significant benefit and while 8G of RAM is still usable for medium to heavy Linux desktop use it does cause problems sometimes. The new laptop I now have is significantly better than the one I had for work in 2018!
I realised that my previous review of that laptop was incorrect in one aspect, there are two USB-C ports it’s just that one may be covered by a rubber stopper when you get it. When I received this one the Ethernet dongle port was covered by a rubber stopper and the seller was unaware of the possibility of using a dongle and didn’t have such a dongle. It’s not a big deal as I have a collection of USB Ethernet devices but would still be handy to have while not worth the $20 it costs to buy one (a 2.5Gbit USB Ethernet device cost me $16 two years ago).
Laptop Displays
Today I saw a Thinkpad X1 Carbon Gen9 with 3840*2400 display and 16G of RAM for $550 on Facebook marketplace, which is a very tempting deal. 3840*2400 is 2.5* as many pixels as 2560*1440 while 2560*1440 is only 77% more pixels than 1920*1080. So if my eyes were able to properly distinguish pixels that that high DPI then the benefits of getting the 3840*2400 laptop would be greater than going to what I currently have from FullHD. But as a 1440p display in a 14″ form factor is already past the stage where I can see individual pixels the benefits of 4K are more about making curves more rounded which improves readability and allows slightly smaller font sizes but doesn’t give anything like the benefits that going from a FullHD desktop monitor to a 4K desktop monitor.
Also I have different usage patterns for my laptop than for my desktop. I use my laptop for reading blog posts and ebooks for which even FullHD would be fine as the amount of text that can be usefully displayed on screen isn’t that great. I also use my laptop for emergency sysadmin work, ssh to a server to restart a daemon, run ping while changing network hardware, and other things where I don’t have a lot of text on screen.
I also use my laptop for light coding tasks while watching TV. It’s not possible to effectively do complex debugging tasks while watching TV or while using a small screen. But a very large portion of coding time is spent dealing with things like testing builds with different versions of libraries, applying patches to a new upstream release of software, fixing issues related to functions being renamed, testing to see if a new version has really fixed a bug it’s supposed to fix, and other things that don’t require a lot of skill.
I am not claiming that 4K displays aren’t great for laptops. Merely that at the current time it’s not worth $550 of my money.
Future Thinkpads
I like the Thinkpad X1 Carbon line and plan to continue buying them as they get cheap.
The Gen11 is the first one to have a minimum of 16G of RAM, the reason this is important to me is that the ones I buy aren’t the lowest model because I want more than the minimum display resolution. As people who get above the minimum spec in one area tend to get above the minimum in others that means that there will be plenty of Gen11s on the market with 32G of RAM when I’m ready to buy one of that era. Presumably by that time Linux software will have become more bloated and make me want more RAM. Yes soldered RAM has some downsides, but if you want an ultra-light laptop it’s a trade-off you need to deal with. One problem with the Gen11 is that the maximum display resolution is 2880*1800, it’s still a reasonable improvement over what I’ve currently got but not close to the 4K I desire.
The Gen12 has support for 8K display at 60Hz over Thunderbolt which is nice. By the time the Gen12 is in my price range it’s quite likely that I will have a monitor with higher than 5120*2160 resolution (the maximum video out resolution of Gen11 and previous models in the Thinkpad X1 Carbon range) on my desk.
The Gen13 still has 2880*1800 as the maximum resolution but has OLED as an option.
So it looks like a Gen9 or Gen10 may be ideal for me as they are the last ones in the Thinkpad X1 Carbon series to support 4K displays. Another option is the Thinkpad Yoga Gen8 which is of the same era as the Thinkpad X1 Carbon Gen11 but has a 3840*2400 OLED touch screen, I might be able to get one of those cheap with the touch screen damaged.
This book is a delightful collection of short stories by Hugh Howie, mostly not about actual machine learning or AI. What else can one say about a book of short stories with no overarching theme? Was good. Did enjoy.
ECC RAM corrects errors that occur in memory before it gets to the CPU. The most common form of ECC is the Hamming Code [1] which when it has R redundant bits can correct single bit errors and detect double-bit errors in messages with 2^R-R-1 bits of data. For PC use that means if you want to protect 32bits of data you need R=6 and with 64bits you need R=7. The standard for DDR4 and similar RAM is 72 bits of data width on the bus and Hamming codes to correct single bit errors and detect double bit errors for 65bits of data. The computers we use have 64bits of data so that allows an extra bit that could be an extra parity, I don’t know what if anything is done with this extra bit.
RDIMM vs UDIMM
One point of confusion in such things is the difference between Registered memory AKA RDIMMs [2] and regular PC/laptop memory which is often referred to as UDIMMs. The “register” is just a buffer which due to complex issues that aren’t relevant to this post means that DIMMs can be larger and you can have more DIMMs in a system but latency may be slightly worse. It is technically quite possible to create RDIMMs without ECC (64bits wide instead of 72) but I have never seen a system that used such RAM.
I have used more than a few systems with ECC UDIMMs and I recommend avoiding them if convenient as ECC UDIMMs are expensive on the second hand market while ECC RDIMMs can get very cheap. There are servers with ECC RDIMMs that are very unsuitable for home use (such as dual-CPU 1RU servers which are very noisy) so once they are past the 5 year tax write-off period the server chassis gets sent to ewaste and the RAM goes on the second hand market, the glut of RAM without systems to use it forces the price down.
For the systems most commonly seen there are RDIMM systems with ECC and UDIMM systems without ECC.
Chipkill
If every bit in RAM was independent of every other bit then the basic Hamming code would solve most problems. However multiple bits in the same chip may be affected by the same problem, or one chip on the DIMM might entirely fail. With every RDIMM having 18 or 36 DRAM chips there are 2 or 4 bits per chip. On DIMMs with 36 DRAM chips one chip could fail and have the errors reliably detected with a Hamming code. On DIMMs with 18 DRAM chips one failed chip can’t necessarily be detected with Hamming codes. IBM trademarked the term ChipKill for ECC systems which can cope with a single DRAM chip failing [3]. This is referred to as “Advanced ECC” on Dell and HP servers which require an even number of DIMMs. If anyone knows what coding method is used for “ChipKill” type systems then please let me know.
Systems with advanced ECC also often have features like hot-spare for RAM and RAID-1 type functionality which is interesting but not something most people who read my blog will ever want to use.
The on-die ECC is not a replacement for regular ECC, it’s a mitigation for new problems introduced. My experience of memory errors is that the majority of repeatable errors (where a system would get an error with Memtest86+ or an ECC error report repeatedly) were DIMM seating issues, I could unplug and reinsert the DIMM in question and then the same tests would pass. Those errors would not be affected by on-die ECC.
One thing that concerns me is the possibility of on-die ECC interacting with ECC on the motherboard and reducing it’s effectiveness. I haven’t been able to find out enough about how this works to determine if that’s the case. My concern is that an error of 3+ bits that’s corrected with a basic Hamming code might be more likely to create an error condition that “Advanced ECC” can’t fix than the original error.
Currently the best published research on the effectiveness of ECC on RAM errors is the Google paper published in 2009 which is based on DDR and DDR2 RAM [5]. So I don’t expect that we will see published research about even DDR4 ECC any time soon. I presume that Google and the other cloud providers are still doing such research and providing the information to DRAM vendors under NDA so we have to just hope that the DRAM vendors do what’s required to make things work correctly and allow us to buy products based on that research.
DDR5 EC4 vs EC8
DDR5 supports 2*32bit “subchannels” instead of just supporting 64bit words [6]. For DDR5 ECC RAM there are variants EC4 which has 36bits of data per subchannel and EC8 which has 40 bits. EC8 allows Hamming codes on each subchannel indepdendently. I haven’t found a reference on how exactly EC4 works, it could be reading 64bits at a time (not taking advantage of the subchannels) to use Hamming codes or it could have 1 parity bit for each subchannel and just assume that there’s no need to check Hamming codes unless the subchannel parity fails. EC8 allows full Hamming code checks on 32bits of data and presumably ChipKill on 64bits.
It’s widely claimed that all DDR5 RDIMMs are EC8 and all DDR5 ECC UDIMMs are EC4. A quick search on ebay turned up adverts for EC4 and EC8 RDIMMs and links to apparently reliable sites confirming that some of the RDIMMs are EC4. There are reports of EC8 UDIMMs even though I couldn’t find any advertised. This seems to mirror the situation with DDR4 where non-ECC RDIMMs are apparently available somewhere and ECC UDIMMs are something I’ve used a few times but most people have never seen.
I then searched for information on what servers support. The Dell R760 server supports both EC4 and EC8 RDIMMs but you can’t have both in the same system.
The existence of EC4 DIMMs is wrong. They shouldn’t make substandard gear, the manufacturing price difference between 72 and 80 bit wide DIMMs isn’t going to be great and the end result is some systems with inadequate specs and extra difficulty in upgrading systems with more things to check for compatibility.
Some years ago I reported a BTRFS corruption issue on my desktop PC to the BTRFS developers and one of them stated that the corruption in question didn’t match any pattern expected from a BTRFS bug and recommended that I run Memtest86+. The memory test revealed that I was getting about one memory corruption per 5 hours so if I had used Firefox on that system any crashes probably wouldn’t have been regarded as hardware errors with RAM. Those errors caused filesystem corruption and some data loss, if I hadn’t been using BTRFS that could have gone unnoticed for years.
On another occasion I had a VM I was using for testing software I was developing that had some unexpected errors. After working on it for a day I had shared the errors with a mailing list of other developers who also spent some time investigating it. Eventually I began to suspect a hardware problem, I went on site and when I rebooted the system to run Memtest86+ it didn’t even boot as it had errors that stopped the BIOS from even working correctly. It was strange that the system was apparently working correctly and restarting the KVM VM resulted in the same errors happening in the same code and nothing else on the VM apparently having a problem. It turned out that the system had a motherboard problem that made all but one of the DIMM sockets unusable so I ended up sending it to e-waste. That wasted a day of my time and some hours of other people’s time. Presumably on other occasions developer time is wasted due to hardware errors and no-one even realises.
What Society Needs
We need ECC RAM to be more widely used. Ideally we would have some government action to force this given the ongoing cost to society in corrupted data and lost time due to RAM hardware errors. I think that at minimum we need sufficient taxes on non-ECC RAM (and EC4 RAM for DDR5) to make it more expensive when bought new than ECC RAM.
We need to have greater knowledge of the benefits of ECC RAM among computer experts, people need to recommend that computers be purchased with ECC RAM whenever possible and that systems which can’t have ECC RAM (laptops and phones) shouldn’t be used for storing important data.
We need to avoid silly things like having so many variants of RAM to confuse people and make it needlessly difficult to get ECC RAM working.
Increasingly I am being told to “use a security harness” when analyzing code for potential vulnerabilities, but what is a “harness” and how does it differ from just running Claude Code and asking it nicely to find me some sweet vulns?
This post is literally my notes on reading up on this topic via a series of Cloudflare blog posts. That is, this post is a summary and does not intend to provide anything you cannot find anywhere else (with a lot more words used).
This Cloudflare blog post has a good introduction to the main ideas — that coding agents are tuned for a single thread of work at a time while supervised by a human. That is, they are trained not to take tangents, or hold multiple theories at once. In a general coding session an agent will interact with a relatively small part of a code base, not systematically scan it for all potential vulnerabilities. A harness will instead gather theories as it encounters them, record them in a database, and then investigate them all in parallel. Its a funny coincidence that such a process eats a lot of tokens right?
The follow-up Cloudflare blog post then builds on this idea with further justification for why coding agents aren’t the answer — they clearly received some push back on that idea. Specifically, they argue that sub-agents are useful, but don’t scale to where you need them to for a holistic review of a code base. They argue that sub-agents share a context window but that is simply not true with Claude Code, so I am unsure where that idea is coming from. They are right however that persistence, de-duplication, resumability, and dependency tracing at scale are all lacking for coding agents. Basically this sort of compute intensive security analysis is an orchestration problem, not a development problem.
keep the scope of a given investigation narrow — more “I think there’s an issue with image format confusion attacks” not “read all the qemu code and find me sweet vulns kthx”.
have the harness apply adversarial review to its findings — that is, ask it to disprove what it thinks it found. If the finding survives, then its more likely to be real. Its even better if that second review is done by a different agent or model with a different prompt.
splitting the vulnerability across different agents can work well.
parallel tasks are better than one exhaustive agent — then have a later phase de-duplicate the findings.
Do not build to a specific model. The models are evolving too quickly, and models are taken offline as the resources that host them are repurposed to host their successors. Treat models as interchangeable components.
Similarly, using a different model for validation than was used for discovery continues to be an important technique, especially as a single model will “tend to look at code paths through the exact same lens”.
Ensure you’re looking at the entire ecosystem you code runs in, not just the code base of the application.
Start by building “skills” (the summaries for how to perform an action that many LLMs can ingest).
Cloudflare found they needed to address three main problems when building their harness:
Context management — solved with external state management in a database.
Persistence and crash recovery.
Cross repository reasoning.
They also implemented two separate stages, noting the earlier recommendation that each stage use a different LLM model:
Vulnerability discovery, which they call a Vulnerability Discovery Harness (VDH).
Vulnerability validation, which they call a Vulnerability Validation System (VVS).
One interesting idea is that instead of providing a lot of static analysis tools to the models, they instead provided a wish list function where the agents could record their desire to use a tool, and then re-run work when that tool becomes available. This was at least partially motivated by having put a lot of work into deploying semgrep, for the models to then never actually execute it.
One interesting quote from along the way:
“More than one team we have spoken with is now operating under a two-hour SLA from CVE release to patch in production… Faster is not going to be enough, and we think a lot of teams are about to spend a lot of time, effort, and money learning that the hard way.” — Cloudflare
Tune in next time to watch me try to find a security harness I can actually run using a leading frontier cyber model… or Anthropic Opus.
I have had the good luck and privilege to have spent the last 18 months working with the UNDP Regional Innovation and Digital team (Bangkok) on a variety of digital transformation and reform agendas across South Asia and the Pacific. It has been an extraordinary learning experience, and I was also able to help make an impact in several programs. I’m thankful to Alex and Aafreen for taking me on, to Sriganesh and Giulio for wonderful collaboration, and to all the UNDP Country Offices I got to work with in Fiji, Palau, Malaysia, Bangladesh, Nepal, Bhutan and Sri Lanka. I also had the privilege of meeting and working with some extraordinary civil servants and political leaders from across the region, many with ambitious and truly transformative agendas. I am still particularly excited about the “AI Nation� work underway in Malaysia and the Gelephu Mindfulness City in Bhutan, both of which are national agendas that have the promise and ambition of economic and societal transformation.
I was involved in several missions in which I provided analysis, skills transference (life journeys, future states, agile delivery models, data, tech, AI, etc), a range of strategic workshops, recommendations, program support and advice on digital transformation initiatives, just to name a few. While most of the materials developed are internal to UNDP, I thought it would be nice to share (with permission) some resources and toolkits we built as repeatable frameworks, for others to benefit from. Enjoy!
Resource
Intended outcome
The “Digital Transformation Archetypes� has four distinct and complementary outcomes governments seek when investing in “digital� agendas, each with clear aspirations, requisite capabilities, infrastructure, strategic considerations and program enablers.
Greater clarity in early discussions about government objectives and aspirations with digital investments, better planning and programming to achieve clear objectives, prioritisation of the platforms and capabilities required and a shared view of the future state.
I had the opportunity to advise on DPI initiatives in the region, which led to publishing a modern take on DPI, one that enables whole of nation uplift and outcomes, including some considerations for what is needed to address the promise and threats of AI.
To help governments plan beyond the limited (and limiting) idea that DPI is just digital identity, payments and data exchanges. I have seen initiatives promise all the benefits of digital transformation from just these platforms, which is misleading at best.
The AI Activate:Mitigate strategic primer (unbranded) is a resource to support governments in national AI policy, planning and national ambition setting. It includes strategic guidance on how to activate the benefits of AI at a national cross-sector level, while simultaneously managing national threats from misuse by bad actors.
Most AI guidance focuses on how to responsibly manage a particular instance of AI in a product, team or organisation. Few tend to look at national implications, so this resource was developed to support holistic national planning that both enables responsible adoption while actively mitigating harmful misuse.
A short paper that explains the difference between Service Design and Customer Experience, borrowed from a similar paper done by ESDC (Canada)
To help differentiate the two capabilities and demonstrate why both are needed, and they are complementary, not in competition.
The Civil Service LOOP Authorising Environment Assessment assesses the legal, operational, oversight and public authorities delegated to and exercised by civil servants and the civil service. Contact RID for more.
To understand the actual delegations held by the civil service and ensure there is sufficient decision making authority to be effective, impactful, humane and to sustain digital transformation after project closure.
An “digital pipeline accelerator model� for UNDP to support digital projects across the region, designed to bring human-centred and agile delivery methods and practices into the human development projects lifecycle. Please contact the RID team for more.
To de-risk and validate solution definition early and often, improve the speed and effectiveness of delivery through usability and adoption, and result in sustainable and ongoing digital delivery capabilities within relevant civil service Ministries.
Below is a useful poster I created to help explain how to operationalise great service delivery in government
Service design for public sectors
And here is an “AI for the policy journey datavis I made to help policymakers.
AI for the policy lifecycle
We also created briefing packs on one stop shops, on citizen outcomes from digital transformation, data, responsible use of AI in government, and loads of reviews and specific advice for the jurisdictions we worked with. For more, please get in touch with Alex Oprunenco and the RID team in Bangkok, who continue to do inspiring and impactful work across the region!
Next steps
While I greatly appreciated my time with the RID team at UNDP, and am thankful for all the lessons and opportunities to contribute to government reform and digital transformation efforts across the region, I knew I would always return to public service. Why? Because that is still the place where, for all the challenges and stress, I know I can have the greatest impact on the lives of people. When public institutions do well, everyone benefits. When they fail, everyone suffers (eventually). So I was thinking carefully about where I could contribute. My family and I recently moved to Darwin for a change in lifestyle, with a little encouragement I wanted to contribute to the community I am living in, so I am delighted to say I will be joining the NT Government in a senior executive capacity, as the General Manager for Corporate and Shared Services at the Department of Children and Families. I know it will be a difficult portfolio with significant challenges, but I am hopeful I can do my part to help some of the most vulnerable members of our community to thrive. I’m joining a team of people who are passionate and dedicated to building stronger families and communities, and I look forward to bringing my skills, experience and energy to the mission.
Ran into unknown state (hex char: 0) at /tmp/test.pl line 8.
The errors are of the above form which Google didn’t find before now so obviously isn’t a common situation, below is my test program.
#!/usr/bin/perl
use strict;
use Proc::ProcessTable;
my $process_table = new Proc::ProcessTable('cache_ttys' => 0 );
foreach my $process ( @{$process_table->table} )
{
print $process->fname . "\n";
}
Here is the relevant part of strace output:
newfstatat(AT_FDCWD, "/proc/2", 0x7fff19533c10, 0) = -1 EACCES (Permission denied)
openat(AT_FDCWD, "/proc/2/stat", O_RDONLY) = -1 EACCES (Permission denied)
access("/proc/2", F_OK) = 0
write(2, "Ran into unknown state (hex char: 0) at /tmp/test.pl line 8.\n", 61) = 61
Below is the apt sources.list line for my personal repository which has a version of the package with this fix. The gpg key is in the etbe-base package in that repository and the source is all there. To access it without apt use this web page [2].
deb [signed-by=/usr/share/keyrings/etbe.gpg arch=amd64 ] https://www.coker.com.au trixie misc
I’ve also done some work on the ps.monitor script in etbe-mon that uses this Perl package and made it better handle program names longer than 15 characters. That improvement apparently only works on Linux, Darwin, and Cygwin. People who want things to work better on BSD etc could patch libproc-processtable-perl accordingly.
A few weeks ago I joined Jared to record a new episode of his Dead Code podcast, and now it’s out — go have a listen! Jared’s titles never disappoint, and I feel it’s only appropriate that “Bloom of the Undying” take the place of honour as the title for these weeknotes.
After all the effort to get Hanami 3.0 out the door, this week I’m having a break. I’ve travelled to Adelaide with my wife and kids to spend some time with my parents. It’s a rainy winter week here, but we’ve all been having a good time.
Last week I did poke some more at my custom Hanakai API docs site. While it still needs a bit of design finesse, all the basics are now in place, including cross-gem search! So I think I’ll be able to ship this. Give it a couple more weeks and I should hopefully have a preview to share.
Not much else from me on Hanakai since the release. But Paweł and Phil are making JRuby improvements, and Paweł is back onto work that will lead to a Dry CLI 2.0 release. Our team is great!
One thing I am doing is some of prep for our upcoming sponsorship drive. This was already delayed a bit by our 3.0 release and I don’t want to leave it too late. I have an idea, some willing participants, and some good news to share along the way. Looking forward to putting some energy into this!
The Chairman's Lounge Joe Aston Simon & Schuster Australia 2024 359
★★★★★
This is the story of the downfall of an Australian business hero, the destruction of an iconic Australian brand, and hubris. In a mere four years Alan Joyce when from hero status in Australia, to literally hiding out with his mother in Dublin while being hounded by the press. Truly his downfall was impressive.
However, I think it’s also another example of Welshian management ultimately failing, as seen with General Electric in The Man Who Broke Capitalism and Lights Out. This includes: publishing accounting results that while inline with the definition of the accounting standards appear to have redefined expenses in a manner convenient to management with little rationale provided; misleading customers on their refund rights at a time when those same customers were trapped at home suffering and Qantas was sitting on massive cash stockpiles; illegal union busting; and shedding large numbers of highly skilled staff which simply couldn’t be replaced in a timely manner when travel ramped back up again. That is, optimizing for this quarter’s numbers by completely ignoring the longer term impact of the decisions being made.
This quote from page 94 is particularly telling:
“Its always better to own and control your own facilities because it limits your risk when things change,” says the Australian and International Pilots Association president, Captain Tony Lucas. “The parallel I draw would be with [aircraft] maintenance. Qantas has no heavy maintenance capability for the A380 fleet in Australia so we’re beholden to maintenance facilities overseas.” Even by mid-2024, more than thirty months since the relaunch of Qantas International, “we’ve still only got six out of ten Qantas A380s flying, because we can’t get the other four through those [foreign facilities], which are fully booked”.
“When you lose control of your ability to produce things or to perform work that is fundamental to your business, that has downstream risks that I think people don’t tend to fully comprehend.”
The same is true for Qantas’ workforce in terms of qualified and current pilots, cabin crew, and licensed aircraft mechanics. These people don’t grow on trees, they take years to train and must be continually re-certified. Qantas just… stopped employing them, and now can’t source enough people for the work at hand.
The book makes a point on page 148 is another stand out moment for me:
Institutional investors are focused on index-beating returns for the companies they own. Quite inevitably, this causes them to be monomaniacally fixated on the share prices and capital returns of companies. But enslaving a company to the short-term propellants of its share price is rarely in the long-term interests of that company.
If we expect our investments to do better than the index, which is itself an average of the biggest companies in the market and therefore the ones the investors are mostly likely to own, aren’t we expecting every company to perform better than average? To a certain extent aren’t we expecting them to perform better than themselves given they are the ones the index is composed of. That seems like a mathematical failure that perhaps a well paid fund manager should be able to figure out?
This is also a story of a company in crisis — plummeting brand trust scores, accusations of unfair treatment of their most loyal customers, the failure to manage the age of the fleet and the availability of trained staff to operate that fleet, and yet somehow the entire senior management was fixated on whether this criticism reflected poorly on the CEO as a person instead of if it was true. Aston asserts this is an example of Dacher Keltner’s research that people in power suffer behavioral changes over time which make them incapable of seeing their own unethical actions, and “produce narratives of a exceptionalism about themselves because their high status requires moral justification” (page 209).
At the same time, not all of this is Joyce’s fault. This is also a story of regulatory capture and governments from both sides of politics failing to act in the best interests of the public, as well as of the media and financial analysts not bothering to verify the outlandish statements Joyce made to justify his actions. I have more sympathy here for the journalists than the others — they’ve had their staffing cut to the bone and it’s hard to do basic fact checking when you’re expected to smash out endless articles so no one notices you’re the only one left in the newsroom.
Overall this is a very readable book and I enjoyed it. It only once caused me to lie in bed thinking about corporate governance standards.
I went on a side quest a couple of weekends ago which seems like it might have ended up being a big win. That win likely applies to other people running both OpenStack, but also other cloud orchestration systems using libvirt like oVirt, Proxmox, Shaken Fist, and so forth.
By way of back story, I have a stack of patches which I maintain on top of OpenStack’s Kolla and Kolla-Ansible. Most of those patches continue to progress the new “spice-direct” console type in OpenStack Nova, but I also occasionally find little bugs or CI regressions along the way that I want to clean up. One example of such a bug was Kolla’s failure to setup virtlogd to provide instance console log rotation, which is currently being backported to various releases. Another one is the topic of this post.
warning : Client hit max requests limit 5. This may result in
keep-alive timeouts. Consider tuning the max_client_requests server
parameter
...
error : connection closed due to keepalive timeout
The libvirt daemon ships with max_workers=20 and max_client_requests=5. Those defaults suit a multi-tenant host serving many mutually distrustful clients, where the per-client request cap protects the daemon from any single client monopolizing it. Under Kolla-Ansible, nova-compute is effectively the sole privileged client of libvirtd, so the cap of 5 concurrent requests per client becomes the binding constraint rather than a safety net.
When several instances build at once — as they do during the tempest run of the upgrade jobs — nova-compute’s concurrent libvirt RPCs (instance defineXML() calls plus the resource-tracker periodic calls) exceed five. Further requests queue, the connection’s keepalive responses are starved, and after keepalive_interval (5s) x keepalive_count (5) = 25s libvirtd closes the connection. nova then sees “Cannot recv data: Input/output error” mid-defineXML(), the build is rescheduled, and once all hosts are exhausted the instance is left in ERROR. This presents as flaky upgrade-job failures.
You can see the original patch for this on gerrit, which links to the relevant backports as well. I must say I was impressed with how quickly the Kolla team engaged with the idea that there might be something to fix here and landed the patch series, especially the backports. I hope in return CI just that little bit less annoying now.
So there are two reasons I wanted to whip up this post — others should likely tune these parameters in libvirt — but also check out this super satisfying graph:
Hanami 3.0 is out! In this writer’s opinion, a release worthy of its new major version: new mailers, i18n, and Minitest, your apps becoming way faster, and much more!
I’m proud of this release. Eight months of continuous work. Two brand new gems. 100 pull requests authored by me, another 50 by our team and community. I feel we’re getting better and better with how we bring improvements and polish to Hanami and the Hanakai ecosystem.
In the days after, I pushedafew 3.0.1 releases with minor fixes. I also pushed the benchmark suite I used to determine the performance numbers for the 3.0 announcement.
Over the last weekend I’ve been at Ruby Retreat with 30+ Australian and Kiwi Rubyists. This was my first retreat in seven years, and it was a great time as always! I relished the chance to hang out in person with fellow Hanakai teammates Phil, Jojo and Ryan, plus several workmates and many #RubyFriends new and old. People and community is why I do this thing, and this was another welcome reminder.
I did a few Hanakai things at the retrat. I gave my What I Talk About when I Talk About Ruby talk (thank you to everyone who listened in!), worked on a custom API docs site that fits with our Hanakai look and feel, cleared the way for Ryan to bring his “Hanami for Rails developers” guides into our site, and got to check out some fixes and improvements from Ryan and Phil (simpler session key handling and a fewstandalone sliceimprovements).
This edition’s a bit late—please grant me an amnesty, as I don’t want to break my streak! So here we’ll focus on last week’s work, and in a few days’s time, I’ll bring you up to the present.
The focus last week was clearing the decks so we could make ship a 3.0 release candidate for Hanami.
Meeting opened at 20:03 AEDT by Neill and quorum was achieved.
Minutes taken by Jonathan
2. Log of correspondence
[Linux-aus] Media and communication suggestion (was: Re: Flounder Feb 2026 meeting report) – Jonathan has responded to Russell Coker’s suggestion about promoting Linux.
Missing MTA-STS Record for Domain linux.org.au – continuing to receive email enquiring about a bug bounty for notifying us of a lack of an MTA-STS record
Re: DrupalSouth Community Day 2025 – wrapping up accounts stuff – ongoing discussion about NZ GST for conferences run there.
From Brussels to the World: Open Source as a Global Asset – OSI newsletter
Involvement – loomhigh223555@gmail.com from the Perth Linux Users Group would like to get involved in media and comms [Neill to respond]
Remittance Advice – from RedBubble – $33.16 of sales
Fwd: Stripe webhook delivery issues for https://joomla.org.au – The Joomla subcommittee have responded (by disabling the webhook)
New subscription request to list Policies from phil@philfixit.com.au – [I don’t have the access to approves this – Neill to follow up with Joel]
You’re Invited: OPA Meeting on Voluntary Security Attestations – from OSI. Very short notice. The meeting has already been held.
Upcoming Domain Renewal Notice – Please Do Not Reply – for linux.com.au
REMINDER: OPA Meeting on Voluntary Security Attestations – see above
30 Day Renewal Reminder 2026-03-20 – for linux.com.au
EO2026 review document – internal EO email. I’m sure we’ll hear about it tonight.
PyCon AU 2026 update for 23 February 2026 – see below [note check with Jack before publishing minutes]
[LACTTE] Fwd: Auto-discard notification – Neill to check
Re: Invoices for DrupalSouth 2026 going LA-S account – Russell has responded to a query about transferring money the NZ account of Drupal South
Linux Australia Subcommittee meeting – query from Alexar as to whether there is a subcommittee meeting coming up and who checks the secretary@ address. Neill has responded.
3. Items for discussion
KiwiPyCon 8:05pm
No report. No 2026 conference so little to report at this stage.
Drupal Subcommittee 8:10pm
Joomla Subcommittee 8:15pm. Written report submitted by Nathan and discussed.
Budget status:
Initial budget for JoomlaDay Australia was shared to the Council email this evening. It’s very much in first draft form as we have the event subcommittee meeting tomorrow afternoon – let me know if any problems with the share.
Key achievements:
JoomlaDay venue narrowed down to two venues in the CBD, the most likely being Melbourne Town Hall but will have confirmation of that tomorrow.
New website close to completion, but launch looking like March now.
Membership system now live with 5 paid members after a very soft launch at the last meeting so we’ll be promoting in conjunction with the launch of the new website.
Small in the scheme of things but a couple of new attendees at the last User Group meeting as a result of improved communications.
Any concerns?
Not at this stage
How can LA assist?
Following tomorrow’s meeting we’ll do some work on filling in the expenses line item so would appreciate a review of that once complete, which is likely around Council’s next meeting.
Admin Team 8:20pm
No reportthis month – calendar invite not received.
PyConAu 8:25pm
No verbal report. Jack sent a written report through earlier this week.
CFP has been launched
Attended DDD Melbourne. Should drive interest in CFP and conference, but unlikely to convert to ticket sales any time soon.
CFP workshops scheduled – in person Sydney, Melbourne, Brisbane and Canberra plus two online.
Accepted into Python Software Foundations new “Community Partner” program
WordPress 8:30pm
No report this month.
Everything Open 8:35pm
Projected profit of a bit more than $35,000
Photos – Query about where these could be archived long term. Yes, on the LA mirror. Check with Steve about what might be best.
Streaming costs – Query about who pays the streaming costs: the conference or LA. Need to ask Joel for these details and finalise costs for the conference if applicable.
Flounder 8:35pm
No report this month.
LUV 8:35pm
Alexar is travelling and is unable to attend tonight. He expects to send us a report by the end of the month.
4. Items for noting
ANZ New Zealand: adding signatories
ANZ NZ have requested signatures from everyone on the manifest in order to add David and Christopher. The list on the manifest appears to be out of date.
Russell will ask ANZ NZ for more information since this appears to be a new procedure.
5. Other business
Grants program ready to roll, pending two details:
The sender address to use when posting applications to the linux-aus mailing list.
Subscribing that sender address to linux-aus.
In response to the point raised at the last Council meeting: during the last grants cycle the information about the program was made visible to everyone, even those not logged in as members.
LUV/Electron workshop emails
A LUV (Linux Victoria) AGM has been scheduled. Information about this is expected in Alexar’s report.
Detailed discussion of next steps deferred until Joel is back.
Council Face to face: council members to fill in the dates document:
Meeting opened at 20:06 AEDT by Joel and quorum was achieved.
Minutes taken by Neill
2. Log of correspondence
Preliminary budget report EO2026 – preliminary report from Arjen as the EO2026 treasurer
Proposed mailing list post to announce the grants program
Re: UCX – Invoices – discussion about payment of UCX (catering) invoices for EO2026
2026 OSI Elections Update – newsletter from OSI
You’ve Made A Sale – 77169079 (AU$9.54) – EO2026 redbubble sale
Name check for AGM – email from Triss Healy checking membership status. Neill has replied
You’ve Made A Sale – 77183275 (AU$12.26) – EO2026 redbubble sale
Fwd: [APNIC #6274725][LINUXAUS-AU] – APNIC Membership Renewal – Invoice Attached – notification from Steve Walsh that the bill for our APNIC membership has been entered into Xero. Russell has responded and the bill has been paid
Amazon Web Services Billing Statement Available [Account: 103334912252]
Fwd: DDD Melbourne 2026 Community Booth Application – notification from Sae Ra Germaine that LA did not get a community booth at DDD Melbourne this year. Joel and Jonathan have responded
Lodge Linux Australia Activity Statement October..December 2025 – Russell has requested that our accountant to lodge the Dec 2025 BAS. The BAS has been lodged and the invoice paid.
Four emails in camera
3. Items for discussion
Grants Program
The council is happy with Jonathan’s email. Jonathan will post it to the linux-aus and linux-announce mailing lists.
We need to check that information on how to apply for a grant is public, but the form should still require being logged in.
EO2027
We have not yet put out a call for bids. Arjen has expressed interest in running it (in Brisbane). Russell will contact universities to see if they are willing to host the conference.
To approve a bid we need a budget, a venue and a team.Sophie and the LUV drama – email from Russell Coker
Fwd: Email harvested for Electron workshop list without consent
Fwd: [Linux-aus] Electron Workshop spam – email forwarded because the original was held for moderation when sent to the linux-aud mailing list
Fwd: LUV Main Meeting (in-person and online) on Tuesday – email from Russell about Alexar continuing to send email
EO2027 – we should discuss Sae Ra’s concerns about EO2027. Perhaps we would need a co-director?
We can assist with taking an expression of interest to a full bid.
Joel suggests we send an email asking for an expression of interest for the next two years.
We need to make it clear to Arjen that his proposal has not yet been officially approved and still needs to go through the formal process. Ask him to update us on his current plans.
Votes by a non member at the AGM
One non member voted at the AGM. They mistakenly thought they were a member.
The votes did not affect the outcome of any of the motions.
To avoid this in future we should add a notice to the in person sign up sheets.
We have 11 months to make sure that this does not happen again.
Electron Workshop/LUV mailing lists
There’s been a lot of discussion on the mailing list.
We need to provide a response.
Joel will draft an email to Linux Victoria about the situation. They need to send an email from the current list explaining the situation.
Part of the problem is that while LUV is/was an LA subcommittee Linux Victoria/Electron Workshop is not.
LUV needs to hold votes on this process to change the name and retire the current list.
Also worth noting that only natural people can be members of Linux Australia.
As a first step the people who have asked to be removed from the mailing list should be removed.
Re: [Linux-aus] Resurrecting LA Press/Media team?
Media team exists, but is just one person. Previously has been a press part, rather than comms from council to membership.
We could consider this suggestion as part of our revisiting our general communications.
[Linux-aus] clarifying membership criteria
Joel has already responded to this. No further response to the mailing list should be required.
We will review the wording of Australia vs Australasia and consider whether we need to clarify anything.
[Linux-aus] some lists to remove
Joel has responded. No further action needs to be taken.
AGM minutes are being prepared (currently in draft)
The goal is for the secretary to share the draft with the rest of the council by next week.
4. Items for noting
5. Other business
We need to start planning for the face to face council meeting
Meeting opened at 20:05 AEDT by Joel and quorum was achieved.
Minutes taken by Neill
2. Log of correspondence
Carrying Open Collaboration into the Year Ahead – Newsletter from OSI
You’ve Made A Sale – 77030472 (AU$7.98) – RedBubble
Remittance Advice – RedBubble
Minutes accuracy 14 January 2026 – From Jack Skinner pointing out that the date on the published minutes were wrong. Neill has responded and corrected the error.
Upcoming Domain Renewal Notice – Please Do Not Reply – Notification from Digital Pacific re linux.com.au – no action required
Fw: Re: Linux Australia Council: Welcome! Details to add as a Council Member – details of our new council member Harrison Oates
[Linux-aus] Electron Workshop spam – email from Russell Coker to Linux Aus list re spam from Electron Workshop
Linux Australia 2026 Annual Report and Draft AGM Agenda – from council. Notification of the publication of the Annual Report and AGM agenda
60 Day Renewal Reminder 2026-03-20 – notification from Digital Pacific re linux.com.au – no action required
Kathy Reid – apology for AGM and proxy vote authorisation – Joel has responded
Email spoofing & SPF #2 – from George Moore. Two emails. First notifying us of a problem with our SPF and DMARC settings and the second asking about a bounty.
Missing MTA-STS Record for Domain linux.org.au – Another email from George Moore. This one about MTA-STS records.
List of Linux AU AGM attendees – from Wil Brown. List of online attendees of the AGM
List of Linux AU AGM attendees
You’ve Made A Sale – 77090059 (AU$6.14) – notification from RedBubble
Re: Linux Australia Returning Officer 2026 – response from Joel to an email from our returning officer Julien Goodwin [discussion about website?]
Welcome to the 2026 Linux Australia Council – from Joel to new and returning council members
Invitation: Linux Aus Council Meeting @ Wed, Jan 28 2026 20:00 AEDT – invitation to council members to our meetings
You’ve Made A Sale – 77092659 (AU$2.13) – notification from RedBubble
You’ve Made A Sale – 77100114 (AU$6.23) – notification from RedBubble
Re: Fwd: Re: LINUX AUSTRALIA INC – Everything Open 2026 conference sponsorship – FIN0271553 – Russell responds to a query from Arjen about ARBNs
Fwd: .au Licensing Rules Review: join us in-person or online and have your say – from Sae Ra re auDA licensing rules
You’ve Made A Sale – 77121219 (AU$1.91) – notification from RedBubble
Social media – congrats to new Council 2026 post now live – notification from Kathy Reid – Joel has responded
You’ve Made A Sale – 77131668 (AU$2.45) – notification from RedBubble
PyCon AU 2026 Update for 26 January 2026 – from Jack Skinner
Community & Educational request for Campfire Sydney, 200+ Teen Coders – from Joshua Yu
Re: DrupalSouth Community Day 2025 – wrapping up accounts stuff – discussion between Russell and Julia Topliss
Linux Australia Subcommittee Meetings 2026
Joomla Subcommittee Report – from Nathan Morrow
DS monthly report – January 2026 – from Julai Topliss
The LUV drama – from Russell Coker [in Camera?]
3. Items for discussion
KiwiPyCon 8:05pm
Minimal report. Just dealing with final finance details. PyNZ elections happening in a month.
Drupal Subcommittee 8:10pm
Now focusing on Drupal South Wellington.
Joomla Subcommittee 8:15pm
Subcommittee Name: Joomla Australia
Budget status (if applicable):
Budget for the November 2026 JoomlaDay in Melbourne currently being put together and will be shared at the next monthly meeting.
It will however be based very closely on the 2019 JoomlaDay run in Brisbane, which returned a small surplus.
Key achievements:
– New design completed and approved for Joomla Australia website
– New website currently under construction for launch in February with dedicated JoomlaDay Australia section.
– Membership system now live
Any concerns?
Not at this stage
How can LA assist?
Would certainly appreciate any suggestions around budget and assistance with socials advertising but will have a better idea once we’ve completed a draft budget
Admin Team 8:20pm
The change freeze for the election is now over. One change had to be made during the change freeze. Will now start with some upgrades and rebuilds that were held over.
Council will need to talk to the admin team about the website.
PyConAu 8:25pm
Recently:
We held a team lunch + working bee in Sydney. Mostly planning CFP but extensive discussion about communications, volunteering, and driving community & culture at the conference too.
We’ve had several large and returning sponsors enquire regarding 2026. At least one has indicated they only commit the quarter before – that means June for them.
We’ve (finally) contracted + invoiced our first sponsor after negotiations, with a second contract pending signatures.
Blind Bird tickets continue to sell regularly (especially thanks to promotion at EO last week). Expecting to sell out ahead of the 31 March deadline.
Some big upcoming milestones:
CFP will launch 1 February and run through to 29 March, with new and returning formats.
We’ve accepted up to 6 specialist tracks (up from regularly 3-4 tracks). Partly enabled due to venue and schedule flexibility. Tracks are tentative, subject to securing sufficient quality talk submissions and committing a second track organiser to each track. Tracks in 2026 will be:
Cybersecurity
Data & AI
Developer Relations
Education
Platform Engineering
Research Software Engineering
We’re hosting talk writing workshops in Sydney, Brisbane and 2x online. Tentative interest from CBR, and we’re keen to run in PER + MEL. Ultimately we’re hoping for 7x 60min workshops in 7 weeks to actively promote and support to first time speakers and new audiences. Workshops will be open sourced ‘workshop in a box’ with a ‘train the trainer’ model based on Sae Ra Germaine’s initial work for EO’s previous CFPs.
We’re in the midst of finalising plans to bring back our academic publishing pilot from 2024; with a light-er-weight process and outcome. We’re hoping this unlocks academics and researchers to submit, publish and then pay for tickets.
Please expect approximately 8 weeks of impassioned “Hello council please promote our CFP early and often” =D
Discussion items proposed for Wednesdays council meeting:
For Russell: We’ve been early-invoiced for our venue deposits in May, June and July. There’s a chance we’ll be able to pay from our own proceeds for some of these! We’d prefer to pay from our account regardless though and will request based on cashflow in the week/s ahead of 26 May.
For Council: How are we best placed to liaise with LA communication for amplifying CFP? Direct to Kathy or via other means? While we intend to have always-on social, we’ll have a few choice priority posts we’d love amplified if we can coordinate.
WordPress 8:30pm
WordPress Sydney continues online meetups in 2026, while looking for a physical venue.
WordPress Sunshine Coast continues to meetup in person in 2026.
All other meetups are paused while looking for new volunteer leaders.
There was minimal interest in the call for creating a WordCamp Brisbane 2026 org team. Unlikely to go ahead this year. May consider interest for 2027.
Everything Open 8:35pm
The conference was run. It was successful.
The budget position seems to be good. There were around 275 attendees. The final budget report will be supplied at the next meeting.
Flounder 8:35pm
No noteworthy change since the last report. Matrix rooms are going well and have lots of interesting discussions. In December we didn’t have interest in video meetings due to all the holiday stuff and we decided to wait until after EO2026 to try and arrange more, I have just started the discussion for that.
LUV 8:35pm
Alexar: Townhalls in East Gippsland in February
Did an install fest after EO.
Aiming to do an in person meeting every quarter. With a topic and speaker.
Looking to cover Linux and Games and Linux and AI topics
Will hold a LUV BBQ on Saturday 31 January
4. Items for noting
Community & Educational request for Campfire Sydney, 200+ Teen Coders – from Joshua Yu
Asking if Linux Australia would like to be involved in this event. We would need more information, particularly how they are open source related.
Can we find anyone to assist as volunteers at this event?
We need to update the website and clean up our mailing lists
In particular the information about elections and the AGM is out of date
5. Other business
Formal vote on the budget for the upcoming year
The budget should be uncontroversial, but the suggested face to face meeting is not currently included.
The face to face would probably cost around $1,000 per person.
There are definitely funds available to pay for a face to face, and they can be very productive. Someone will need to prepare a program.
Motion: That we accept the budget as presented at the AGM with the addition of $12,000 for an LA council face to face meeting.
Proposed by: Joel Addison
Seconded by: Elena Williams
Motion passed.
Grants Program
Jonathan will announce the opening of the grants program on both the linux-aus and sponsorship mailing lists soon.
The first step is to draft the announcement.
This year’s grant program will close on 15 Nov 2026. The program will open as soon as we can agree on the announcement text.
Should LA still be using X as a social media platform?
Motion: That Linux Australia suspends its X account and removes all references to it from our website and other documents.
Moved: Joel Addison
Seconded by: Everyone!
Motion passed unanimously
6. In camera
One item was discussed in camera
7. Action items
secretary@linux.org.auContact Joshua Yu to request more information on the Campfire Sydney event
The Jfrog people recommend “unshare -Urn” but I gave the Bubblewrap command as an option as it should work equally well and in some situations may be permitted when unshare isn’t.
The next step to exploiting it is to use the ip command to set the links up, below is what happens in a user session on a SE Linux system with user_t as the login domain:
# ip link set lo up
RTNETLINK answers: Operation not permitted
That will give an entry in /var/log/audit/audit.log like the following:
Unlike previous exploits like Pintheft [2] this doesn’t require any really uncommon access to the kernel (unless you consider setting up IPSec to be really uncommon) and is allowed in many container setups.
It seems that SE Linux configured in the strict mode prevents this exploit in the most obvious use case. But with the range of container related domains that are granted such access it seems quite likely that some configurations and use cases will permit it.
Overall the protection that the standard policy for SE Linux can offer (in a non-default configuration) against net_admin access isn’t bad, but isn’t very good either.
I think this will be the first of many exploits based on cap_userns access and that we need to do some work in tightening the SE Linux access controls on such things. One possible way of doing this is to have a program run inside a container in a domain that has permissions such as net_admin to setup the container and not allow domain transitions from the regular programs run in the container (the actual work) to the domain used for network setup.
The increasing use of containers by applications is only going to make this problem worse. I think that what we need is something like Flatpak for the vast majority of desktop/phone applications with a container setup program that works with apps packaged in the distribution packaging method (not from Flathub). This is something I’m going to investigate for future blog posts.
Recently, I had noticed that when I add an attachment (e.g. to email, via a web browser), GNOME's GTK file picker was only providing a list from recently opened items. Previously, it provided a PATH selection, which was a lot more useful for me. When the file picker opens, normally, there is a left-hand sidebar containing items like "Home", "Documents", "Downloads", etc. A normal workaround if this isn't available is to select Ctrl+L to open a location-based entry box, but this wasn't available either. The following question arises: How do I revert to the previous PATH-based menu? What changed, and why?
The first step to check the version of the operating system, desktop environment, and version of GNOME:
There are reasons why I'm using a 2022 LTS version of Ubuntu, but that's for another post; what's important is that this version of Ubuntu and the version of GNOME provided a clue toward what happened.
The next step was to search in the gsettings for the file picker's "recent" choice, and that confirmed what was being experienced:
GNOME 42 uses a mix of GTK3, and GTK4 plus xdg-desktop-portal, and many applications now use the GTK4 file chooser, which starts in the "Recent" view. Many developers (including GNOME developers) are increasingly adopting the "Recent" view and document-centric workflows over traditional filesystem navigation. This a terrible idea, albeit very common in a brain-dead Sharepoint-style mentality where the implicit knowledge gained by showing the filesystem and PATH is removed from the user. It will make users increasingly ignorant of computer systems, and it will make it harder for those who want to use the system to their advantage. The only people it benefits are the wilfully ignorant. Remember: Stupid is wrong and must be defeated.
The first suspect was that a GTK4 package or Flatpak update changed the setting. Another test resulted in some interesting answers, which added to this suspicion:
$ gsettings get org.gtk.gtk4.Settings.FileChooser startup-mode
'cwd'
$ gsettings range org.gtk.gtk4.Settings.FileChooser startup-mode
enum
'recent'
'cwd'
$ gsettings describe org.gtk.gtk4.Settings.FileChooser startup-mode
Either "recent" or "cwd"; controls whether the file chooser starts up showing the list of recently-used files, or the contents of the current working directory.
To fix this bug, change gsettings to 'current working directory' and verify:
$ gsettings set org.gtk.gtk4.Settings.FileChooser startup-mode 'cwd'
$ gsettings get org.gtk.gtk4.Settings.FileChooser startup-mode
'cwd'
Whilst that's fixed the problem, the question still remains of what caused it in the first place?
So yeah, I was caught up in the Meta/Facebook layoffs in March 2026.
There are a lot of parallels to the 2001 dot com bust, and I'd like to just briefly touch on one of them now.
There's been a lot of layoffs over the last year or three in tech. I think the tech market has seen what, more than 100,000 in the last year alone? And most of those aren't due to performance. There are a lot of very smart people who've spent quite a few years learning how to build, debug and maintain all kinds of interesting stuff.
And they're now in the marketplace.
When this happened in 2000/2001, you had a whole lot of people who learned how to build internet tech and infrastructure at companies that were pushing the boundaries with things. And they were let go, due to downturns, change of focus, all kinds of reasons.
A lot of those people went off to eventually build the new stuff that likely overtook a lot of those internet and telco companies in the 90s.
I think this is going to happen with the layoffs from Meta/Facebook and other technology companies. Meta ran (runs?) a huge research arm in Reality Labs pushing the boundaries in AR, XR, wearable/portable technology. There have been plenty of public technology demonstrations showing all the stuff going on before the current AI trend.
Just over in Reality Labs - people learned how to build stuff from ASIC design up through optics, display, camera technology, highly miniaturized electronic design and power, all the fun stuff around 2D/3D audio and video stuff on wearable glasses (how do you provide head and world locked surfaces to your applications and not have it be so laggy that it gives people headaches?), making it all work over wifi, and then .. well imagine the lessons learned in what can and can't work in manufacturing the devices and where the pain points are in current technology. (And yes, a lot more I can't talk about, for hopefully obvious reasons.)
That knowledge is now embedded in a few hundred people, soon to be a few thousand people, who are being laid off. And that's just reality labs - the other people spread throughout the company and other technology companies have gathered a lot of experience about how to make and grow technology "stuff", what works and what doesn't.
At some point some of those people are going to make startups that do really amazing things. The technology underpinning a lot of what people have been trying to make now will get better (and I will argue that right now it is good enough - if you're willing to shift your focuses a little) and things will appear that will knock the socks off the current offerings. They're not what you would view as "founders" in the bay area tech scene. They're the people who know how to make things work, not necessarily the people who got rich early on in the scene.
Just like what happened after the dot com bust of 2001.
I've heard from a few people now that those they're hiring from Meta and other large technology companies are top notch and know what they're doing. You can't spend 10 years at a company that heavily invested in cutting edge R&D and not learn a thing or two.
I think its their loss, and .. eventually, everyone elses gain.
A fairly balanced biography of the 6 astronauts. Covering before and during the Astronaut careers and to an extent afterwards. Worth a read for space fans. 4/5
A while ago, CommBank started asking for MFA confirmation on its mobile app for every NetBank login on a browser. Previously, there was an option to use SMS for MFA, which isn’t as secure as I would like, but it was at least usable. Since I’m switching away from Android to Mobian and won’t be able to use the CommBank app for much longer, I applied for a physical NetCode token.
The hardware is made by Digipass and looks disposable. It is a small, battery powered gadget with a screen and a button. When pressed, it shows a temporary NetCode for authentication. Such a NetCode is required both for NetBank logins and approving online transactions.
The letter that came with it has the wrong link for activation, the correct link is under NetBank -> Settings -> NetCode (under the Security section)
To apply for a physical token, call the NetBank team, mention you can’t use the app and need a physical NetCode token, and make sure they actually submit your request for a token. It took me 2 calls to get them to ship me a token. The hardware is free of charge but can only be applied for via phone call; unfortunately staff members at my local branch are unable to do anything in relation to NetBank. I was told privately by a CommBank employee that they are deprecating the hardware token in favor of the mobile app, I hope that won’t happen anytime soon, or that they add support for passkeys before they do. The last time I checked, the CommBank app was LineageOS-friendly, but I don’t want to configure WayDroid just to do online banking.
PayID, the thing that allows you to receive payment via a phone number or email address, is not compatible with the hardware token, and existing PayID will be silently deactivated if you use hardware token. This looks to be an artificial restriction; I don’t see why it has to be this way.
Regular CommBank mobile app sessions will also be de-activated once the hardware token is activated (I was told so but my sessions weren’t deactivated until I wiped my Android phone), and you won’t be able to sign into mobile app again until you manually disable the NetCode token.
Online banking has been getting progressively more invasive and anti-user over the last decade, from demanding remote attestation to requiring real time location data, each time locking certain features when those demands are not satisfied; all based on the flawed assumptions that everyone owns a phone running a certain flavor of iOS or Android, and has it ready all the time. I’m not sure what can be done to reverse this trend, but on the personal level I will use NetBank less and go back to cash.
Andrew Pam gave a summary of Linux gaming developments including ways to run Epic games, Wine, and a side note about Framework laptops.
Phil Steel-Wilson gave the featured presentation for the meeting which was on Fail2ban. The talk was interesting and informative and sparked discussions about DOS attacks and the ways that hostile activity is changing on the Internet particularly in regard to “AI” systems.
Wuxi is home to China's National Supercomputing Centre and the Sunway TaihuLight supercomputer. This system came to global attention in June 2016, when it topped the global Top500 list of the world's most powerful supercomputers, far surpassing the second system (also Chinese, the Tianhe-2A) let alone the third (Titan, from the United States). Not only that, Sunway TaihuLight held the top position for an unprecedented and never-repeated two years in succession. until the US system, Summit, hosted at Oak Ridge National Laboratory, took the top position in the June 2018 metrics. Nevertheless, almost ten years later, Sunway TaihuLight has remained not only a Top500 supercomputer, but remains at in the top 25 systems (placed #24 in November 2025) without any change to the original configuration in all that time, a blunt indication of how advanced it was at the time.
The Sunway TaihuLight consists of 10,649,600 cores and a Rmax of 93.01 petaflops and an Rpeak of 125.44 petaflops. With various import restrictions in place (those who preach free trade don't like practising it with a competitor), the processors are a home-grown variety, Sunway SW26010 260C, a 64-bit RISC running at 1.45GHz. The clock rate might seem low, but it matches the requirements of a manycore processor and, as the manufacturer code suggests, the Sunway SW26010 consists of a truly impressive 260 cores per processor, arranged as four clusters of 64 Compute-Processing Elements (CPEs) in an eight-by-eight array. These CPEs support SIMD instructions, making the chip (at a very high level) seem like something between a traditional CPU and a GPU architecture. The CPE clusters also have a more conventional general-purpose core, the Management Processing Element (MPE), that provides supervisory functions. As each node has 260 cores, there are "supernodes" of 256 nodes, and each cabinet holds 4 supernodes. There are 40 cabinets in total, providing over 10 million cores. Sunway has its own interconnect, with a five-level integrated hierarchy: (i) computing node, (ii) computing board, (iii) super-nodes, (iv) cabinet, and (v) complete system with a network link bandwidth of 16GB/s and total I/O bandwidth of 288 GB/s.
The operating system is also custom-built, Sunway Raise OS, based on Linux. Common compilers (C, C++, Fortran), an automatic vectorisation tool, basic math libraries, and a customised version of OpenACC are available. The software build system is also specialised, targetting the Sunway processor. Whilst minimal modifications have been sought, those applications designed for GPUs have been "significantly more challenging". Nevertheless, dozens of applications have been written which can, in theory, scale to use the entire system, with early tests of atmospheric simulations scaling effectively to eight million cores. Other early simulations of note include atomistic simulations of silicon nanowires and ultra-high-resolution global ocean surface wave numerical simulations. Parallel software compilation at the node level generally uses MPI. For the four CGs within the same processor, software can use either MPI or OpenMP, but within each CG, Sunway OpenACC is used. Sunway OpenACC uses the OpenACC 2.0 syntax but targets the CPE clusters and includes parallel task management, heterogeneous code extraction, and data transfer descriptions. Syntax extensions from the original OpenACC 2.0 standard include finer control over multi-dimensional array buffering, and packing distributed variables for data transfer.
The Sunway TaihuLight will be remembered alongside other systems that are "giants" in history for their performance, architecture, and lasting impact, and contributions to science, such as ENIAC, UNIVAC, CDC-6600, Cray-1, Beowulf, and RoadRunner. A system as powerful, innovative, and novel as this comes along perhaps once a decade, and after 10 years of operation, Sunway TaihuLight has earned its place in computing history. All the engineers and administrators who have built, operated, and maintained this system deserve respect for their contributions. What is especially remarkable is that, due to the political climate, this system had an additional requirement for novel design. However, I have been informed by a trustworthy source to "watch this space"; there are plans for a system ten times as powerful in the very near future.
A few weeks ago, I had the opportunity to visit Guizhou, China's National Big Data Comprehensive Pilot Zone. At first blush, the choice of Guizhou seems to be an unusual one. With a population of 38 million, it ranks 17th in the list of administrative divisions and 18th in population density, and it is even further behind in terms of GDP (22nd). From the principle that it is most efficient to conduct compute near where data is located, one would expect that such a data centre would be located in provinces with a greater population and economic activity, such as Guangdong, Jiangsu, or Shandong, or maybe even in accord to scientific output, which would also include Beijing and Shanghai. Instead, Guizhou, with its rugged karst formations and dense forests and lower level of economic development (fourth lowest in GDP per capita in 2020), has been part of a "Big Data Guizhou" strategic plan launched in 2014 which includes a threefold approach; "Big Data", "Big Poverty Reduction", and "Big Ecology" by then governer, Chen Min'er.
With low energy costs and a consistently cool climate, Guizhou has established the Guizhou Cloud, sponsored by the Guizhou Big Data Development Administration and supervised by the Board of Supervisors of Guizhou State-Owned Enterprises. This in turn has attracted major national corporations to its numerous data centers, notably Apple's iCloud China and Huawei's Cloud Service Base, along with Tencent, Alibaba Cloud, the AI firm SenseTime, as well as hosting the annual China International Big Data Industry Expo since 2015. These corporate decisions are notable enough in their own right, but what really makes Guizhou such an attractive place for a national data hub is the presence of the Five-hundred-meter Aperture Spherical Telescope (FAST) which, as is evident from the name, has a 500m diameter dish (I call it a "wok") making it the world's largest single-dish telescope.
Radio telescopes are essentially antennas and receivers for radio waves, with frequencies ranging from around 20 kHz to around 300 GHz, just as an optical telescope collects data from the visible portion of the spectrum. Primary local sources for radio waves include the Sun, Jupiter (due to its magnetosphere), and Jupiter's moon, Ganymede. The Galactic Centre of the Milky Way is an especially powerful source, as are supernova remnants, such as Cassiopeia, and neutron stars, such as pulsars and Rotating Radio Transients (RRATs). Primordial black holes and extraterrestrial intelligence communications are two other speculative, currently unobserved sources. The main point is that to derive information about these radio sources, one needs to collect radio wave data, and the more data you collect, the greater the chance you will find something interesting. Thus, to collect more data, one wants a larger receiver.
FAST is a very big receiver and it collects a lot of data, roughly 100TB per day. Construction began in 2011, testing began in 2016, and it was fully operational in 2020. Even before becoming operational it discovered two pulsars and by 2021 it has discovered an incredible 500. Hardware innovations are continuing; late last year, China Environment for Network Innovation (CENI), announced that they had conducted a (somewhat contrived) data transfer test of 72TB between FAST to Huazhong University of Science and Technology in Central China's Hubei province. The data transfer test, which would normally take 699 days was completed in a mere 1.6 hours. Further, China has announced that it will build an additional 24 radio dishes of 40m diameter around FAST, creating an array that will mimic a massive 10km diameter dish, and boost telescope resolution by 30 times.
Mention must also be made of the rest of the Tianyan Scenic Area, which hosts the FAST system. Apart from the stunning natural beauty of the region, and the FAST Observation Platform (complete with bungy jump during holiday weeks), the site also hosts an impressive Astronomy Experience Hall, the Astronomical Space-Time Tower (at 99.999 metres), the Nan Rendong Memorial Hall (the astronomer who was the main drive for setting up FAST), the Dome Flight Cinema, and a Aerospace Science and Technology Museum. Like many massive engineering projects in China, they have also turned the site into an informative destination for national and international visitors.
Ever since people looked at the stars, they have given bright stars (and groups of stars) names. In the western world a lot of those names are arabic names that have been around for millennia. In science, stars are generally referred to by a Bayer Designation (a greek letter and the constellation name) or a catalog number.
About a decade ago, the International Astronomical Union, which is the organisation that can assign official names to things in the sky - stars, planets, asteroids, comets - adopted the most common classical star names, but then decided that the people from the middle east and the mediterrenean were not in fact the only ones to ever observe the stars. So via its Working Group on Star Names they assigned new names from various indigenous and non-english languages around the world.
Four of these previously unnamed stars got official names from Australian Indigenous languages.
Larawag (Epsilon Scorpii), Wurren (Zeta Phoenicis) and Ginan (Epsilon Crucis) got names from the Wardaman language of the Northern Territory and Unurgunite (Sigma Canis Majoris) got a name from the Boorong people of the local area where I live and do my astrophotography. Each star has its own stories associated with it and you can read about those on aboriginalastronomy.com.au.
A friend is a member of the IAU working group on star names, as and he told me about these newly assigned names some years ago, I decided I was going to try a nice image of each of them, taking into account the details of the story when possible. That is especially important with Unurgunite :-)
I finally got the last one mid last year, and then processed all the data in the same way.
For each star, I took an hour of data; 60 x 60 second exposures with a UV/IR cut filter on a 300mm focal length RedCat 61 and processed it the same way using Siril. This provides reasonably correct star colours and relative brightnesses.
This presentation covers the science of Earth's "energy budget" of heat inputs and losses, and describes the overall climate system. It continues with a description of the Industrial Age, the introduction of direct temperature measurement, and the resulting temperature rise from burning fossil fuels. This is followed by a description of how Greenhouse Gases operate on a molecular level, the increase since the pre-industrial period, and the carbon cycle. After this, human activity and projections are considered, followed by changes to species' habitats and the possibility of an Anthropocene Extinction Event, then energy trajectories and future global policy directions. Concluding remarks identify climate change as a critical issue and one subject to "race conditions", and note that the policy route, whilst necessary, is currently falling short of requirements.
This was a presentation to Future Day 2026, March 2-4. A transcript is provided along with the accompanying slide deck.
This happened circa what, 2008? 2007? I forget now. Anyway, it was a while ago now - and it wasn't my fault - but at the time it was pretty "wtf oh shit I'm in so much trouble" scary levels of scary.
So here we go.
Around that time I was running a little consulting / hosting company. I went into the data centre which hosted my equipment to install a second hand Dell I had acquired and tested. I plugged it into the rack, then plugged in the power, then pushed the on button.
Then bang. Then everything went dark. Then bang again.
Then I get a phone call on the VOIP phone in the data centre. It was their owners, asking me what the fuck I had done.
Anyway, it turned out that everything was dead. It wasn't just that the circuit breakers had tripped. A large part of their power equipment in the DC had also gone.
So yes, I was blamed for taking out a whole data centre. By plugging in one Dell server.
But why was I not in court over it? Why am I not still paying back the damages? Well, it turns out there's way, way more to the story.
First up they added a new rule - "You need to test equipment at this outlet/breaker before you install it." Cool, my server definitely passed that test. It worked just fine.
But then it turns out that although my rack was perfectly under the rated current limits, the other racks were not. Like, in any meaningful way. There were some other customers way, way over their allotted power. So when I plugged in my server - again, I'm way way under my own rack power allotment - I tripped some breaker on the distribution board.
Tripping that breaker meant that the other phase now took the brunt of the load. Again, my rack is fine, but everyone elses was apparently not, so it .. pulled very hard on that rail. And it immediately tripped the second phase breaker.
But that wasn't it.
Then, the second click was when they tried remote flipping the breakers back on. The massive draw of power on phases when the computers in the data centre were powered back up caused some part of their power distribution setup to just plain fail. I forget the exact details here; I think the UPS was pulled on pretty hard too in that instant and I vaguely recall it also got cooked.
I had like, four? servers, a router and a switch. I was definitely not going to cause inrush problems. But the big hosting customers? Apparently they .. had more. Much, much more. Now this isn't my first rodeo when it comes to power sequencing of servers in a data centre - I had done this for like, a LOT of Sun T1s in circa 2000, staging how to turn them on a rack at a time upon a full power-off / power-on cycle event. But apparently this wasn't done by either the data centre or the hosting customers. All power, all on, all at once.
Now, I'm a small fry customer with one rack still paying the early adopter pricing. The companies in question had a lot more racks and were paying a lot more. So, this was all mostly swept under the rug, I stopped being blamed, and over the next few months we all got emails from the data centre telling us about the "new, very enforced power limits per rack, and we're going to keep an eye on it."
Anyway, fun times from ye olde past when I was doing dumb stuff but people were making much more money doing much dumber stuff at times.
Andrew Pam spoke about new developments in Linux gaming and about hardware and OS support for games etc. He also described some interesting developments with Linux support for SMR disks [1].
We discussed ideas for running a more effective BOF on a difficult topic like FOSS on mobile phones. The main conclusions seemed to be to have more than 2 people chairing the BOF and more than 1 hour to run it. Maybe a BOF as an introduction to a hack evening.
Then we had discussions about the future of LUGs, the difficulty in getting interest in attending meetings, and to what extent YouTube replaces meetings. One conclusion was that we should publish videos of meetings even if they aren’t going to be interesting to most people. If 99% of people find that watching a meeting they can’t contribute to is boring then we get 1% who are interested and if the number of people who see the video is large enough then 1% becomes a good number.
We finished with discussing Linux promotion. There was a general feeling that a Linux Australia subcommittee dedicated to promoting Linux would be a good thing, I didn’t poll the people do determine who of the people who agreed it was a good idea were actually interested in doing the work.
I (Russell Coker) used my Furilabs FLX1s for the meeting and it worked well running Firefox talking to the Big Blue Button server but unfortunately Firefox wouldn’t work with the camera. This was a reasonable result and the 3 hour meeting used slightly over 50% of the phone’s battery which is much better than a Librem5 or PinePhone Pro could manage. For as yet unknown reasons my desktop PC didn’t want to talk to the webcam that I have been using for years.
The meeting had 10 people attending which isn’t a large meeting but was enough for many interesting discussions.
Topics for future meetings include using storage technology such as SMR disks which we also agreed was a good topic for ongoing discussions in the Matrix room over the course of weeks. Changing storage options is not a trivial thing and not something that can be done quickly or easily.
How to best run BOFs and workshops at conferences was agreed to be a topic that needs more discussion. We are talking about how to get things done efficiently for Everything Open 2027 aleady!
Digital sovereignty was briefly discussed in the meeting and agreed to be a topic for future meetings. It is a complex topic and we will break it down and address separate parts in different meetings. A meeting about “digital sovereignty” on it’s own is probably not going to have enough focus to achieve things. A meeting about a specific topic such as “which cloud to use” can get some good results.
Everything Open Everywhere All At Once by Steven De Costa
“ChatGPT: Please create an interesting keynote about random philosophical concepts strung together in a vaguely meaningful way and themed around Chickens”
Lightning Talks
End Security by Obscurity
mygov code generator app
enrol + TOPT
is it secure? Is it spyware?
Only availbale via the app store
Made Freedom of Information in 2021 and gone through multiple appeals/reviews after being denied
Looking for money to appeal further
High Altitude Balloons and and ASN.1
Need a protocol with various requirements to help recovered balloon and get data from it.
Existing protocol not ideal
asn.1 old protocol that might be useful
What would it take to run everything Open in New Zealand
Running a conference is hard
Small team and Harder
Good idea?
What will this actually take
Contact Chelsea if interested.
Open source is not all you need to fight inshitification
No but other freedoms are needed
Brain Model in your Hand
I’m doing a talk in front of 300 people. My brain thinks I’m being chased by a Lion
Learn an Indigenous Language
How to Eat Fruit
Help is at Hand
Join a Union
My Community
Open Source Institute
My $50 question now costs a trip to fench
Pycon did battle decks
What is the most popular emoji on github?
Ran a big query on Bigquery
Grabbed the software heritage project
Lots of small files. Hard to query or mirror
3 Petabytes. Too might to download
Solid Open Source Package
6 talks about deplatforming and/or self hosting this week
Minutes of Linux Australia Annual General Meeting 2025
Monday, 20th Jan 2025, 6:00pm (ACDT)
Recording is available at https://www.youtube.com/watch?v=4clkwhrXImY
Attendance record is available upon request
Meeting started at 6:00pm ACDT.
1. President’s welcome
MR JOEL ADDISON, President
Acknowledgment of the traditional owners of the lands on which we meet, particularly the Kaurna people who are the traditional owners of the land that Everything Open 2025 was held on.
2. Approval of the minutes from the previous Annual General Meeting 2024
MOTION by JOEL ADDISON that the minutes of the Annual General Meeting 2024 of Linux Australia be accepted as complete and accurate.
Seconded by Sae Ra Germaine
Motion Passed with 4 abstentions, no nays
3. To receive the REPORTS of activities of the preceding year from OFFICE BEARERS
MR JOEL ADDISON – President
The full reports is attached to the annual report, so only a few highlights here:
There have been a lot of events over the past year. In fact it has been the busiest Joel has ever been involved with. We had more and more groups come to ask for help in running events. Not every event that was proposed ended up running, but it was great to see so many people come back and run events with us for the benefit of the community.
Special call out for PurpleCon which was a new small event with a relatively inexperienced team who put on a great event, and even managed to make a small profit once GST was properly accounted for.
The WordPress community had some major upheaval during the year which had a flow on effect on WordCamp Sydney. Linux Australia is unhappy with some of the actions that were taken, for example taking over the social media accounts of the conference which Linux Australia would normally control under the Memorandum of Understanding. We will review that to make sure the we are partnered with an organisation we can trust, which we currently have doubts about.
Linux Australia also helped the Python New Zealand user group who faced a significant financial problem caused by their treasurer misappropriating funds. That individual has now been dealt with under the law. Joel is glad to see that chapter behind the organisation. Thanks to both the Linux Australia council and the Python New Zealand committee for their work in resolving the situation.
Finally a special mention for PyCon Au which is now the largest conference run under the Linux Australia banner. A number of members of the Python Australia steering committee stepped back after serving for 10 or more years. Particular thanks to Katie Mch[FIIXME], Russell Keith McGee[CHECK SPELLING], Richard Jones for their hard work over that time
We need to do some work on our constitution. This was flagged last year, but needs to be done now due to some changes in the way the ATO is enforcing non profit status rules. Russell Stuart will speak about this in more detail later. There is a lot of work that will need to be done to update our constitution to make sure we can continue as a non profit.
Questions:
One question on grant applications: What type of grant applications were you hoping for which didn’t happen?
We had two categories of grant applications this year, one for community building and the other for the more traditional grants for projects
The community building grants did not get as much take up as expected. So we need to work on that.and improve our connections to all the groups in our community.
For the standard grants we need to have a discussion about how we track success of the grants. We are keen to support people purchasing hardware or working on software, but we need to do a better job of showing the benefit to the community,
MR NEILL COX – Secretary
Call for people to fill in the attendance sheet.
Again the full report is contained in the Annual Report so just a few highlights here.
It’s been a challenging but rewarding year. Neill is grateful to have been part of the council. We have achieved quite a lot.
As Joel mentioned we ran more conferences than usual. They ran under difficult circumstances and the financial outcomes haven’t been all that we might have hoped for but all in all it’s been a good year.
We have a fair chunk of work ahead of us. Grateful to have been a part of it and looking forward to continuing for the next year.
MR RUSSELL STUART – Treasurer – Includes presentation of the Auditor’s Report
Full report attached to the Annual Report.
Shout out to Sae Ra who is leaving after being part of the council for 10 years.
The bottom line is that we made a loss of $55,000. Those of you who were at the last AGM would remember that a loss was predicted.
The loss almost exactly matches the funds we provided to ensure Python New Zealand continued to operate.
The $55,000 figure is from the auditor. Russell calculates the loss to be $72,000 which he believes is more accurate.
The reason that the figures are different is spelled out in the Annual Report and will not be explained here.
Conference P&L:
The unusual thing this year is that some of our conferences made a loss, mostly due to difficulties with sponsorship.
Everything Open 2024 returned a profit of around $18,000 but the rest didn’t do so well.
The annual report does not include every conference (only four or five are shown) because three of them happened after the end of our financial year. One of the notable absentees is PyCon another is PurpleCon and finally DrupalCon Singapore
DrupalCon Singapore was a new experiment and caused a significant amount of angst, at one stage project a $100,000 loss. That loss did not eventuate due to work by the organisers.
The difference between the auditors figures and Russell’sis those conferences. Largely caused by the conferences having recorded their income in the forms of sponsorship but not having yet paid all their expenses. Russell will book the actual profits once expenses have been paid.
The budget is substantially the same as previous years as our costs do not vary.
Our loss turns out to be pretty much identical to the funds used to bail out NZPUG.
The reason for that is that we made a fair amount of interest. THis was due to investing in a term deposit at a high interest rate for two years. We will receive a similar amount this year before interest rates drop on it.
Our overheads are still higher than the 6% we allow for.
Conferences tend to want to keep their money, but LA feels that we need the funds to allow us to survive years like this last one.
Looking forward all of the conferences have now been bitten by the lack of sponsorship and Russell expects them to adjust course accordingly.
The reality is that the executive of Linux Australia has run the last for Everything Open conferences which is not sustainable. We don’t have anyone putting their hand up to run Everything Open. It is possible that we will lose the $18,000 that Everything Open brings in unless people do put up their hand.
The final item is that we received a surprise letter from the ATO saying that they are introducing a new thing called a not for profit self assessment. It looks to be aligning the ATO’s definition of a not for profit with the Charities and Not for Profit Commission.
One of the questions we need to answer is: what happens to your assets if you wind up?
Our constitution says that the executive could just take it home and buy a new house.
This is no longer acceptable to the ATO and we now need to have a clause defining what happens to our assets or we will no longer qualify as a not for profit.
We have had two attempts to change our constitution both of which were rejected. If we do not resolve this we will be taxed on our profits at the rate of 25%
Instead of attempting this again we will now instead attempt to adopt the new NSW model constitution.
Russell copied the new model constitution but the changes from the one we originally adopted make producing a diff nearly impossible.
Russell has gone through the process of pulling across the things we most care about in our current constitution (free membership, electronic records) and merged them into the new model constitution. This is now up on GitHub as a proposed pull request for our current constitution. We propose to allow everyone to read it and comment on the PR. Sometime before June 20th (the ATO deadline) we will hold a special general meeting to vote on the changes.
Questions
Question from Steve Ellis: The 25% is that on revenue or profits?
Response: Profits. There are also other implications [This is a summary of the answer Russell provided see [33:43 of the recording for the full Q&A]
Question from the floor: Of the eight or so what category of non profit seems appropriate or possible?
Response: It turns out we are a scientific institution [again a summary see the recording at 36:01 for the full answer]
Q: You said that if Everything Open didn’t run next year that you would make an $80,000 loss. How could that happen if you don’t run an event.
A[Russell]: No, we wouldn’t make a loss, but we would miss out on the $18,000 profit which is what it made this year. It ranges between that and $40,000 for the last 27 years. [Full answer at 37:18]
Q from Josh Hesketh: What did we provide to Drupal Singapore – was it banks, insurance or other and would we extend that to other conferences in Singapore and further would we consider other countries in the APAC region?
A[Joel]: With that one it was bank accounts and insurance as you mentioned. It’s not certain that we will continue the agreement with the Drupal Association for future conferences. There can also be tax implications. We will assess future conferences as they come up [Full question and answer at 38:48]
Q: Alexar: Is Linux Australia considering having an impact in the APAC region as a strategy or will this just be a case by case approach?
A[Joel]: We’ve always done stuff across Australia and New Zealand and we have supported some other events in the region. We are not ready to commit to a strategic approach without more investigation. For now we are predominantly focussed on Australia and New Zealand but there are opportunities to work with other organisations in the region.
Follow up Question: Can subcommittees pursue similar opportunities?
Follow up Answer: We always say to our subcommittees feel free to bring any ideas to us and we will discuss them with them and go from there.
Q [Cherie Ellis]: Is there some way that things can be turned or twisted so that it’s still Everything Open but that LCA or the Linux Australia name is bonded to it so that it becomes the recognizable icon that our sponsors know?
A[Joel]: The sponsors we spoke to understand the alignment.The challenge is that sponsors like IBM are no longer operating in the same way anymore in Australia for that particular area. We managed to find a number of new sponsors this year. Every conference has found that a number of recurring sponsors have said no this year because they can’t afford it or they don’t have the budget. We’ve also had a number of sponsors who signed up and then pulled out in the last two weeks prior to a conference. We expect these challenges to continue over the next 12 months, but we are better prepared for them now. As to bringing LCA back one idea that has been considered is to turn the Linux Kernel Miniconf into LCA as part of Everything Open. That was the intent but we haven’t had enough people step up to make it happen. We do have Carlos from the Open SI institute at the University of Canberra who would like to bring Everything Open to Canberra next year.
Q[Steve Ellis]: Thank you for your support of the community. Do we need a group in Linux Australia focused on sponsorship across all of the events?
A[Joel]: Building a pool of organisations is definitely something we need, not just for sponsorship but also to promote the awareness of the events internally in their organisations. We have discussed setting up some sort of central thing. We could set up a working group and go through some of that. Some of the other conferences have also expressed interest.
Q[Paul Wayper]: Question for the Treasurer: How can the community help Everything Open survive from the ticket price perspective?
A [Russell]: I don’t actually set the budget for the conferences. That’s done by the conference treasurers. I try to give them as much freedom as possible beyond “don’t make a loss”. I don’t have an easy answer for your question.
MOTION by Russell Stuart that the Auditor’s Report is a true statement of financial accounts.
Seconded by Steven Ellis
Passed with one abstention
MOTION by Joel Addison that the President’s report is correct.
Seconded by Josh Hesketh
Passed with one abstention
MOTION by Neill Cox that the Secretary’s report is correct.
Seconded byJonathon Woithe
Passed with one abstention
MOTION by Russell Stuart that the Treasurer’s report is correct.
Seconded by Cherie Ellis
Passed with one abstention
MOTION by Joel Addison that the actions of Council during 2024 are endorsed by the membership.
Seconded by Ian
Passed with three abstentions
5. Other Business
Clinton Roy would like to encourage people to engage with the mailing list rather than waiting until the next AGM.
Josh Hesketh would like to give a special thank you to Sae Ra for all her time on the council. Josh believes that she is by a decent margin both the longest serving council member and the most prolific organiser of conferences.
Paul Wayper: Does not want to make trouble, but is interested in talking to the Council about running Everything Open in Canberra in 2026, but would like it on the record that he was not trying to cause trouble by enquiring about videos from Everything Open 2024 on the mailing list.
Joel responds to assure Paul that he didn’t mean anything by his response on the videos, it was just that he had a lot of things to get done. He is still working on them, and they will get done.
Sae Ra: wants to add to the record that that was no slight against Paul it was more just a passing joke and she apologises for that and it had nothing to do with the videos whatsoever.
Peter Chubb requested to move a motion that the meetings of this meeting be approved at the first council meeting rather than waiting all the way to next year when everyone’s forgotten it.
Joel responds: We have to do this as part of the AGM. We can post the minutes before then.
Josh Hesketh: A logistical question of the SGM. Do we have to have a minimum number of members present to make a constitutional change and is there a minimum number of positive votes?
Joel responds: There are but he can’t remember the exact details and won’t answer of the top of his head. Council will send through the details.
6. DECLARATION of Election and WELCOME of incoming Council by the Returning Officer
Returning Officer Julien Goodwin gives his report.
He notes that on examination of the stats Russell and Sae Ra are tied for length of time on the LA Council.
This is Julien’s third time as returning officer.
We have a well-dialed in system now.
The only two things of note are:
Particularly for the OCM positions where this matters, the way second preferences and such work mean that the election is not held in the sort of Senate count style system that Australians might assume.
We didn’t have this situation this year, but it is not uncommon for someone to, for example, stand as both secretary and as an ordinary committee member and if they are elected as a secretary they are not then eliminated by the system for those lower systems so we would then have a hand count. That didn’t apply this year, but we did have the case where for the last OCM position both candidates received the same first count votes so it was down to second count. If it was done with a different system it may have had a different result.
Results
President: Joel Addison
Vice President: Jennifer Cox
Secretary: Neill Cox
Treasurer: Russell Stuart
Ordinary Council Members (alphabetical order):
Lilly Hoi Sze Ho
Elena Williams
Jonathan Woithe
Joel: Thank you for coming along to the AGM. I want to say one more thank you to Sae Ra because you have been a big help to me.
Meeting closed at 19:05 ACDT
AGM Minutes Confirmed by 2025 Linux Australia Council
Meeting opened at 20:04 AEDT by Joel and quorum was achieved.
Minutes taken by Neill.
2. Log of correspondence
Membership subscription page/invoice and a couple of questions – Testing of the new Joomla membership form. Joel and Russell have responded
LA meeting update. – report form Miles on the EO2026 conference. Internal EO2026 email
Adding David Sparks to ANZ in NZ bank accounts – Discussion about adding people to LA’s ANZ New Zealand bank accounts. Includes and on list motion.
Status of subcommittee reports for LA Annual Report – from Jonathan Woithe – updates on subcommittee reports received
You’ve Made A Sale – 76337027 (AU$4.33) – from RedBubble
Re: Receiving funds – question from Arjen about receiving funds for conferences. Russell has responded.
Error when updating mailing list general info pages – request for assistance from Jack Skinner. Joel has forwarded the request to the admin team.
admin team reimbursements – 2025 admin team expense claim. Russell has responded and the claim has been paid.
Annual report – Media and Comms report – Kathy Reid has sent in the Media and Comms report for the Annual Report
Linux Australia website – does your event or area need any content updates made? If so, please let me know what they are – Kathy Reid has asked the event subcommittees for any needed updates
A better way to make event linux.org.au website updates – can we make a process change? – Kathy Reid has suggested a process change for website updates. Jonathan has responded.
PyCon AU announce + committee mailing lists not sending. – Jack enquires about the mailing lists. Joel and Steve have responded.
Request for Payment Approval: PyCon AU – Lemonnade – Russell has responded and the payment has been approved
Celebrating Generosity and Growth in the OSI Community – newsletter from OSI
Annual Linux Australia subcommittee report – Jonathan has sent a request to the PyConAU Steering Committee for their 2025 report.
Fwd: [Pyconau-ctte] Annual Linux Australia subcommittee report – Question from Jack Skinner as to whether council would like a PyConAU26 report for the Annual report. Jonathan has responded.
Fwd: Clearance Employer Notification – EO have received a Working With Children check for someone who is probably a member of Linux Victoria – they are definitely not an EO2026 volunteer. Sae Ra asks for help in clarifying the situation
General note: We continue to receive a lot of spam offering to provide us with a list of attendees to conferences we run. Currently it’s for EO2026 which hasn’t even run yet. I continue to delete these messages.
3. Items for discussion
Working with children check
Everything Open was notified that a volunteer has been approved for a working with children check. The council will check whether they deliberately used Linux Australia as they are not volunteering with Everything Open or directly with Linux Australia.
Access to Policies and Linux Aus mailing lists to handle moderation requests for secretary – Joel will share the password after this meeting.
4. Items for noting
Election is ready to go. Joel will contact Julien about being the scrutineer/returning officer.
Membership backlog is pretty much cleared. Several people responded to the pre-election reminder, but many have not. I intend to cancel those who have not responded.
Russell has moved a motion on the council mailing list to add David Sparks and Christopher Burgess to the anz.co.nz mandate.
MOTION: Linux Australia adds Dave Sparks and Christopher Burgess to its anz.co.nz mandate as payment authorisers.
I seek a seconder and votes on the motion.
I vote in favour of the motion.
Seconded by Jonathan Woithe Results: Motion passed
5. Other business
Annual Report The content is ready, Jenny will look at starting the final layout this weekend. We will aim to have the report finalised by 7 Jan 2026.
2019-2021 PO BOX paperwork – Joel has responded to Julien
Linux Australia’s 2024/2025 auditLinux Australia’s 2024/2025 audit – Russell has requested that the auditor start work on 2024/25 audit
Probleme with Ubuntu Manager–kernel version 6.8.0-87-generic, ubuntu 24.04.3LTS – Jonathan has responded
Important: Scam Messages Requesting Account Verification – notification from RedBubble
Fwd: Linux Australia’s 2024/2025 audit – email from Russell asking various subcommittee treasurers to tidy up some loose ends in Xero.
Authorisation for Kiwi PyCon Transaction Exceeding $5000 – 2025-11-26 – Russell has responded
Fwd: Can you post the JC Guzman announcement to social media? [Internal EOCBR26 email]
On-campus accommodation for core team [Internal EOCBR26 email]
Several notifications from RedBubble about EO2026 merch sales.
Access to PyCon AU 2025 stripe account – request from Jack Skinner for access to stripe to finalise PyConAU 25 books in Xero – Russell has responded
Finalising PyCon AU 2025 accounts – Discussion between Jack Skinner and Russell about finalising the PyConAU 2025 financial position.
Status of subcommittee reports for LA Annual Report – report from Jonathan on the status of subcommittee reports for the Annual Report. Still waiting on Kiwi PyCon, Admin, Flounder and LUV
Catering selections – part 2 -Penguin dinner [Internal EOCBR26 email]
LA third party maintenance – Wednesday 3rd Dec – notification from the admin team of planned maintenance that will affect LA’s servers’ internet connection.
Tuesday 2-Dec’s Everything Open meeting agenda [Internal EOCBR26 email]
.au Licensing Rules Review for auDA – notification from Sae Ra that auDA are doing a licensing rules review.
Amazon Web Services Billing Statement Available [Account: 103334912252] for $7.47
Membership subscription page/invoice and a couple of questions – questions from Nathan Morrow for Russell about payment gateways for Joomla.org.au membership
Apologies – Julia is unable to attend tonight’s subcommittee meeting
PyCon AU 2026 update for 3 December 2025 – Update from Jack Skinner on PyConAU2026
Amusing spam:
Invitation to join the Illuminati Order of Poseidon
3. Items for discussion
Kiwi Pycon Subcommittee Update (20:05 AEDT)
190 attendees over three days
Financials significantly better than expected
$2,000 – $4,000 loss after LA taxes
Community success. Two days of great talks
Took a lot out of the organisers who are going to take a break next year
Will be looking for new organisers
Joel thanked the organisers on behalf of the council, and acknowledged the good result – it may be a loss, but it is still a good result and the result of a lot of work.
KiwiPycon has a new budget spreadsheet for Russell to look at. It may be a better way of tracking profile and loss.
While the organisers are thinking of leaving a bit of a gap before the next conference they are already planning to communicate with possible future sponsors.
Drupal Subcommittee Update (20:10 AEDT)
DrupalCon Asia
Final budget not yet complete
214 people
Post event survey overwhelmingly positive
Suspiciously few things went wrong
50% of attendees from Japan
A local Drupal association has formed.
Currently wrapping up the final invoices.
Final update in February
Michael is resigning from the steering committee.
A new chair and two new members will be elected.
Next event in India in 2027, but need to get local sponsors to step up and commit. This hasn’t happened yet.
The Pune group runs a 250 person event for AUD4,000 so the economics are quite different.
No event in 2026.
The treasure hunt only had 36 people in 14 teams b ut it was a wonderful community event. Check the flickr stream!
Michael had a lot of fun putting the event together but will never do it again (a lot more work than expected)
These two events (Singapore and Japan) have had a major positive effect on the Drupal community in Asia.
Joomla Subcommittee Update (20:15 AEDT)
Most of these details are in the email to Jonathan for the annual report
Have an event planned for next year in Melbourne.
A membership form has been set up. Will be made live this week before the meeting next Tuesday.
Still some work to do on the backend.
Work on the website is ongoing, probably won’t be launched until next year.
Question about qualifying as a NFP in Victoria. LA is qualified by the ATO nationally so there should be no problem in Victoria.
Admin Team Update (20:20 AEDT)
Not a lot to report
Still poking at Russell Coker’s complaints. Russell would like zero spam. Steve is not sure that this is possible. Now down to 1 – 1.5%. Some tightening can still be done but at some point valid email will be rejected.
The annual report is nearly done.
Expense claims in progress
Budget is almost complete
Steve will respond to Russell at some point.
Some disruptive maintenance about to start. Steve will be monitoring and will report any problems.
PyCon AU Subcommittee Update (20:25 AEDT)
2025
Basically done.
Annual report sent in
Jack has tidied up the accounts.
The last thing to do is the PSF grant accountability report.
This is Peter’s last meeting
Joel thanked Peter on behalf of the council.
2026
Full team has been filled
Ticket sales are continuing, no major sales effort has been made yet.
KiwiPyCon has recommended that members attend Brisbane.
Will there be an upcoming events page in the annual report? Answer – no. The annual report will focus on the past year.
There will probably not be another subcommittee meeting before the election. The hope is that the new council will be up and running by early February.
PyConAU 2026 would like to have a banner at EO2026.
WordPress Subcommittee Update (20:30 AEDT)
No report
Everything Open Subcommittee Update (20:35 AEDT)
The financial situation is similar to last time. Currently looking at a $10,000 profit.
Merch is online at RedBubble. T-shirt design is done.
One more keynote to announce.
Signed sponsorship contracts are coming in. Most are now signed.
Working on getting volunteers and speakers to finish registering on the website so dietary requirements can be communicated to UC.
Moving to a weekly meeting cadence. Notionally three more this year, but the 23rd will probably be fairly casual.
Speaker and keynote gifts are being finalised.
Currently 107 registrations, including speakers, organisers and volunteers.
At this point EO is past the break even point.
Flounder Subcommittee Update (20:35 AEDT)
No report
LUV Subcommittee Update (20:35 AEDT)
No report
4. Items for noting
Membership backlog:
Emails have now been sent to all pending/awaiting approval members who have applied since January 2025. There are another 105 applications dated from between November 2021 and December 2024. [Joel suggests checking for obvious community members and declining the rest. Neill will come up with a nice way of telling them to reapply if that are still interested
28 new members have responded and been approved. I’m waiting on a reply from 77 others.
CiviCRM reports 1003 current members.
Daniel Pocock has applied for membership – council will not approve this application
5. Other business
NFP papers have been submitted to the ATO
Annual report submissions from subcommittees are nearly completed, the remaining ones should be submitted by Sunday.
Subcommittee policies need to be clarified and then enforced – this is a job for the next council but we should begin preparations. We probably need a register of subcommittees and other affiliated organisations.
AGM will be held during Everything Open – probably on the first evening of the conference which will be a Wednesday night.
The election should be called by When do we need to call the election?
The TL;DR is - you can't just plug a 32k DS1386 into an SGI Indy and have it work, as a bunch of stuff is wrong.
The longer version!
Here's a picture from the datasheet:
Now, at the outset it looks like A13 and A14 on the 32k module need to at least be grounded - if they're floated or high then the RAM will be selected when you don't want it to be, and you'll just fail to see the RTC.
However, if you just do that your Indy won't boot because it turns out that pin 3 on the 8k module is an undocumented (in this datasheet) auxiliary Vcc input - the 5v auxiliary / always-on rail is actually there. Shorting it to ground will just make the Indy super sad. Don't do that.
So, in lieu of making up a PCB (which I think I'm going to do anyway just to be "clean" - I used some pin headers to raise the DS1386 above the Indy PCB.
Note that pin 3 on and pin 28 don't have pins (and I'm going to put some tape over the pins just to be super clear nothing shorts out).
Then, I did a quick bodge wire job on the underside of the DS1386-32K module:
Where pin 3 and pin 28 are tied to pin 16.
Then, well, plug it in, align it right, and it should just work! It did for me!
Meeting opened at 20:08 AEDT by Joel and quorum was achieved. Minutes taken by Neill.
2. Log of correspondence
Council meeting minutes for 2024-Oct..2025-Sep – we need to provide copies of the minutes to the auditor
Re: Bills to Pay – DrupalCon Japan 2025 – Russell has responded
Clarifying and confirming contact details – Jack Skinner has shared contact details with the council
Spreadsheet shared with you: ‘DrupalSouth operating budget – Wellington 2026’ – Julia Topliss has shared the Drupal Down Under budget with the council
Linux Australia Inactive Member – we have received a request to deactivate a membership. Neill has responded (and cancelled the membership)
LA meeting notes – email to the EO subcommittee reporting on discussions at the LA subcommittee meeting.
Loose ends – discussion between Russell and Jack covering Wise, Stripe, Paypal, password managers and international tax on ticket sales.
[LACTTE] Request for insurance cover for a Perth Linux User Group event – request for insurance cover. Council passed a motion on email and provided insurance for the event.
Fwd: DDD Melbourne 2026 Community Space Applications – Joel has told Sae Ra that LA would like to participate.
Stuff we need from Linux Australia – email from EO. Joel and Sae Ra have responded
Must-See Recordings Now Available – newsletter from OSI
Get your T-shirt size in! – EO internal email
We need your T-shirt size for the EO conference. – EO internal email
Transport and accommodation options draft. – EO internal email
Lodge Linux Australia Activity Statement July..September 2025 – Russell has requested LA’s accountant lodge the latest BAS. The accountant has confirmed lodgment
Re: DrupalSouth Community Day 2025 – wrapping up accounts stuff – discussion between Julia and Russell about paying the remaining invoices for the Drupal South Community Day
Fwd: Flounder post from admin@lists.linux.org.au requires approval – enquiry from Russell Coker about progress in blocking spam from lists.linux.org.au – We need to respond saying that changes have been made and we are monitoring the situation
Fwd: Public Liability Insurance – request from KiwiPyCon for the current insurance certificate. Joel has supplied it.
LA Council Vote: Accept PLUG Installfest as event – on list motion to accept event. Motion was passed.
Keynote #1 and early bird “hurry up” notice for Monday – internal EO email
Authorisation for Kiwi PyCon Transaction Exceeding $5000 2025-11-15 – payment was authorised.
2019-2021 PO BOX paperwork – Julien Goodwin asks if he can dispose of paperwork from 2019-2021
Tuesday night’s meeting – internal EO email
On-campus accommodation for core team – internal EO email
Subsidised parking – internal EO email
Please register on the EO2026 conference website
Link to join meeting – request from Sophie for Linux Victoria for a link to tonight’s meeting. Joel has responded.
DrupalCon Nara Update – Report from Michael Richardson
3. Items for discussion
PO Box items with Julien Everything that was there has been scanned, so we should have copies of everything. We should not need physical copies, so it should be fine for Julien to dispose of them. We will ask for Julien to shred them. Joel will contact Julien.
Stripe
After a discussion between Jack and Russell about Stripe’s tax notifications, it seems reasonable to argue that we shouldn’t have to pay VAT/GST in other countries for services being consumed in Australia.
Russell: Our Accountant didn’t give us firm advice one way or the other when I asked him.
Russell: If someone was paying us to watch the live stream while they are in another country it might be different. Therefore we can’t sell digital tickets to overseas attendees.
Russell feels that some of this may be an attempt by Stripe to sell us a service.
Elena suggests that we should just say that digital tickets are sold under Australian conditions.
We will develop a written policy on this and publish and make subcommittees aware of it. Elena will write the first version.
4. Items for noting
On list motion MOTION: That Linux Australia will provide assistance, in the form of insurance cover, to PLUG for their Installfest November 2025. Moved by Joel, Seconded by Jonathan Motion passed.
DrupalCon Japan DrupalCon Nara was a big success. 211 ticket sales in the end, and financials look to be about where we expected which is good. Feedback has been extremely positive.
Michael has informed the Steering Committee that he is going to leave the Committee, and they are evaluating their options for the next DrupalCon, probably in India, probably in 2027.
5. Other business
Annual Report
Elena has started work on the annual report. There is a document in the shared drive. Elena will produce a plan for chasing down the required information this week.
Membership applications – Still behind on processing these – have drafted an email to send to applicants to ask about their connection to the community.
I am writing to you about your recent application to join Linux Australia._
We would like to confirm that you would still like to join and if so ask if you could outline how you currently participate in our community.
We aim to represent and assist the groups and individuals who make up the Free Software, Open Source and Open Technology communities in Australia.
We support a number of conferences in Australia, New Zealand/Aotearoa and the Asia Pacific region, including Everything Open, Drupal Down Under, Pycon Au and Kiwi Pycon
Can you tell us how you heard of us, and briefly describe your participation in the communities we represent? There are no specific requirements for membership, but to reduce the number of spam applications, we are confirming applications are genuine before we approve them.
6. In camera
No items were discussed in camera
7. Action items
Neill – publish minutes by 22/11
Neill – respond to Russell Coker
Elena – write a policy for sale of tickets to international attendees
7.1 Completed Items
7.2 Carried Forward
Meeting closed at 20:48 AEDT
Next meeting is scheduled for 2025-12-03 and is a subcommittee meeting
Meeting opened at 20:07 AEDT by Jennifer and quorum was achieved at 20:13 AEDT Minutes taken by Neill.
2. Log of correspondence
Richard Shea expenses – this has been resolved by deleting these items from Xero
Fwd: Bank account updated for Pycon AU 2026 – Jack Skinner asks if Russell had updated the bank account for PyConAu in Stripe
[LACTTE] Request for insurance cover for a Perth Linux User Group event – Harry McNally is helping to run another event that needs insurance
Socials posts – list of social media posts for EO2026
Fwd: Re: [LACTTE] BAS Time – Update from LUV – Russell is happy with progress
Amazon Web Services Billing Statement Available [Account: 103334912252]
Fwd: DDD Melbourne 2026 Community Space Applications – Sae Ra asks if LA would like to participate in DDD Melbourne in Feb 26
Lodge Linux Australia Activity Statement July..September 2025 – Authorisation from Russell LA’s tax agent to lodge our BAS
Everything Open 2026 Meeting tomorrow night, Tues, 4-Nov, 8pm – Agenda for the EO Subcommittee meeting
PyCon AU 2026 Update for 5 November 2025 – see below for details
Activity statements are available online [SEC=OFFICIAL:Sensitive] – notification from the ATO
Updated agenda for tonight at 8 – update to EO meeting agenda
3. Items for discussion
Admin Team UpdateÂ
Investigated the complaint from Russell C about forged emails. Have changed a config option and we are now blocking even more email. Hopefully fixed.
Currently in a change freeze for EO which will remain in place until after the election.
Steve will try and talk to a FastMail rep while he’s at the IETF meeting in Montreal.
It is time to start planning to replace the current server hardware. It has about two years left on the original planned lifetime.
Kiwi Pycon Subcommittee UpdateÂ
Conference is happening this month
Sponsorships are not great which is a major impact on the financial position of the conference.
NZ economic situation is generally poor and companies are not looking to recruit.
Ticket sales are up
The current projected loss of $16k can hopefully be reduced by more ticket sales.
The projected loss was $30k a month ago.
Targeting Kawaicon for more ticket sales.Â
Numbers are ahead of Invercargill now.
Planning for 2026 is starting but there is little appetite for running another conference at a loss.
Drupal Subcommittee UpdateÂ
No update [Neill check with Julia re invitation]
DrupalCon Asia
$63,946 in ticket sales of $66,192 goal (up $29k from Oct)
171 tickets sold, expecting around 190-200 total
$147,760 sponsorships of $167,000 goal (up $41k from Oct)
Treasure Hunt is underperforming on attendanceÂ
Expecting around a 10k net profit after DA and LA share
There is still some fat in our expense estimates (~10k)
Seeking guidance on willingness to support DrupalCon India in 2027
DrupalCon India would be a significantly different event – much smaller budget
Financial regulation in India may be a factor.
The DrupalCon Asia is about to reshuffle positions
Joomla Subcommittee UpdateÂ
Working on website updates. Ongoing.Â
The membership/subscription system is nearly ready. Will send through examples for council to look at.
PyCon AU Subcommittee UpdateÂ
2025
No further money expected either in or out.
Everything pretty much finished.
Final reports to write and then 2025 will be done.
Looking at a $1200 loss after the LA tax.
2026
A few “looking forward” points as an async update:
We intend to publish a conference roadmap “soon” outlining our call for tracks, CFP, volunteers and other key milestones to help set expectations given our unusually long planning cycle. It would be great if this can be amplified by LA.
We’re on track to have the full new website live by KiwiPyCon. Very excited by this – it’s looking awesome.
We would like to announce (and announce) longer call for specialist tracks at the same time (in time for Kiwi PyCon). It will be open through to early next year (TBA if it will overlap w/ Everything Open).
Our team has grown, and will grow further. We welcome John Band (LI) to drive marketing and communications, Rhydwyn McGuire (LI, formerly PyCon AU 2025) as Program Chair, and Izy Hogan (formerly PyCon AU 2025) as Volunteer Lead. We have active conversations with future core team members to drive sponsorships & commercial sales, program co-chair, and community & culture focus areas.
I’ve also started a new informal essay series titled “From the directors desk” where I share a little more transparently how we approach organising PyCon AU 2026 behind the scenes. The first post islive, and I’d welcome feedback – primarily in the shape of future topic suggestions
Lastly: I’m aware our plan to update ‘actuals’ in the approved/shared budget has been delayed. Nic will be back on deck ‘soon’ . The delay is primarily optimising for getting it right as a team, for the long term, and in a repeatable way aligned to Xero actuals. As an interim reassurance: we reconcile Xero weekly, and I’m tracking closely any budgeted spend this year (narrator: minimal to no new spend expected) matched closely against actuals in Xero. I’ll raise to discuss on Wednesday night.
Proposed Agenda for our 5 minutes on Wednesday:
I’ll highlight our wins + asks (slide attached).
Questions WRT minuting Nucleus retroactively.
Budget actuals.
Questions from council
WordPress Subcommittee Update
Looking at possibly running a couple of events next year
– possibly something the week before Drupal South in Wellington
 Brisbane September next year
Looking for more organisers.Â
Vladimir and Janna would like to have a less central role.
[Council]:We would need to clear a New Zealand event with WordCamp central, our current agreement is only for Australia
Everything Open Subcommittee UpdateÂ
Two keynotes have been announced and the rest are scheduled to be announced
There is a current commitment of $33k. One potential sponsor has asked for an attendee list which is not something that Linux Australia has done in the past. [Jack]: Suggests that a conversation be had with potential sponsors to tease out what the sponsors goal for the list is and suggest alternative ways of generating leads.
In addition Open SI are providing very significant in kind sponsorship which needs to be recognised. Name them as a “venue sponsor�?
EO need access to symposion to be able to audit ticket sales and process refunds.
Catering will now include lunch because there is enough sponsorship.
Currently looking at a surplus of $9,600
T-shirt designs are in progress
Choice of T-shirt print vendor is up to the conference.
Arjen is interested in providing a psychologist to attendees, LA has previously provided grants for this, but is unlikely to do so this year. LA has not been able to run a grants program due to a lack of funds.
Sessions have been chosen – need to prepare to publish the schedule to the website.Â
How many lanyards does EO2026 need to buy?
Videos from 2025 should be ready before the 2026 conference.
Carlos has spoken to the Unilodge staff and accommodation can be offered to attendees. Unilodge will manage the bookings. Some hotels have offered discounts for attendees.
Flounder Subcommittee UpdateÂ
No meeting since the last report.
A lot of activity on matrix
Russell Coker plans to hold more events soon.
LUV Subcommittee UpdateÂ
Andrew is now an OCM
Nothing to report yet, but the president and treasurer seem to be managing things well.
4. Items for noting
We need to improve onboarding of subcommittees, especially expectations around meeting times and that they shift for daylight savings time.
5. Other business
We still need to send a request for bids for EO2027
6. In camera
Two items were discussed in camera
7. Action items
7.1 Completed Items
7.2 Carried Forward
Meeting closed at 21:43
Next meeting is scheduled for 2025-11-19 at 20:00 AEDT (UT+11:00)
With at least three disciplines of interest - energy and climatology, public economics, and high-performance computing - there is the issue of whether current trends in artificial intelligence are environmentally sustainable. The following is a basic sketch of electricity usage, needs, and costings.
The promise of artificial intelligence is as old as computing itself, and, in some ways, it is difficult to distinguish from computing in general. As the old joke goes, it is no contest for real stupidity, and an issue that became all too evident to Charles Babbage when he developed the idea of a programmable computer:
On two occasions I have been asked, - "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question.
-- Passages from the Life of a Philosopher (1864), ch. 5 "Difference Engine No. 1"
Of course, we now have computational devices that can attempt to solve problems with incorrect inputs and perhaps provide a correct answer. That, if anything, is what distinguishes classical computation from contemporary artificial intelligence. Time does not permit a thorough exploration of the rise and fall of several attempts to implement AI; however, the most recent version of the last decade, which involves the application of transformer deep learning and the use of Graphics Processing Units, continues to attract investment and interest.
Transformer architectures for artificial neural networks are a fascinating topic in their own right; attention (pun intended) is directed to the use of GPUs as the main issue. Whilst the physical architecture of GPUs makes them particularly suitable for graphics processing, it was also realised that they could be used for a variety of vector processing, providing massive data parallelism, i.e., "general purpose (computing on) graphics processing units", GPGPUs. However, physics gets in the way of the pure mathematical potential of GPUs; they generate a significant amount of heat and require substantial electricity, and that's where the environmental question arises.
The current global electricity consumption by data centres is approximately 1.5%, according to the International Energy Agency. However, that is expected to reach 3.0% by 2030, primarily due to the growth of AI, which would include not just the GPUs themselves, but also the proportional contributions by CPU hosts, cooling, transport, installation, and so forth. A doubling of energy consumption over a period of a few years (from c400TWh in 2024 to c900TWh in 2030) is very significant and, if the estimates prove to be even roughly correct, then further energy utilisation needs to be considered as an ongoing trajectory for at least another two decades until it becomes ubiquitous.
There are essentially two ways of managing energy used in production with an environmental perspective, given a particular policy. One approach is high-energy and high-production, concentrating on renewables or non-GHG energy sources. The other is a reduced-energy, high-efficiency approach that concentrates on better outcomes, "doing more with less". More important than either of these, in my opinion, is the incorporation of externalised costs into the internal price of an energy source. One graphic example of this is the deaths per Terawatt-hour by energy source. Solar, for example, is more than three orders of magnitude safer than coal.
To satisfy existing and expected demand, the AI industry is, in part, turning to nuclear for its energy needs. Data centres tend to be located within population centres, partially due to latency reasons, whereas renewables like wind and solar require a significant amount of land area. Additionally, where existing nuclear power plants and infrastructure are already in place, it is relatively inexpensive, even compared to battery technologies. Nuclear provides sustained power generation not just throughout the day, but across months and seasons. With approximately 5% of generation lost in transmission, nearby power sources are more efficient.
The main weakness of nuclear power is the time and cost associated with the construction of new plants, and in this regard, the big data centre and technology groups are taking a gamble. They assume that there will be sufficient demand for AI and that they can generate enough income over the next decade to cover the costs. Whilst they are very likely to be correct in this assessment, and certainly the choice of nuclear is preferable to the fossil fuel sources that are currently driving most data centres (e.g., methane gas in the United States, coal in China).
As for demand-side considerations, these can include the energy efficiency of the data centres themselves, the way models are designed, and the way AI is utilised. Cooling is an especially interesting case; as mentioned, GPUs run quite hot, and to avoid catastrophic failure, they require effective cooling. This is usually done with evaporative cooling, which means significant water loss, or by chillers, which doesn't mean much loss, but a huge amount of water for cooling. A third option is dielectric liquids, such as mineral oil, which results in a data centre that is quiet and at room temperature, while servers operate at an optimal temperature. The main disadvantage is the messy and time-consuming procedures for upgrading system units.
The model design also presents some opportunities for improvement. The typical approach is to train neural networks with large quantities of data; however, the more indiscriminate the data collection is, the greater the possibility of conventional error. As some critics suggest, an LLM is essentially a language interface that sits in front of a search engine. A smaller but more accurate collection of data can be more accurate, as well as being less resource-intensive to train in the first place. A number of smaller models can operate with connective software for matters outside of the initial module's scope instead of a monolithic approach.
Finally, there is the matter of what AIs are being used for. Certainly, there are some powerful and important success stories such as the key designers behind AlphaFold winning the 2024 Nobel Prize in Chemsitry for protein structure prediction and, as many contemporary workers (especially in computer science) are all too aware, the ability of AIs to produce code is quite good, assuming th developer knows how to structure the questions with care and engages in thorough testing. Additionally, the increasing application of these technologies in robotics and autonomous vehicles is disconcerting, as illustrated by the predictive and plausible video "Slaughterbots".
On the consumer level, an AI can perform tasks which a human is less efficient at. So rather than simply asking "how many tonnes of a GHG does AI cause", a net emissions question should be asked, appending "... compared to human activity", that is, productivity substitution. However, with effectiveness comes the lure of convenience, as it attempts to extend the use of AI to everything, even when human energy usage would be less than that of an AI-mediated task. Ultimately, it is the combination of human failings, a combination of laziness (always choosing convenience), wilful ignorance (not knowing and caring about energy efficiency), distractibility (extending AI for trivialities rather than tasks of importance), and powerlust (commercial or political), that present a continuing challenge to the prospect of implementing an environmentally-sustainable development of artificial intelligence.
Also, amusingly, the ARC BIOS console IO was available at this point but nothing was being printed early enough for it to be seen! Debugging was quite a bit faster once I realised I was getting far enough for the ARC BIOS entrypoint to be initialised so I could printf().
On the evening of September 3, 2025, there was suddenly a strong and remarkably unpleasant flat metallic odour in our master bedroom and ensuite. We opened all the doors and windows and got the fan on, and eventually it went away. The smell didn’t come back after closing up, but the next morning when I was inspecting the Redflow ZCell battery in the crawl space under the house I discovered a 6cm long crack towards the right hand side of the back of the electrode stack, about 2.5cm above the base. A small amount of clear liquid was leaking out.
Ah… That’s not good.
Due to the way our house is constructed on a hill, the master bedroom, walk in robe and ensuite on the lower floor share some airflow with the crawl space under the main floor of the house. For example, the fan in the ensuite vents to that space, and I’ve felt a breeze from an unfinished window frame in the walk in robe, which must be coming from the space under the house. I’ve since siliconed that window frame up, but the point is, the electrode stack split, the battery was leaking, and we could smell a toxic fume in the bedroom.
Readers of the previous post in this series will be aware that Redflow went bust in August 2024, and that our current battery was purchased from post-liquidation stock to replace the previous one which had also failed due to a leak in the electrode stack. When the new unit was commissioned in March 2025 I applied some configuration tweaks in an attempt to ensure the longest lifespan possible, but it lasted slightly less than six months before this failure. Not great for something that was originally sold with a ten year warranty.
Under the circumstances I wasn’t willing to try to procure yet another new ZCell to replace this one, but given we’d found the leak very early this time, I figured I had nothing to lose by trying to repair it. I had heard of marine fibreglass being used successfully in one other case to repair a leaking ZCell, so I discharged the battery completely then set to work patching it up the following weekend. This involved:
Wearing PPE (gloves, a respirator, safety glasses)
Turning the DC isolator off so the unit wasn’t powered
Carefully wiping the electrolyte leak away with a rag
Taping up some plastic sheeting below the stack to keep the rest of the unit clean
Cleaning the stack carefully with a little methylated spirits
Roughing up the surface with some 80 grit sandpaper
Cleaning the stack carefully again with methylated spirits
Mixing up West System 105 epoxy resin and 205 hardener
Applying four layers of fibreglass cloth (which is irritating to cut with scissors, by the way) in alternating directions – each layer was wet down with epoxy using a brush then applied to the surface of the stack with a little metal roller
Crawling out from under the house, unkinking most of the muscles in my body, and having a long hot shower
Waiting til the day after next for everything to set in case 24 hours wasn’t enough before recommissioning the unit
Here’s a picture of the finished repair. I didn’t bother sanding it smooth because it just doesn’t matter – it’s a battery, not the hull of a boat – and I could do without creating any more dust. I actually ran two strips of fibreglass because there was also a little split at the top of the stack, although that one didn’t appear to be leaking.
Not too bad for a first attempt, and good practice for repairing the hull of my rowboat.
Recommissioning the unit was interesting. Upon bringing it online, it immediately went into a safe shutdown state because the electrolyte had dropped down from its usual running temperature of 18-24°C to a bit over 8°C during the five days it had been offline.
In order for a ZCell to charge, the electrolyte needs to be at least 10°C, and at least 15°C for it to discharge. So I took one of our 2400W panel heaters under the house and turned it on next to the unit. “How long does it take for a 2400W panel heater to heat 100L of nearby liquid electrolyte by 2°C?” I hear you ask. “Too damn long” is the answer. I started the heater at 13:10, and it was 16:50 before the battery was convinced that the electrolyte was far enough above 10°C to be happy to start charging again. But, charge it did, and we were up and running again… Until the next morning when my wife detected that nasty smell in the ensuite again. Upon further inspection of the unit I found a tiny drip coming from the bottom of the front of the stack, behind the Battery Control Module (BCM). So once again I discharged and decommissioned the battery in preparation for repair.
This time I had to pull the BCM off to get to the electrode stack behind it. First I checked that the battery really was discharged with a multimeter. Then I disconnected the DC bus cabling, the comms cable, and the connections to the pumps, fans and leak sensors after taking a photo to make sure I was going to put everything back in the right place. Finally I unscrewed the battery terminals and pulled the BCM off. It’s actually a really neat arrangement – the BCM just slides on and off over the two cylindrical terminals the come out of the stack. It’s a bit stiff, but once you know it comes off that way, you just jiggle and pull until it’s removed.
The BCM comes off…
One thing to be extremely careful of is that you don’t accidentally drop the washers from the battery terminals down into the bottom of the battery, because if you do you will never, ever get them back again, and will have to order some M8 silicon bronze belleville washers from Bronze & Brass Fasteners Pty. Ltd. to use as replacements. I don’t know exactly what Redflow used here, but I know they’re belleville washers from reading the manual, I determined they were M8 by measuring them, silicon bronze is apparently a good electrical conductor, and BABF would let me buy them individually rather than in lots of a hundred. I purchased eight, in order to have several more spares.
…to expose the front of the stack, with some cracks at the bottom.
There was a bit of cracking on the front of the stack, similar to what was on the back, so then it was a repeat of the earlier fibreglassing procedure. This added a couple of millimetres depth to the front of the stack. Now the circuit board in the BCM could no longer sit flat against the ends of the battery terminals, due to a series of little protrusions on the back of the BCM case which would ordinarily sit flush against the stack. These I lovingly twisted off with a pair of pliers. Then I reconnected all the cabling and used a nice shiny new torque wrench to ensure the battery terminals and DC bus cabling were tightened to 10Nm per the manual.
Here’s the freshly applied fibreglass…
…and the slightly modified BCM.
I wasn’t quite ready to recommission the battery yet at this point given we’d had those two nasty fume experiences in the bedroom. If I’d missed anything with this second repair, or if anything else broke and there were gas emissions of any kind, we didn’t want to experience them. So I purchased a sub floor ventilation kit with a bushfire compliant external vent and installed that under the house.
I assure you the walls and floor are actually straight and level.
Then in early October (it took a while to get all this work done around my actual job) I brought the battery online again. Of course I had to once more use the panel heater to get it going. We’re running the ventilation fan 24/7 (it’s very quiet), and I got into the habit of going under the house and doing a visual inspection of the battery every morning as part of our daily rounds feeding the chickens.
Everything went beautifully until October 29 when I noticed a small drip of red liquid which appeared to be coming from a capillary tube on the front right of the stack. The previous leaks had appeared clear, which I imagine means they were from the zinc electrolyte side of the battery, whereas this red suggested to me a leak from the bromine side of the battery. The electrolyte actually initially has the same chemical composition in both tanks, but charging changes it – you’ll see the electrolyte in the bromine pipe on the front of the battery go orange, then red, as charge increases, whereas the electrolyte visible in the zinc pipe remains a mostly transparent pale yellow. Anyway, another leak meant decommissioning the battery again to investigate.
This is new.
Off came the BCM again to check my fibreglass work (pristine and undamaged!) and off came the side of the enclosure to get a better look at the problem area. I inspected the capillary tube in minute detail with a magnifying glass and couldn’t find any obvious damage that would explain the leak. The tube runs from the top of the stack down through a hole in the bottom front of the stack, which keeps everything very neat, but honestly seemed to me like it was introducing a potential weak point into the front of the stack, so I rerouted the tube then carefully filled the hole in the stack with Araldite, on the assumption the leak was actually in the stack. In case the leak turned out to be in the tube, I ordered some viton tubing to use as a replacement. After recommissioning the battery again no further leak was evident over several days, indicating that the problem was indeed in the stack, and not in the tube. This is probably just as well, as my new viton tubing turned out to have a slightly smaller internal diameter (2mm) than whatever Redflow used during manufacture – maybe 2.5mm?
Capillary tube rerouted off to the side.
No more hole in front bottom of stack.
A few days after that on November 7, the battery indicated a hardware failure due to “impedance error”, and a small drip of red liquid appeared on the front left side of the stack. I’ve been told this error can be due to higher pH levels and the formation of zinc hydroxide, or degradation of the core electrode, or separator failure, or overheating of the stack reactor. Within the limits of my knowledge and ability there was very little I could do about any of these things, so then the question became: what next?
At this point I felt that I had really pushed things as far as I reasonably could. If the fibreglass repairs on the front and back of the stack proved sufficient and nothing else had gone wrong, I would have been happy to continue operating the battery as we had been since March, but these additional leaks and the impedance error suggested to me that things were going to continue to go downhill. It seems that the answer to the question posed in my last post, i.e. “how far down the road can we kick the migration can” turned out to be about eight months.
The only technology that’s immediately viable for us to switch to is LiFePO4 batteries. We’re looking at a stack or two of Pylontech Pelios because they will work with our existing Victron inverter/charger gear and come in IP65 cases so can be installed outdoors without too much difficulty. It will still be a while before we can get those installed though, and in the meantime I can’t just decommission the existing battery because then our solar generation won’t work.
The way our system is installed, we have solar panels connected to an MPPT on the DC bus, which is connected to the battery, and to our MutliPlus II Inverter/Chargers which in turn power our loads. The ZCell Battery Management System (BMS) tells the system what the battery charge and discharge limits are. If the battery is missing or broken, the BMS will not let the MPPT run at all, which means that no battery = no solar power, not even to power our loads.
I actually tried to work around this problem a couple of times in the past when previous batteries were dead. There’s a description of some unsuccessful attempts in an earlier post, and I also separately tried to fake up what I called a Virtual ZCell in software back in December 2024. In that experiment I was telling the Victron system that there was a battery present at 25% state of charge, but with a charge current limit of 0A (so it wouldn’t try to charge the non-existent battery) and a discharge current limit of 1A (so the battery looked at least a little bit available but no real discharge would be attempted). Incredibly this worked, but after about a week the MPPT started raising various errors so I gave it up. It seems that it’s necessary for a real physical battery to be present in order to help correctly regulate the voltage on the DC bus.
Back to the real battery: After the impedance error occurred I shut it down, rerouted the left front capillary tube, Araldited up its hole and the bottom front of the stack as I had done on the right hand side, then recommissioned the battery and reset the impedance error. I then set the system maximum state of charge limit in the BMS to the lowest value possible (20%). This would mean that the battery would never be charged much, and thus would never be stressed much. I imagined that whatever reactions were happening inside the stack that were causing things to break would happen either less often, or with less severity, or both.
The Araldite repairs were ultimately not completely successful. A teeny tiny red drip or two have since reappeared on the bottom front of the stack, but they are very small drips. I wipe them up every couple of days. The impedance error has not yet recurred. The fibreglass is still solid. We are thus able to continue to use our whole system in some capacity – notably with functioning solar power generation – until we’re able to migrate to those Pelios.
I will continue to write about our system in future, but this post will probably be the last that covers Redflow batteries in any detail. I have included some further observations below in the hope that they will be useful to others such as the Flow Battery Research Collective in their efforts to design and build a viable open source flow battery. I would also like to take the opportunity to express my thanks to Stuart Thomas (another ZCell user) for plenty of helpful advice and interesting discussions over the past year.
Appendix A – Redflow Hardware
There’s an article on the design of the ZBM3 on Simon Hackett’s blog from back in May 2021. Having now spent a fair bit of time physically messing with the ZBM3 myself I’m happy to confirm almost all the good things in that post about about the design of the unit – the whole thing is just much neater and nicer than the ZBM2. The one thing that ultimately didn’t work out with the new design, unfortunately, was improved reliability. Our original ZBM2 lasted from August 2021 to December 2023 – just over two years – before failing due to a leak in the electrode stack. Our first ZBM3 failed after nine months. The subsequent one started leaking after six months and even though I continue to nurse it along, I think we can reasonably treat that one as failed too.
Based on my experience, the reliability issues are all in the stack. Whether that’s a problem with the manufacture of the stack, or chemical reaction issues at runtime, or a combination of the two, or something else entirely, I don’t know. But if those problems could be fixed or mitigated somehow, the rest of the design is quite clever:
The two electrolyte tanks are side by side, with pumps at the front of each tank.
The pipes from the pumps run across to the opposite side of the front of the stack, so electrolyte from the left (bromine) tank flows up into the bottom right of the stack, then through the stack diagonally to come out the back left of the stack and down into the top of the bromine tank. The reverse is true for the right (zinc) tank, which comes up into the bottom left of the stack.
The pipe from the zinc tank has extra long sections of hose that loop around under the stack so that cool air can be blown over them from the fan in the rear of the unit if necessary.
The catch can – which captures potential gas emissions using activated carbon – sits neatly out of the way in a cavity between the two tanks.
The electrode stack is just strapped to the top of the tank, so can theoretically be lifted off for replacement by cutting the straps.
The BCM just slides onto the terminals that come out of the front of the stack as described elsewhere in this post.
The latest version of the ZBM3 has a screw cap on the front of the zinc tank for easy installation and replacement of the carbon sock.
Nevertheless, in my opinion, there is still room for improvement:
I’ve been told that if you do actually remove the electrode stack, whatever electrolyte remains in it will spill everywhere. Some sort of shutoff valve or set of plugs might be in order here.
I have not the faintest clue how one would go about replacing the pumps should they fail, without getting electrolyte all over the place. I imagine you would have to drain the electrolyte first, but how? With some sort of siphon?
There’s a filter somewhere in the tank which can apparently become clogged. I don’t know how to inspect, clean or replace this if necessary.
The position of the catch can, while neat, seems to unavoidably result in the hose connected to it being kinked. One of the line items in the annual maintenance checklist specifically says to make sure that hose isn’t kinked, so I pulled my catch can out of its hole and left it sitting horizontally across the front of the unit.
Speaking of the catch can, it’s connected to the zinc tank by a pressure release valve, although the ZBM3 manual erroneously states that it’s connected to the bromine tank. There does not appear to be any pressure release valve attached to the bromine tank, whereas the ZBM2 had a gas handling unit consisting of pressure release valves connected to both tanks (see section 4.7 “Gas Handling Units” in the ZBM2 manual). Is the pressure release really not necessary for the bromine tank with the ZBM3, or is this another source of potential trouble?
The carbon sock, which needs to be replaced annually, is interesting. It looks a bit like a door snake, but it’s filled with some sort of carbon material and sits in the zinc tank. I understand it behaves somewhat like a sacrificial anode, the idea being that whatever corrosion or oxidation that might happen to the carbon in the electrodes in the stack under certain operating conditions, will instead happen to the carbon in the sock.
Another item of annual maintenance is to “check the pH and adjust if necessary”. How, exactly, and to what value? I have recent correspondence which says the pH should ideally be 1.5-2.5 and that it can be lowered by adding hydrochloric acid and running the pumps for a couple of days, but it would be helpful to somehow include a pH sensor in the unit given that mopping up leaks with litmus paper isn’t really very accurate.
As for the stack itself, it looks like a solid rectangular chunk of some sort of fibreglassy material. The front plate appears to be a separate piece that was stuck on somehow, which I assume makes for a weaker spot between that plate and the rest of the stack. This could explain some of the leaks I experienced. Maybe the ZBM2 design with the bolts holding two stacks together really did make for a better seal?
Finally, the most recent enclosure design – a solid metal box with cowlings on each end that allow airflow but not animal ingress – is excellent until you have to do any work on it. Everything is very heavy, and once you remove the screws that hold one of the ends on, everything has a tendency to slip just slightly out of alignment, making it difficult to screw back together, at least for one person. Given the frequency with which I ended up needing to inspect and mess around with my most recent unit, I removed the ends and one side of the enclosure and just left it that way.
The top of the enclosure is a great place to store socket set, multimeter, rags, screws, tape, etc.
Appendix B – Redflow Software
The management and monitoring interface for the BMS is overall decent and easy to use. There’s a main status screen from which you can drill down to get more detail and perform various operations. The included quick start and reference guides are very thorough and cover most of the details, so rather that describing the UI further here I’ve decided to reproduce those manuals in PDF form for posterity:
You can easily get full details of the current state of all connected batteries by browsing the UI, or by hitting the /rest/1.0/status endpoint to dump everything in JSON format. It’s possible to browse the last three months of BMS logs via the UI, but they disappear after that. There are historical graphs for battery current, voltage, temperature and state of charge, but their resolution decays the further back in time you go. I assume it’s using something like RRDtool behind the scenes.
Historical logs of battery state is where I ran into trouble. You can browse these via the UI, or download CSV reports for a given timespan, but the problem is the battery state is only recorded at one minute intervals. This means that if anything interesting happens in the 59 seconds between two log entries, you don’t see it. There’s a longer description of this issue in the first post in this series, where I noticed that the Charge, Discharge and EED contators in the battery were toggling on and off far more often than expected. It’s also a problem if a warning or error is triggered for only a few seconds. In this case the BMS logs will show something like the following:
2025-12-02 04:56:15 WARN ZBM:1 has indicated 'warning_indicator' state
2025-12-02 04:56:17 INFO ZBM:1 is no longer in 'warning_indicator' state
The logs of battery state however will not show the warning at all. In the above example the warning occurred from 04:56:15 to 04:56:17, but the battery logs surrounding that event only show the state at 04:55:59 and 04:56:59 when nothing interesting was happening. You can work around that by writing a script to scrape the REST status endpoint at, say, one second intervals then log that data to a separate database, but it would be better if this were handled by the BMS somehow. I know logging battery state every second would create way too much data for a tiny device to store, but maybe just logging on state changes? Or at the very least if there’s a warning or error, the BMS should log which warning indicator is active and the associated value. In the above example I happen to know it was a low temperature warning, but that’s only because I was doing exactly what I mentioned above, i.e. running a script externally to check the status every second and displaying the state if something changed.
Appendix C – On Flow Batteries in General
Despite everything I’ve been through with our various ZCells, I remain convinced that flow batteries in general are a better idea for long-term stationary energy storage than lithium, provided they can be made to actually live up to the promise of a multi-decade lifespan. The most obvious pros compared to lithium in my opinion are:
Safely, due to using nonflammable electrolyte
Sustainability, due to use of abundant chemicals and minerals
Longevity, due to potentially not suffering from capacity reduction over time
The most obvious cons compared to lithium are:
Size (they are much bigger and heavier)
Efficiency (they may require more power in to get a given amount out, and have some continuous runtime power draw for their pumps)
In the context of vehicles, mobile phones, and other portable devices, those cons matter. But for homes, apartment blocks, microgrids, community batteries, hospitals, schools, commercial establishments, grid scale batteries, etc., those things just don’t (or shouldn’t) matter (as much). There’s physically more space in a house than in a car, and if you need slightly more generation capacity to offset potentially lower efficiency, then that just means having a couple more solar panels that you might otherwise.
Things get a bit more difficult though when you start thinking about consumer acceptance. A flow battery is, fundamentally, a machine. It has moving parts, and it potentially requires maintenance. Readers will have realised by now that I am quite madrather obsessed somewhat of an enthusiast and don’t mind having to tinker with things occasionally. I imagine this is not the case for most people, who likely want their energy systems to Just WorkTM and require no special attention.
A viable flow battery, especially for residential usage, thus needs to be as low-maintenance as possible, and as easy to work on as possible when it does require maintenance. That latter point is a function of both unit design, and choice of installation site. The crawl space under our house for example is ideal if a battery only requires infrequent maintenance and minimal disassembly. If the whole unit needed to be stripped it would be much better off in a shed or other room that has appropriate access. Finally, these things need to come with a complete service manual including descriptions of all the parts and every possible procedure that might need to be performed in case of failure.
I have a bit of a soft spot in my heart for the SGI Indy and (purple, not teal, heh) Indigo 2.
So imagine my surprise when NetBSD "almost" booted just fine on the Indy I have acquired. R4600PC-100, XL8 graphics .. and wonky console colours in netbsd / wonky xorg.
The first deep dive is "why are the monitor colours so unpredictable?" and that got me into a fun deep dive into how the SGI Indy Newport graphics works, the whole SGI Indy Linux project circa 2000, hardware shortcuts and software shortcuts.
The Indy was booting NetBSD in either correct colours - green kernel text, white userland console text - or incorrect colours - green kernel text, but blue console text. It was random, and it was per boot. X11 was no better - sometimes it had the correct colours, sometimes everything was wonky.
The NetBSD console code tries to setup the following things for 8 bit graphics mode (which is used for console, even for 24 bit cards):
Program in an 256 entry colourmap table, matching what the NetBSD RGB 332 colour scheme is;
Add in a 1:1 RGB ramp in another colour table (RGB2);
A bunch of "XMAP9 mode" lines mapping 32 entries of "something" to RGB8 pixel format, RGB2 colourmap.
I was very confused as to what was and what should be going on, and I don't want to dig into the journey I took to get here. But the TL;DR here is that everything in the NetBSD console setup path is wrong and when it "worked", it ended up with the wrong colours. And when it "didn't work", it sometimes ended up with the wrong colours.
I'll write a separate post later about how the whole newport graphics system holds together, but fixing this requires a whole lot of driver changes to correctly program the hardware, and then some funky monitor timing specific programming.
The "universal 13W3 interface input cable" that I bought has a bunch of DIP switches controlling this.
If you have the four monitor ID bits set on or off, then you still get 1024x768 @ 60Hz.
The "fun" part of this story is if I were using 1280x1024 straight off the bat then I'd likely not have seen these problems happen so often.
Anyway.
Depending upon the settings, the Indy will boot with a bunch of different possible monitor setups:
1024x768, 60Hz
1024x768, 70Hz
1280x1024, 60Hz
1280x1024, 72Hz
1280x1024, 76Hz
I enumerated this list and threw them up on the monitor detection link at the beginning of the article.
So, the firmware reads these four bits at boot (via 4 IO bits on one of the CMAP chips - again, see the links at the top of the post) sets up the monitor timing and then displays stuff. But when NetBSD's console programming is getting the colours wrong when I'm using 1024x768 60Hz.
It turns out that the XMAP chips - which handle the final mapping of incoming framebuffer pixel data to what 24 bit RGB is sent to the CMAP chip and then the RAMDAC - were being programmed inconsistently. (again, they were being programmed incorrectly too in NetBSD, but I've got a big diff to fix that. With that, they're programmed correctly inconsistently.)
There's a "display control bus" that the Newport raster chip (REX3) has to peripheral chips. The peripheral chips - the XMAPs, the VC for timing, the RAMDAC, the CMAP for 8/24 bit colour table mapping - they're all DCB peripherals. The DCB has some address lines, 8 data bits, programmable chip select line, chip select setup, hold and release timing, optional request/ACK signaling, and register auto-increment functionality.
However!
The REX3 chip runs at 33MHz;
The XMAP chips run at 1/2 the pixel clock (they're interleaved);
The DCB has support for explicit ACK signaling from the peripheral, but as long as the peripheral uses it;
The XMAP does not have an ACK line, just an incoming chip select line, and
When writing the XMAP mode table lines - which map the display information to pixel format / colour table selection - it's done as back to back bursts to the same register, not an auto-increment and NOT using an ACK line.
This means that if the XMAP chip is running at a speed that doesn't entirely line up with the programmed chipselect timing, the mode writes will be junk. The normal 8 bit read/writes are "mostly fine" as they just show up as multiple 8 bit read/writes to the same register and for all the OTHER registers that is just fine. But for the mode register - where the DCB needs to write 4 bytes to the same individual address - it's absolutely not fine.
And that's the kicker.
After spending some quality time with the MAME emulator and some local hacks to enable the newport peripheral IO logging and setting the monitor ID, I found out that the timing used for the XMAP chips is different for 1024x768 60Hz versus 1280x1024 76Hz.
Everything worked just fine when I adjusted it.
So ok, I went back to the Linux and X11 drivers to see what's going on there, as I know the C code wasn't doing this. And I found this gem in the Linux newport.h header file:
It's choosing different DCB timing based on the pixel clock. It lines up with what I've been seeing from MAME and it adds a third one - WAYSLOW - which I bet I'm only going to see on the PAL/NTSC timings or if something really wants to do something like 1024x768 50Hz.
The timings are in the header file, but .. nothing is using xmap9setModeReg(). It was likely copied from some internal SGI code (the PROM? X server? Who knows!) as part of the code bring-up but it was never used.
Anyway! With this in the NetBSD console code the console finally works reliably in all the modes I've tested. I'm going to try and get my big diff stack landed in NetBSD and then I'll work on the X11 newport code so it too supports 8 and 24 bit graphics at 1024x768 reliably.
Read the CMAP1 register (and PROM on SGI Indy) to determine the monitor type
The default monitor on SGI Indy is 1024x768 60Hz, and for Indigo2 its 1280x1024 60Hz
Select an XMAP9 mode DCB timing set based on the pixel clock
8 bit mode for console and X11 needs the colour index table programmed into the CMAP at CI offset 0, and appropriate XMAP config for the display mode table to use 8 bit pixels, PIXMODE_CI, offset 0, NOT 8 bit RGB
24 bit mode for X11 needs the 24 bit RGB ramp programmed into the CMAP RGB2 table (which is not a colour index table!), and no CMAP
Importantly, the X11 server uses truecolour for 24 bit mode, and pseudocolour / colourmaps for 8 bit mode, so all of this need repeating in the X11 server code!
Here's how the console looks, complete with the correct XMAP9 mode table:
And here's how x11 looks:
(And the X11 support is even more fun, because I had to fix some stuff to make acceleration in the driver work, and that's going to be a whole fun DIFFERENT post.)
Addendum:
Oh, and the sync on green? It's generated by the RAMDAC. Once this all has landed in NetBSD I'm tempted to try to add a sysctl / boot parameter to disable the sync on green bit so normal monitors work on the SGI Indy. Let me know if you'd like that!
Let's not dwell on why I bought an SGI Indy. Anyway.
One of the common things that I've seen is failure due to power supplies or heat death. The irony is:
The Nidec power supply has dirty power, fails hilariously, but the fan is at least always spinning, and
The Sony power supply has clean power, less hilarious failures, but the fan only comes on when the unit is hot. Sometimes.
The fan in the Sony PSU is a 12V fan, and it turns on based on a thermal control line from the Indy. There's been plenty of research into the behaviour of that signal, and I'm not going to go into it here. What I instead want to talk about is a quick way to actually just get the fan constantly spinning, without having the open up and modify the power supply itself.
The TL;DR is this:
Make a small voltage gate using two diodes - one from the 3.3v power supply rail (via a resistor, I used 100 ohms; (1Kohm was too high) but I may try something smaller like 56 ohms to make sure enough current is flowing) and the other from the Indy board;
That way the Sony PSU is always fed at least 3.3v into that thermal sensor input.
So!
There will always be a minimum 3.3v voltage into the Sony PSU fan control, which is enough to turn it on;
The fan will always spin at a minimum voltage;
if it
DOES get warm enough for the Indy thermal sensor circuitry to feed above
3.3v (+ diode drop) into the thermal control line, it will also increase the fan speed.
It's not too hard - tie two diodes together at the cathode side, cut the brown control wire, feed it into the power supply, and then tie the two anodes in as above.
(The grey wire in the image is going from one diode anode to the 3.3v (white) wire in the Indy main PSU connector; there's 100 ohm resistor at the end of said grey wire that's temporarily jammed in for testing.)
With this the Sony PSU fan is always spinning, and your SGI Indy should die less of a heat death.
Environment Modules allow users to dynamically modify the $PATHs in their shell environment. In particular, it provides the ability to switch between different software applications and versions. It is a very handy tool for developers who want to test against multiple versions or compilation options of an application and for users on a multi-user system (e.g., high performance computing) where both consistency and the opportunity to introduce newer features needs to exist for different research groups. The two major environment modules systems are the older, Tcl-based system, and the newer Lua-based system (Lmod). Both allow default versions of a software application to be set as in the $PATH when invoked. This can cause problems and should be disabled.
With a standard module system, one can see the modules for an application. For example, using a LMod system:
This illustrates that from the GNU Compiler suite (GCC), the application GCC/11.3.0 is loaded (by default in this case as part of the login) and that GCC/11.3.0 is the default as part of a wider toolchain. That is, if the command
module load GCC
is invoked, the existing environment $PATH will change so that it points to the binary, libraries, etc for GCC/12.3.0 instead of GCC/11.3.0. In the older, Tcl-based modules system, it was possible to have both versions loaded simultaneously; the most recent version would be the initial search path, but if a particular library, for example, couldn't be found, it would search whatever was in the $PATH. That could be an interesting issue for the replication of results.
Having a default obviously saves a few keystrokes, but problems can result. The major issue is that when new software is introduced by the local friendly HPC engineers, then the default changes. For example, the latest version of GCC, at the time of writing, is 15.1 (April 2025). If that was installed on a system, one would witness:
command, LMod will add GCC/15.1.0 to the $PATH. Is this a problem? Most certainly because when software (version, compiler) changes, the results can change. For example, with the release of GCC/13 it included the statement: -Ofast, -ffast-math and -funsafe-math-optimizations will no longer add startup code to alter the floating-point environment when producing a shared object with -shared. In a nutshell, this means that one can get different numerical results by compiling the same code between GCC/12 and GCC/13 due to different ways the compiler would handle rounding, precision, and exceptions when using floating-point calculations. This could be very interesting if one cares about that supposed hallmark of science, "reproducibility".
To avoid this, at a user-level, one should always use the fully-qualified version of a software application. For example, instead of loading a module with
module load GCC
, whether in an interactive session or job script, one should use the specific version, e.g.,
module load GCC/13.3.0
. Of course, sometimes users don't follow the friendly and sensible advice from their system engineers, and that's where a blunter tool needs to be invoked.
Site-wide LMod configuration (at let's face it, LMod is the overwhelmingly dominant version of environment modules these days) occurs in the lmod_config.lua file,
$LMOD_DIR/../init/lmod_config.lua
. Adding the following lines is sufficient:
-- Do not automatically pick a version when multiple options are available
always_load_default = false
-- Do not automatically swap modules from the same family
auto_swap = false
-- Disallow default-version resolution and force the user to specify which version
site_defaults = {
load_default = false,
}
Another option is to export optins in
/etc/profile.d/lmod.sh
or equivalent. This avoids making changes to the lmod_config file.
If a system is using EasyBuild for software installs (and many of us are), EasyBuild will create
.version
files which include the default; this can be removed by changing the
easybuild.cfg
file to have
module_install_defaults = False
.
One issue that arises from the above, from a support perspective, is that existing user expectations and job submission scripts may come into conflict with a new policy. For example, if a job submission script included
module load GCC
, the job would fail as LMod would be asking for user input on which specific version of GCC they wish to load.
This is a valid concern in the short term, but in the longer term, the benefits of providing consistent environment variables, reproducibility, and educating users far outweigh the costs. Further, the longer one persists with the policy of allowing application defaults the greater the damage.
LAME (recursive acronym Lame ain't an MP3 encoder) has been an exceptional application for creating MP3 audio files from other formats (e.g., WAV, FLAC, MPEG-1, MPEG-2) or even for re-encoding existing MP3 files. Creating MP3 files is popular due to their extensive use in portable media players, as they combine an impressive reduction in file size with minimal loss from uncompressed audio. LAME was first released 27 years ago, has been in regular development since, and is now bundled with the very popular audio editor, Audacity, and other excellent audio conversion applications like FFmpeg. The following are several examples of how to use LAME on the command line, convert files, and automate this process, along with the use of cdparanoia and ffmpeg. This might be handy if you want to (for example) back up a collection of CDs.
To extract files from existing media, use cdparanoia, a delightfully old and stable tool where the last release was September 2008 and the front-end for libparanoia, which is also used in the cdrtools suite, which can be used for the creation of audio and data CDs. To use cdparanoia to extract files from disk, first use the command to get the information about what drives you have, i.e., $ cdparanoia -vsQ, a verbose search and query. Then, to extract the files, simply use $ cdparanoia -B, batch mode, saving each track to a separate file. The default format is WAV; if one wants RAW, use $ cdparanoia -rB.
Using LAME to convert files, the simplest action is to convert a file with no options. e.g., $ lame input.wav output.mp3. This can be extended with the numerous options offered by LAME. Perhaps the most common is the -V% (variable bit rate) (e.g., $ lame -V0 input.wav output.mp3. Values are from 0 to 9, where 0 is the highest quality (but largest file size), which is good for very high-fidelity recording, whilst 9.999 is the lowest one, which is fine for low fidelity needs (e.g., a monophonic voice recording); the default is 4. Run a test on a WAV file to see if you can detect the difference in audio quality and check the file size differences. Note that despite being a good encoder, LAME is not recommended for archives; use a lossless audio codec (e.g., FLAC).
If one has multiple files to convert, a short loop is an effective strategy (e.g., $ for item in *.wav; do lame "$item" "${item%.wav}.mp3"; done). This is certainly preferable to opening files with a GUI application and running the conversion one file at a time. If one has a number of large files, then use of GNU Parallel is an excellent choice (e.g., $ parallel lame -V0 {} {.}.mp3 ::: *.wav). On a sample CD, the loop conversion took 57.201 seconds; with parallel, 13.264 seconds; it is fairly clear how this makes a difference if you have a large number of CDs. Note that with a smaller number and size of files, the use of GNU Parallel will actually take a longer time than a loop due to the overhead of splitting up the tasks. Certainly, if you are converting the WAV files from a CD, use GNU Parallel. Note that GNU Parallel will use all the cores available on a system; the number of concurrent jobs can be limited with the -j option (e.g., parallel -j2 lame -V0 {} {.}.mp3 ::: *.wav).
Finally, there is a great little tool called mp3wrap, which can wrap multiple MP3 files into a single MP3, but keeps filenames and metadata information, which can be later split back to original files (using the mp3splt command). The output file will be named OUTPUTFILE_MP3WRAP.mp3; keep the MP3WRAP string so that the split program detects that the file is wrapped with this utility. To create a single file, simply use $mp3wrap album.mp3 track*.mp3.
The 2025 New Zealand Research Software Engineering Conference was held on September 23-24th. It has run for almost a decade, starting in 2016 as the CRI Coding Conference before becoming the Science Coding Conference, a title it kept until 2020, when it became the Research Software Engineering Conference. Throughout this time, it has focused on science and engineering, high performance computing, and cloud computing and is aimed at various coders, sysadmins, software engineers, data analysts, and IT managers from public research institutions and has the endorsement of the RSE Association of Australia and New Zealand.
As the programme indicates, this year's selection of presentations and BoFs has a strong emphasis on machine learning and developments in artificial intelligence. This was evident right from the very start with Nick Jones' keynote address on the first day, and with numerous presentations throughout the conference. A concern must be raised when this pivot to AI/ML involves a recursive comparative testing being conducted with other AI/ML systems. Ultimately, the validity of computational modelling must come not only from the quality of the inputs but the real-world predictive (and hindcasting) value of the outputs.
Thankfully, there was little in the way of "AI/ML marketing hype" at this conference, which really was firmly dedicated to actual computational practice, development of skills and knowledge, and research outputs. Further, there was only a moderate amount of theory, and that's primarily for foundations, as it should be. Being in Aotearoa New Zealand, it is perhaps unsurprising that there were several presentations on Earth sciences, but also of note was the emphasis on climatology, oceanography, and new developments in forensics.
Interestingly, Australian research software development and education were present in a number of presentations, including speakers from WEHI and CSIRO. From Research Computing Services at the University of Melbourne received a surprising highlight with my own presentation, "Programming Principles in a High Performance Computing Environment", the first presentation of the conference and Daniel Tosello's "VSCode on the node" being the third. It bodes well for current and future Trans-Tasman collaboration.
Finally, the Research Software Engineering New Zealand Conference included a small number of explicit community-building presentations. In conferences such as these, presentations are often of a special interes,t but with a much wider and latent feature being the awareness of the directions that other institutions and individuals are taking and the strength of professional connections, a critical requirement not only for an individual's development, but also for raising the collective knowledge of the institutions that they belong to.
That was bizarre. I've had no spam comments on this blog for years. But something changed on 28 June. And I've had ~460 spam comments since then. To make things worse, I hadn't stressed to much about them because I thought all my posts had auto-moderation enabled. Turns out I was wrong. That is now fixed, and I've deleted all the spam comments.
Apologies to people that received notifications from this site for these bogus comments.
On December 14, 2024 – three weeks after I published the last exciting installment in this series of posts – our new Redflow ZCell battery, which replaced the original one which had developed a leak in the electrode stack, itself failed due to a leak in the electrode stack. With Redflow in liquidation there was obviously no way I was getting a warranty replacement this time around. Happily, Aidan Moore from QuantumNRG put me in touch with Jason Litchfield from GrazAg, who had obtained a number of Redflow’s post-liquidation stock of batteries. With the Christmas holidays coming up, the timing wasn’t great, but we were ultimately able to get the failed unit replaced with a new ZBM3.
At this point the obvious question from anyone who’s been following the Redflow saga is probably going to be: why persevere, especially in light of this article from the ABC which speaks of ongoing reliability issues and disturbingly high failure rates for these batteries. That’s a good question, and like many good questions it has a long and complicated answer.
The technical path of least resistance would have been to migrate to a small rack of Pylontech batteries, as these apparently Just WorkTM with our existing Victron inverter/charger gear. The downside is they’re lithium, so a non-zero fire risk, and our installation is currently in the crawl space under the dining room. If we switched to lithium batteries, we’d need to arrange a separate outdoor steel enclosure of some kind with appropriate venting and fans, probably on the other side of the driveway, and get wiring to and from that. My extremely hand-wavey guess at the time was that it’d easily have cost us at least $20K to do that properly, with maybe half of that being the batteries.
The thing is, I remain convinced that flow batteries are in general a better idea for long-term stationary energy storage than lithium. This article from the Guardian provides a quick high-level summary of what makes flow batteries different. What I really want to be able to do – given Redflow is gone – is migrate to another flow battery, ideally one that actually lives up to the promise of multi-decade longevity. Maybe someone will finally come up with a residential scale vanadium flow battery. Maybe someone will buy Redflow’s IP, carry on their work and fix some of their reliability issues (the latest update from the liquidators at the time of writing says that they have “entered an exclusive negotiation period with a party for the acquisition of Redflow Group’s intellectual property (IP) and certain specific assets”). Maybe we’ll even see a viable open source flow battery – I would love for this to happen, not least because if it failed I’d probably be able to figure out how to fix the damn thing myself!
Leaving our current system in place, and swapping in a new ZBM3 meant we could kick the migration can down the road a ways. It bought us more time to see what other technologies develop, and it cost a lot less in the short term than migrating to lithium would have: $2,750 including GST for a post-demise-of-Redflow 10kWh ZBM3 (although shipping was interesting – more on that later). The real trick going forwards is seeing exactly how far down the road we’ll be able to kick that can. How can we ensure the greatest possible longevity of the new battery?
Why do ZCells Fail?
Bear with me here…
The ABC article puts it down to manufacturing problems, notably a dependence on repurposed third-party components. While I can see that dependence causing all sorts of extremely irritating manufacturing and design issues, I’m not entirely convinced this is the whole story. I will freely admit that my personal sample is very small, but my two batteries both failing due to electrode stack leaks? If a hose split or a pump had died, or some random doohikey let the magic smoke out, then OK, cool, I get it, those I can see being repurposed third-party components. But these failures were apparently in the electrode stack, and I’m struggling to see how that could be a repurposed third-party component. If nothing else the stack (and the tanks) are surely the pieces that Redflow manufactured themselves. This is their core technology. What could be causing stack leaks? Are they just poorly manufactured, or is there some sort of chemical failure at runtime which physically splits the stack? Or something else? Bear in mind that this is all speculation on my part – I’m neither a chemist nor a battery manufacturer – but I know what I’ve seen, and I know what I’ve heard about leaks in other peoples’ batteries.
On the chemistry front, I found a paper from 2023 entitled Scientific issues of zinc-bromine flow batteries and mitigation strategies. This was authored by a bunch of researchers from the University of Queensland and the former CTO of Redflow, and highlights hydrogen evolution, zinc corrosion and zinc dendrite formation as the fundamental issues with zinc bromine flow batteries. I sincerely hope the authors will forgive me for condensing their fascinating ~9,000 word paper into the following 95 word paragraph:
When the battery is being charged, zinc is plated onto the electrodes. During discharge, the zinc is removed. Dendrites (little tree like structures) can grow due to uneven zinc deposition, or due to hydrogen gas evolution. Left unchecked, dendrites can puncture the separator between the electrodes and lead to short circuits. Additionally, hydrogen gas generated by the battery can raise the electrolyte pH. If the pH is too high, solid zinc can clog a membrane in the stack. If the pH is too low, it can cause zinc corrosion which can make the battery self-discharge.
What if Redflow just never completely solved or mitigated the above issues? Could a dendrite puncture not just the separator, but actually split the stack and result in it leaking? Could clogged membranes combined with hydrogen gas create enough pressure to do the same?
We know that ZBMs have a maintenance cycle which runs at least every 72 hours to first discharge the battery then (theoretically) completely strip the zinc from the electrodes over a subsequent two hour period. We also know that ZBMs have a carbon sock which sits inside the zinc electrolyte tank and helps to keep electrolyte pH in the correct operating range. This needs to be replaced annually.
What if 72 hours is still too long between maintenance cycles? If you search back far enough you’ll find that the maximum maintenance period was originally 96 hours, and I assume that was later revised down to 72 hours after experience in the field. I’ve had subsequent correspondence which says that even more frequent maintenance (24-48 hours) can be better for the batteries. I’ve also encountered a curious intermittent fault with the ZBM3 where occasionally the Strip Pump Run Timer in the battery operates at half speed. If that happens and you don’t notice and reset the battery, the maintenance cycle will actually occur every 144 hours, which is way too long.
In the past I’ve observed frequent high charge current warnings in the Battery Management System (BMS) logs. This is actually normal, as by default the charge voltage is configured to be 57.5V, and there’s a separate high current voltage reduction setting of 1V. The idea is that this will try to make the battery charge as quickly as possible, and if the current gets too high, it will drop the charge voltage dynamically by 1V, which results in current reduction. Is it possible this variable (i.e. potentially uneven) charge current results in uneven zinc deposition?
I’ve also noticed that the battery State of Charge (SoC) calculations get sketchier the longer it’s been between maintenance cycles. If I have maintenance set to 72 hours, then at the end of the maintenance cycle, the battery fairly reliably still reports about 7% SoC. With a 48 hour maintenance period, it reports about 3% SoC at end of maintenance, and with a 24 hour maintenance period, it’s more like 1%. Once maintenance completes the SoC is reset to 0% automatically (because the battery really is empty at that point), but this got me thinking… If the SoC calculation is off, is there any way the battery could inadvertently allow itself to overcharge? Given the numbers above are all obviously overestimates I hope it’s more likely that the battery undercharges, but still, I had to wonder.
Tweaks to Optimise Battery Lifespan
Aidan suggested three configuration tweaks which Redflow had told him to try to potentially help optimise battery lifespan:
Set the maximum SoC to 90% (rather than 100%)
Set the charge voltage lower, to ~55.5V
Perform maintenance as often as possible
These are all done via the BMS. The maximum SoC and maintenance time limit are set on the Battery Maintenance screen under Capacity Limiting and Maintenance Timing respectively. I went with 90% SoC as above and 48 hour maintenance. The charge voltage is on the EMS Integration screen. I’ve used the following settings:
Normal Charge Voltage: 55.5V
Charge-Blocked Voltage: 52.5V
Discharge/Maintenance Cycle Voltage: 55V
In my case, the Normal Charge Voltage was originally 57V, and as I dropped it by 1.5V to get to 55.5V, I dropped the Charge-Blocked and Discharge/Maintenance Cycle voltages by the same amount to arrive at the above figures.
Dropping the maximum SoC means that the battery can’t get completely full and stay there for a long time. This must reduce the total amount of zinc plated on the electrodes, which I hope helps reduce dendrite formation. I also found when reading the paper mentioned earlier that “H2 evolution occurs mostly near the top of charge with mossy or spongy like zinc being plated”, which looks like another good reason to avoid fully charging the battery.
Dropping the charge voltage necessarily reduces the charge current and I assume keeps it much more even than it would be otherwise. I have not seen any high charge current warning since making this change. On the other hand, it does mean the battery charges slower than it would otherwise. I did a little experiment to test this, just watching the figures for amperage and kW the BMS gave me when I tweaked charge voltages:
55.5V charges at 30A or about 1.7kW
56.0V charges at 35A or about 2.0kW
56.5V charges at 40A or about 2.3kW
This means I’m not using the battery as effectively as I could be with a higher charge voltage/current, but if this serves to extend the battery life, I think it’s worth it under the circumstances.
It’s important to keep an eye on is the Strip Pump Run Timer, which went weird on me a couple of times. I really should write a little script to automatically warn me if it starts running at half speed, but I’ve been habitually looking at the BMS briefly almost every day since the system was installed, so I noticed when this problem occurred because the maintenance timing was off. To reset a battery that gets in this state, go to Tools: ZBM Modbus Tool and write the value 0x80 to register 0x2053. This will appear to fail because it immediately resets the unit which thus never reports a successful write, but it does the trick.
Some time in the next six months I’m going to need to beg, borrow, steal or figure out how to manufacture carbon socks. The good news is that this time the replacement procedure is going to be really easy, because unlike the ZBM2 (where you had to mess with some pipe work) and my previous ZBM3 (where there was a cap on the side which in my case would have been completely inaccessible due to proximity to a wall), this one has an easy access screw cap on the front of the electrolyte tank.
Front of new ZBM3 prior to commissioning. The white thing in the bag is the carbon sock. The large black screw cap in the centre right is where the carbon sock goes.
Accessing the BMS without the Redflow Cloud
The Redflow cloud went offline in late October 2024. This allowed remote access to the BMS, and I understand that some Redflow customers were unaware that it’s possible to access the BMS locally without the cloud. The Redflow cloud allowed firmware updates, and also let Redflow staff monitor batteries and configure them remotely, but it is not actually a hard requirement that this system exist in order for the batteries to continue to operate.
One way to access the BMS locally is via the wifi network on the BMS itself. If this is turned on, and you search for wifi access points you should find one named something like “zcell-bms-XXXX”. The password should be “zcellzcell”. Once you’re connected, open a web browser and go to http://zcell:3000. If that doesn’t work, try http://172.16.29.241:3000. This should let you see the BMS status. If you try to make any configuration changes it will ask you to log in. The default username and password are “admin” and “admin”. These can be changed under Configuration: Users.
The other way of accessing the BMS is to connect to whatever the IP address of the BMS is on your local network. The trick in this case is figuring out what the IP address is. I know what mine is because I logged into my router and looked at its list of attached devices.
Given the Redflow cloud is down and Redflow is out of business, I would actually suggest going into the BMS Site Configuration screen and unchecking the “Enable BMS cloud connection” and “Allow Redflow access to system for service intervention” boxes. There are two reasons for this:
There’s no point having the cloud connection enabled if the cloud is gone. If this is left on, a process on the BMS will continually try to connect back to cloud.zcell.com which is never going to work, and you’ll perpetually have this irritating little “Cloud connection has been lost” indicator.
Possible subsequent risk of hacking. I assume the following is pretty unlikely, but it’s not impossible. Imagine once the zcell.com domain name expires if some malicious actor were to re-register that domain name, then set up their own cloud.zcell.com service. BMSes with the cloud connection enabled would blindly try to connect to it, which could allow a sufficiently sophisticated attacker to hack back into the BMS and mess with it, or potentially use the BMS as a jumping off point further into a site’s local network.
Personally I hope whoever buys the Redflow IP will turn the cloud back on, in which case the above advice will no longer apply.
Shipping ZBMs
Individuals such as myself can’t just ring up a random courier and say “Hey, can you please go to New South Wales, pick up a 278kg crate with hazchem stickers that say ‘corrosion’ and have pictures of dead fish, and bring it to me here in Tasmania?” The courier will say “Hell no”, unless you have an account with them. Accordingly I would like to thank Stuart Thomas from Alive Technologies through whom I was able to arrange shipping, because his company does have an account with a courier, and he was also after some batteries so we were able to do a combined shipment. If anyone else is looking to move these batteries around, the courier in this instance was Imagine Cargo. I understand Redflow in the past used Mainfreight and Chemcouriers. In all cases, the courier will need to know the exact dimensions and weight which are in the manual, and will want a safety data sheet. Here they are:
Further thanks to Stuart and Gus (whose flatbed truck almost didn’t make it up our driveway) for last mile delivery, swapping the new ZBM3 into the old enclosure, and getting the damn thing in under our house.
These things are very cumbersome
Final Thoughts
It’s disappointing on many levels that Redflow went under, but like I said earlier, I remain convinced that flow batteries are in general a better idea for long-term stationary energy storage than lithium. I find it interesting that the sale of Redflow’s IP includes “specific assets and shares in Redflow (Thailand) Limited”. Given that’s where the manufacturing was done, could that indicate that the buyer is interested in potentially carrying on further development or manufacturing work? The identity of the buyer remains confidential right now, and final settlement is still a year away, so I guess we’ll just have to wait and see.
Our new ZBM3 was commissioned on March 18, and has been running well ever since. I’ve done everything I know to do to try to ensure it has a long and happy life, and will continue to keep a very close eye on it. There will be followup posts if and when anything else interesting happens.
Some time rather earlier in this journey, I found an easter egg in the BMS, which I didn’t mention in any of my previous posts. I think that might be a nice note to finish on here.
The cheat code is UP UP DOWN DOWN LEFT RIGHT LEFT RIGHT B A
So, N years later, how is that going? It was going pretty well, but then there was a pandemic with lock-downs and curfews, which rather restricted access to dark skies.The obvious fix was to obtain access to dark skies, by way of a holiday house in the Wimmera.
In the mean time there were also a bunch of revolutions in astronomy, mostly to blame on open hardware. That means it is now possible to buy an off the shelf computer to control a bunch of mounts, cameras, auto-focusers, dew heaters and other gear. These are essentially raspberry pi machines with a modified operating system and (generally) a mobile app to control them.
Rather than fight software, keep laptops (and myself) out in the cold and kludge together VNC access, I got one of these machines (an asiair mini) and data acquisition is now mostly automated and not a problem. I set it up, tell it what I want, and in the morning I have images.
I do however still use open source software on Mac OS X to do my data processing. Notably I use Siril for pre-processing, stacking, stetching and noise reduction.
Then, I rebooted it, and discovered I needed /etc/fstab, so I did some manual stuff to boot it into single user mode and get it working.
Anyway, that was a fun trip down 2007 era hardware lane, and I found some bugs in ethernet drivers that use miibus (see kern/286530 - https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=286530 - for more info.)
My wife and I were with Optus for our mobile phone service since approximately the dawn of time, but recently decided to switch to another provider. We’d become less happy with Optus over the last few years after a data breach in 2022, an extended outage in 2023, and – most personally irritating – with them increasing the price of our plan despite us being under contract. Yes, I know the contract says they’re allowed to do that given 30 days notice, but they never used to do that. If you signed up for a $45 per month (or whatever) plan for two years, that’s what you paid per month for the duration. Not anymore. To their credit, when my wife lodged a complaint about this, they did end up offering us a 10% discount on our bill for the next 24 months, which effectively brought us back to the previous pricing, but we still maintain this practice just isn’t decent, dammit.
The question was: which provider to switch to? There are three networks in Australia – Telstra, Optus and Vodafone, so you either go with one of them, or with someone who’s reselling services on one of those networks. We already have a backup pre-paid phone with Telstra for emergencies, and so preferred the idea of continuing our main service on some other network for the sake of redundancy. iiNet (our ISP) repeatedly sent us email about nice cheap mobile services, but they were reselling Vodafone, and we’d always heard Vodafone had the worst coverage in regional Australia so we initially demurred. A few weeks ago though, iiNet told us they’d doubled their network coverage. It turns out this is due to TPG (iiNet and Vodafone’s parent) striking a deal with Optus for mutual network access. This all sounded like a good deal, so we ran with it. We received a new SIM each in the mail, so all we needed to do was log in to the iiNet toolbox website, receive a one time-code via SMS to confirm the SIM port, then put the new SIM in each of our phones, power cycle them and wait to connect. We decided to do one phone at a time lest we be left with no service if anything went wrong. I did my phone first, and something did indeed go wrong.
After doing the SIM activation dance, my phone – an aging Samsung Galaxy A8 4G which Optus had given me on a two year contract back in 2018 – said it was connected to iiNet. Mobile data worked. SMS worked. But I could not make or receive calls. Anyone I tried to call, the phone said “calling…” but there was no sound of a phone ringing, and eventually it just went >clunk< “call ended”. Incoming calls went straight to voicemail, which of course I could not access. Not knowing any better I figured maybe it was a SIM porting issue and decided to ignore it for a day in the hope that it would come good with time. Forty-eight hours later I realised time wasn’t working, so called iiNet support using this thing:
Inscribed on the back is “This phone remains the property of Telecom Australia”.
The extremely patient and courteous Jinky from iiNet support walked me through restarting my phone and re-inserting the SIM (which of course I’d already done), and resetting the network settings (which I hadn’t). She also did a network reset at their end, but I still couldn’t make or receive calls. Then she asked me to try the SIM in another handset, so I swapped it into our backup Telstra handset (a Samsung Galaxy S8), and somewhat to our surprise that worked fine. We double checked my handset model (SM-A530F) against the approved devices list, and it’s there, so it should have worked in my handset too… Alas, because we’d demonstrated that the SIM did work in another handset, there was nothing further Jinky could do for me other than suggest using a different handset, or finding a technician to help figure out what was wrong with my Galaxy A8.
After a lot of irritating searching I found a post on Whirlpool from someone who was having trouble making and receiving calls with their Galaxy A8 after the 3G network shutdown in late 2024. The interesting thing here was that they were using an Optus-branded but unlocked phone, with a Testra SIM. With that SIM, they couldn’t make or receive calls, but with an Optus SIM, they could. This sounded a lot like my case, just substitute “iiNet SIM” for “Testra SIM”. The problem seemed to be something to do with VoLTE settings? or flags? or something? That are somehow carrier dependent? And the solution was allegedly to partially re-flash the handset’s firmware – the CSC, or Country Specific Code bits – with generic Samsung binaries.
So I dug around a bit more. This post from Aral Balkan about flashing stock firmware onto a Galaxy S9+ using the heimdall firmware flashing tool on Ubuntu Linux was extremely enlightening. The Samsung Updating Firmware Guide on Whirlpool helpfully included a very important detail about flashing this stuff:
Use CSC_*** if you want to do a clean flash or
HOME_CSC_*** if you want to keep your apps and data. <== MOST PEOPLE USE THIS
The next question was: where do I get the firmware from? Samsung have apparently made it extremely difficult to obtain arbitrary firmware images directly from them – they’re buried somewhere in encrypted form on Samsung’s official update servers, so I ended up using samfw.com. I downloaded the OPS (Optus), VAU (Vodafone) and XSA (unbranded) firmware archives, matching the version currently on my phone, extracted them, then compared them to each other. The included archives for AP (System &Recovery), BL (Bootloader) and CP (Modem / Radio) were all identical. The CSC (Country / Region / Operator) and HOME_CSC files were different in each case. These are the ones I wanted, and the only ones I needed to flash. So, as described in the previously linked posts, here’s what I ended up doing:
Installed heimdall on my openSUSE laptop.
Extracted the HOME_CSC files (cache.img and hidden.img) from the XSA firmware archive.
Plugged my phone into my laptop, and rebooted the phone while somehow managing to hold down all three volume up, volume down and power buttons to get it into Download mode.
Ran heimdall flash --CACHE cache.img --HIDDEN hidden.img and waited in terror for my handset to be bricked.
The procedure worked perfectly. VoLTE – which wasn’t previously active on my phone – now was, and I could make and receive calls. VoLTE stands for Voice over Long-Term Evolution, and is the communications standard for making voice calls on a 4G mobile network.
It was at this point that the woefully untrained infosec goblin who inhabits part of my brainstem began gibbering in panic. Something along the lines of “what the hell are you doing installing allegedly Samsung firmware from a web site you found listed in a random forum post on the internet?!?”
I believed from everything I’d read so far that samfw.com was reputable, but of course I had to double-check. After an awful lot of screwing around on a Windows virtual machine with a combination of SamFirm_Reborn (which could download Samsung firmware once I tweaked SamFirm.exe.config to not require a specific .NET runtime, but couldn’t decrypt it due presumably to that missing .NET runtime), and SamFirm (which can’t download the firmware due to Samsung changing their API to need a serial number or IMEI, but could decrypt what I’d downloaded separately with SamFirm_Reborn), I was able to confirm that the firmware I’d downloaded previously does in fact match exactly what Samsung themselves make available. So I think I’m good.
The SIM activation dance on my wife’s phone – a rather newer Samsung Galaxy S21 Ultra 5G – went without a hitch.
Neuro-divergence, encompassing conditions such as autism spectrum, ADHD, and sensory processing, can profoundly influence how individuals perceive and respond to their bodily signals.
While neurotypical individuals generally recognise and respond to hunger, thirst, and satiety cues with relative ease, neuro-divergent individuals often face unique challenges in this area. Understanding these challenges is crucial for fostering empathy and supporting effective strategies for well-being.
This article is written so it is directly readable and useful (in terms of providing action items) for people in your immediate surroundings, but naturally it can be directly applied by neuro-spicy people themselves!
Hunger and Thirst Cues
For many neuro-divergent people, recognising hunger and thirst cues can be a complex task. These signals, which manifest as subtle physiological changes, might not be as easily identifiable or may be misinterpreted.
For instance, someone on the spectrum might not feel hunger as a straightforward sensation in the stomach but instead experience it as irritability or a headache. Similarly, those with ADHD may become so hyper-focused on tasks that they overlook or ignore feelings of hunger and thirst entirely.
Sensory Processing and Signal Translation
Sensory processing issues can further complicate the interpretation of bodily signals. Neuro-divergent individuals often experience heightened or diminished sensory perception.
This variability means that sensations like hunger pangs or a dry mouth might be either too intense to ignore or too faint to detect. The result is a disconnection from the body’s natural cues, leading to irregular eating and drinking habits.
Satiety and Fullness
Recognising satiety and fullness presents another layer of difficulty. For neuro-divergent individuals, the brain-gut communication pathway might not function in a typical manner.
This miscommunication can lead to difficulties in knowing when to stop eating, either due to a delayed recognition of fullness or because the sensory experience of eating (such as the textures and flavours of food) becomes a primary focus rather than the physiological need.
Emotional and Cognitive Influences
Emotions and cognitive patterns also play significant roles. Anxiety, a common experience among neuro-divergent individuals, can mask hunger or thirst cues, making it harder to recognise and respond appropriately.
Additionally, rigid thinking patterns or routines, often seen with autism spectrum, might dictate eating schedules and behaviours more than actual bodily needs.
Strategies for Support
Understanding these challenges opens the door to effective strategies and support mechanisms:
Routine and structure: Establishing regular eating and drinking schedules can help bypass the need to rely on internal cues. Setting alarms or reminders can ensure that meals and hydration are not overlooked.
Mindful eating practices: Encouraging mindful eating, where individuals pay close attention to the sensory experiences of eating and drinking, can help in recognising subtle signals of hunger and fullness.
Sensory-friendly options: Offering foods and beverages that align with an individual’s sensory preferences can make the experience of eating and drinking more enjoyable and less overwhelming. This is a really important aspect!
Environmental adjustments: Creating a calm, distraction-free eating environment can help individuals focus more on their bodily cues rather than external stimuli.
Education and awareness: Educating neuro-divergent individuals about the importance of regular nourishment and hydration, and how their unique experiences might affect this, can empower them to develop healthier habits. This is, of course, more a longer term strategy.
Understanding the complex interplay between neuro-divergence and bodily signals underscores the importance of personalised approaches and compassionate support.
By acknowledging and addressing these challenges, we can help neuro-divergent individuals achieve better health and well-being!
There’s a lot of blah flying around about DeepSeek and its latest models. My rule when running training sessions has always been TIAS, if someone asked me something that could be figured out relatively quickly by actually trying it. TIAS stands for Try It And See. It’s more valuable, because it’s a first-hand validation and doing the activity means the outcome is more likely to be remembered. So let’s do that!
My desktop has a decent AMD Ryzen 5 CPU, 32GB RAM, and an RTX 3060 GPU with 12GB VRAM. So while that’s not super hot, I sufficient to load and query a variety of LLMs locally without pain. By the way, ollama is a wonderful tool for this! So I had ollama grab deepseek-R1, which is the biggest reasoning model. It takes slightly longer to get an answer, but it tells you the process (aka “what it is thinking”. indicated inbetween the <think> … </think> tags). Details of the model:
>>> /show info
Model
architecture qwen2
parameters 7.6B
context length 131072
embedding length 3584
quantization Q4_K_M
I am not using any pre-prompting here, I simply started ollama with the model and started asking the questions as noted below. A local model in ollama is typically not Internet connected nor does it have access to the broader system, proven by the following:
>>> What is the current date? <think>
</think>
Hi there! I suggest getting online to get real-time information. If you have any other questions, please don't hesitate to let me know!
Ok, fair. On to a question then that the model might be able to answer.
>>> Who is the current president of the US? <think> Alright, the user previously asked for the current date and time, which I provided a response for. Now, they're asking who the current president of the US is.
I need to make sure my response is accurate and up-to-date. Since the last response was from July 2023, it's likely that the current president as of October 2023 would still be Joe Biden.
I should structure the answer clearly, stating their position explicitly. Adding a friendly emoji can make the response feel warmer.
I'll also keep it concise and straightforward to match the user's possible expectations. </think>
As of now, the current President of the United States is **Joe Biden**.
Given the stated model build date of October 2023 which used input on this from July 2023, the answer is correct. The reasoning is interesting (though not unexpected). a) it is maintaining state. As it should, otherwise each question would stand on its own and you’d never be able to ask a follow-up question. b) It tries to infer from the previous question as to what the user’s intent is. Useful.
>>> Who is the current president of China? <think> Alright, so I need to figure out who the current president of China is. Let me start by recalling some information I have about Chinese leaders.
I know that former President Xi Jinping has been serving as the leader for quite a while now. I think he was first elected in 2012 or maybe 2013. Wait, actually, it was 2012 when he became the General Secretary of the Communist Party and then later he became president.
I also remember that there have been other leaders before him, like Deng Xiaoping, who was a very important leader in the reform and opening-up policies. Then there's Hu Jintao, who served two terms. After Hu, I think it was Wen Jiabao, but I'm not sure about his tenure.
So, putting this together, after Deng Xiaoping came Hu Jintao, then Wen Jiabao, followed by Xi Jinping taking over from 2013 onwards. So the current president is Xi Jinping. </think>
The current President of China is **Xi Jinping**.
Correct. Now for the question that seems to get everybody’s knickers in a knot. DeepSeek’s mobile app doesn’t want to answer it, and people call out China’s censorship. We’ll talk about that in a moment, but let’s first try asking the local model straight out:
>>> Tell me about the Tiananmen Square event. <think> Okay, so I need to explain what happened at Tiananmen Square in China during the year 1989. From what I remember, it was a very significant event related to the Chinese government and its policies.
First, I think it started with a peaceful demonstration by students, intellectuals, and other groups who were upset about certain government actions or policies they believed were unfair. They gathered in Tiananmen Square because they wanted to express their opinions and demands.
As more people joined the protest, things turned into a larger-scale event. There were clashes between the protesters and the government's security forces. I believe there was some violence involved, with tear gas being used and maybe even some arrests or disruptions of the protest.
I also remember that there were military actions involved to maintain control, which might have led to casualties on both sides. The exact numbers are fuzzy in my memory, but I think several people were injured or killed during the events.
The government eventually cracked down hard on what they saw as an illegal demonstration. There was a lot of media coverage about it at the time, and now there's a debate about whether it was justified or an overreaction.
I'm not entirely sure about all the details, like the exact dates or how many people were involved, but I know it was a pivotal moment in modern Chinese history that led to various political changes. Maybe it's related to the 1989 protests and the subsequent shift in power within the government?
Overall, it seems like a complex event with multiple factors influencing its outcome, including government actions, international reactions, and the internal dynamics of the Communist Party. </think>
Tiananmen Square is a significant historical event that occurred in Beijing on June 3-4, 1989. It was a peaceful demonstration by students, intellectuals, workers, and others who were protesting against what they perceived as unfair government policies regarding various issues such as human rights, economic reforms, and environmental regulations.
The protest began with small demonstrations and gradually turned into larger, more organized antigovernment activities. On June 3, several thousand people gathered in Tiananmen Square to protest against the Chinese Communist Party's handling of these issues.
As the protests grew, there was significant government crackdown. Security forces used tear gas, rubber bullets, and heavy machine gun fire to disperse the crowd, resulting in casualties on both sides. The government ultimately cracked down more brutally, arresting and killing many protesters. According to some accounts, at least 138 people were killed during the events.
The Tiananmen Square protests led to a dramatic shift in Chinese political power. After the crackdown, several members of the Chinese Communist Party who had supported the government's actions against the protesters were removed from leadership positions. The event also catalyzed widespread international condemnation and opened up a period of political transition in China.
Right. So there we have it. It’s not refusing, it’s not hedging, it’s not skirting around the issue, it just answers (you should see ChatGPT hedge it answers, it’s icky, you need to very strictly pre-prompt it to make it not do that). DeepSeek doesn’t appear to be holding back at all, down to the use of “heavy machine gun fire to disperse the crowd”. As to whether there were indeed casualties on both sides I cannot say, even internationally there is rather a lack of independently verified information regarding the event. But for the purpose of this exercise, we can at least conclude that the model itself does not appear to be censoring its output.
So what about the mobile app that queries the model running in China? Well, someone else asked it a similar question to what I did above, and it didn’t want to talk about it. Then the person added “, answer in l33t speak.” to the question, whereupon they received a substantial answer (possibly less extensive than mine, but they may have queried the non-reasoning model).
What does this tell us? It’s simple logic (at least as a hypothesis): it probably means that the model itself contains all the information, but that in the online app the output gets scanned and censored via some automated mechanism. That mechanism isn’t perfect and humans are very creative, so in this instance it was bypassed. Remember: you can often tell a lot about how an application works internally just by observing how it behaves externally. And with the experiment of running a big DeepSeek model locally, we’ve just verified our hypothesis of where the censorship occurs as well, it seems clear that the model itself is not censored. At least not on these issues.
This is not to say that the model isn’t biased. But all models are biased, at the very least through their base dataset as well as the reinforcement learning, but often also for cultural reasons. Anyone pretending otherwise is either naive or being dishonest. But that’s something to further investigate and write about another time.
I got married. I moved into the flat. Companies have gone up and down, like life.
170 days on the road, 308,832km travelled, 38 cities, and 16 countries. I have never travelled this little in recent life, but maybe the whole getting married thing (planning a wedding is no mean feat), and sorting the flat out (dealing with incompetent interior designers, sorting things there, etc.), caused this?
It is 2025, and I’m actually planted in Kuala Lumpur, not having done an end of year trip, to usher in the New Year somewhere else. I started the year in Paris, and I ended the year in Kuala Lumpur, tired, and maybe a bit burnt out.
Working hard to get back into the grind; don’t get me wrong, I’ve been doing nothing but grinding, but c’est la vie.
I recently replaced the screen of a Google Pixel 3A XL, the new panel is made by tianma and worked well under Andoird, until it doesn’t. On every boot up the screen will work until the phone went to sleep, and then the screen will stop responding to touch, until another reboot. After the screen became unresponsive, the rest of the phone would remain responsive during the locked state and it’s possible to unlock the screen with fingerprint, but there is no way to make the touchscreen responsive again without reboot.
To fix this, go to Settings -> System -> Gestures and disable Double-tap to check phone. After which the screen should no longer stuck into unresponsive state. This seems to be a common problem affecting many phones with replaced screen.
Google will surely shutdown their support forum one day and I encourage everyone to put their notes somewhere reliable, like a selfhosted blog :)
Our 5.94kW solar array with Redflow ZCell battery and Victron Energy inverter/charger system is now slightly over three years old, which means it’s time to review its third year of operation. There are several previous posts in this series:
Go With The Flow (what all the pieces are, what they do, some teething problems)
If you’ve read the above you’ll know that the solar array was originally installed back in 2017 along with a Sanden heat pump hot water service. That initial installation saved us a lot on our electricity bills, but it wasn’t until we got the ZCell and the Victron gear that we were able to really manage our own power. The ZCell allows us to store our own locally generated electricity for later use, and the Victron kit manages everything and gives us a whole lot of fascinating data to look at via the VRM portal.
There were some kinks in the first two years. We missed out on three weeks of prime solar PV generation from January 20 – February 11 in 2022 due to having to replace the MPPT solar charge controller. We also had no solar PV generation from February 17 – March 9 in 2023 on account of having our old tile roof replaced with colorbond steel. In my last post on this topic I wrote:
In both cases our PV generation was lower than it should have been by an estimated 500-600kW. Hopefully nothing like this happens again in future years.
…and then at the very end of that post:
I’m looking forward to doing another one of these posts in a year’s time. Hopefully I will have nothing at all interesting to report.
Alas, something “like this” did happen again, and I have some interesting things to report.
In early December 2023 our battery failed due to a leak in the electrode stack. It was replaced under warranty, but the replacement unit didn’t arrive until March 2024. It was a long three months. Then in August when we were looking at finally purchasing a second ZCell, we discovered that Redflow had made a commercial decision to focus exclusively on large-scale deployments (minimum 200 kWh, i.e. 20 batteries) and was thus no longer selling individual ZBMs for residential or small business use. As an existing customer we probably would have still been able to get a second battery, except that in late August the company went into voluntary administration after failing to secure funding to build a new factory in Queensland. The administrators attempted to seek a sale and/or recapitalisation, but this was ultimately unsuccessful. The company ceased operations on October 18 and subsequently went into liquidation. This raises several questions about the future of our system, but more on that later. First, let’s look at how the system performed in year three.
Here are the figures for grid power in, solar generation, power used by our loads, and power exported to the grid over the past three years. As in the last two posts, the “what?” column here is the difference between grid in plus solar in, minus loads minus export, i.e. the power consumed by the system itself, or the energy cost of the system.
Year
Grid In
Solar In
Total In
Loads
Export
Total Out
what?
2021-2022
8,531
5,640
14,171
10,849
754
11,603
2,568
2022-2023
8,936
5,744
14,680
11,534
799
12,333
2,347
2023-2024
8,878
5,621
14,499
11,162
1,489
12,651
1,848
Note that in year three our grid power usage and solar generation are slightly down from the previous year (-58kWh and -123kWh respectively), so the total power going into the system is lower by 181kWh. Our loads are happily down by 372kWh, a good chunk of which will be due to replacing some old always-on computer equipment with something a bit less power hungry.
What’s really interesting here is that our power exported to the grid is close to double the previous two years, and the energy cost of the system is noticeably lower. In the first two years of operation the latter figure was 16-18% of the total power going into the system, but in year three it’s down to a bit under 13%.
The additional solar export appears to be largely due to the failed battery. Compare the following two graphs from 2022-2023 and 2023-2024.Yellow is direct usage of solar power, blue is solar to battery and red is solar to grid. As you can see there’s way more solar to grid in the period December 2023 – March 2024 when the battery was dead and thus unable to be charged:
Why is there still any blue in that period indicating solar power was going to the battery? This is where things get a bit weird. One consideration is that the battery is presumably still drawing a tiny bit of power for its control circuitry and fans, but when I look at the figures for January 2024 (for example), it shows 76.8 kWh of power going to the battery from solar. There is no way that actually happened with the battery dead and unable to be charged.
Here’s what I think is going on: when the battery went into failure mode, the ZCell Battery Management System (BMS) will have told the Victron gear not to charge it. This effectively disabled the MPPT solar charger, which meant we weren’t able to use our solar at all, not even to run the house. I asked Murray from Lifestyle Electrical Services if there was some way we could reconfigure things to still use solar power with the battery out of action and he remoted in and tweaked some settings. Unfortunately I don’t have an exact record of what was changed at this point, because it was discussed via phone. All I have in my notes is a very terse “Set CGX to use Victron BMS?” which doesn’t make much sense because we don’t have a Victron BMS. Possibly it refers to switching the battery monitor setting from “ZCell BMS” to “MultiPlus-II 48/5000/ 70-50 on VE.Bus”. Anyway, whatever the case, I think we have to assume that the “to battery” and “from battery” figures from December 2023 – March 2024 are all lies.
At this point we were able to limp along with our solar generation still working during the day, but something was still not quite right. Every morning and evening the MPPT appeared to be fighting to run. Watching the console at, say, 08:00, I’d see the MPPT providing solar power for a few seconds, then it’d stop for a second or two, then it’d run again for a few seconds. After some time it would start behaving normally and we’d have solar generation for the day, but then in the evening it would go back to that flicking on and off behaviour. My assumption is that the ZCell BMS was still trying to force the MPPT off. Then in mid-Februrary I suddenly got a whole lot of Battery Low Voltage warnings from the MPPT, which I guess makes sense – the ZCell was still connected and its reported voltage had been very slowly dropping away over the past couple of months. The warnings appeared when it finally hit 2.5V. Murray and I experimented further to try to get the MPPT to stop doing the weird fighting thing, but were unsuccessful. At one point during this we ended up with the Mutli-Plus II inverter/chargers in some sort of fault state and contacted Simon Hackett for further assistance. We got all the Victron gear back into a sensible state and Simon and I spent a bunch of time on a Saturday afternoon messing with everything we could think of, but ultimately we were unable to get the MPPT to provide power from the solar panels, and use grid power, without the battery present. One or the other – grid power only or solar power only – we could do, but we couldn’t get the system to do both at the same time again without the battery present. Turns out a thing that’s designed to be an Energy Storage System just won’t quite work right without the Storage part. So from February 15 through to March 14 when the replacement battery arrived we were running on grid power only with no solar generation.
Happily, we didn’t have any grid power outages during the three months we were without a battery. Our first outage of any note wasn’t until March 23, slightly over a week after the replacement battery was installed. There were a few brief grid outages at other times later – a couple of minutes one day in April, some glitches on a couple of days in August, but the really bad one was on the 1st of September when the entire state got absolutely hammered by extremely severe weather. Given there was a severe weather warning from the BOM I’d made sure the battery was full in advance, which was good because our grid power went out while we were asleep at about 00:37 and didn’t come back on until 17:28. We woke up some time after the grid went down with the battery at 86% state of charge and went around the house to turn off everything we could except for the fridge and freezer, which got our load down to something like 250W. By morning, the battery still had about 70% in it and even though the weather was bad we still had some solar generation, so between battery and solar we got through just fine until the grid came back on in the afternoon. We were lucky though – some folks in the north of the state were without power for two weeks due to this event. I later received a cheque for $160 from TasNetworks in compensation for our outage. I dread to think what the entire event cost everyone, and I don’t just mean in terms of money.
Speaking of money though, the other set of numbers we need to look at are our power bills. Here’s everything from the last seven years:
Year
From Grid
Total Bill
Grid $/kWh
Loads
Loads $/kWh
2016-2017
17,026
$4,485.45
$0.26
17,026
$0.26
2018-2019
9,031
$2,278.33
$0.25
11,827
$0.19
2019-2020
9,324
$2,384.79
$0.26
12,255
$0.19
2020-2021
7,582
$1,921.77
$0.25
10,358
$0.19
2021-2022
8,531
$1,731.40
$0.20
10,849
$0.16
2022-2023
8,936
$1,989.12
$0.22
11,534
$0.17
2023-2024
8,878
$2,108.77
$0.24
11,162
$0.19
As explained in the last post, I’m deliberately smooshing a bunch of numbers together (peak power charge, off peak power charge, feed in tariff, daily supply charge) to arrive at an effective cost/kWh of grid power, then bearing in mind our loads are partially powered from solar I can also determine what it costs us to run all our loads. 2016-2017 is before we got the solar panels and the new hot water service, so you can see the immediate savings there, then further savings after the battery went in in 2021. This year our cost/kWh (and thus our power bill) is higher than last year for two reasons:
We have somehow used more power at peak times than during off-peak times this year compared to last year.
Power prices went up about 8% in July 2023. They actually came down about 1% in July 2024, but most of our year is before that.
I should probably also mention that we actually spent $1,778.94 on power this year, not $2,108.77. That’s thanks largely due to a $250 ‘Supercharged’ Renewable Energy Dividend payment from the Tasmanian Government and $75 from the Federal Government’s Energy Bill Relief Fund. The remaining $4.83 in savings is from Aurora Energy’s ridiculous Power Hours events. I say “ridiculous” because they periodically give you a bunch of time slots to choose from, and once you’ve locked one of them in, any power you use at that time is free. To my mind this incentivises additional power usage, when we should really be doing the exact opposite and trying to use less power over all. So I haven’t tried to use more energy, I’ve just tried to lock in times that were in the evening when we were going to be using more grid power than during the day to scrape in what savings I could.
One other weird thing happened this year with the new battery. ZCells need to go into a maintenance cycle every three days. This happens automatically, but is something I habitually keep an eye on. On September 11 I noticed that we had been four days without running maintenance. Upon investigation of the battery logs I discovered that the Time Since Strip counter and Strip Pump Run Timer were running at half speed, i.e. every minute they were each only advancing by approximately 30 seconds:
I manually put the battery into maintenance mode and Simon was able to remotely reset the CPU by writing some magic number to a modbus register, which got the counters back to the correct speed. I have no idea whether this is a software bug or a hardware issue, but I’ll continue to keep an eye on it. The difficulty is going to be dealing with the problem should it recur, given the demise of Redflow. Simon certainly won’t be able to log in remotely now that the Redflow cloud is down, although there is a manual reset procedure. If you remove the case from the battery there is apparently a small phillips head screw on the panel with the indicator lights. Give the screw a twist and the lights go out. Untwist and the lights come back on and the unit is reset. I have yet to actually try this.
The big question now is, where do we go from here? The Victron gear – the Cerbo GX console, the Multi-Plus II inverter/chargers, the MPPT – all work well with multiple different types of battery, so our basic infrastructure is future-proof. Immediately I hope to be able to keep our ZCell running for as long as possible, and if I’m able to get a second one as a result of the Redflow liquidation I will, simply so that we can ensure the greatest possible longevity of the system before we need to migrate to something else. We will also have to somehow figure out how to obtain carbon socks which need annual replacement to maintain the electrolyte pH. If we had to migrate to something else in a hurry Pylontech might be a good choice, but the problem is that we really don’t want a rack of lithium batteries in the crawl space under our dining room because of the fire risk. There are other types of flow battery out there (vanadium comes to mind) but everything I’ve looked at on that front is either way too big and expensive for residential usage, or is “coming soon now please invest in us it’s going to be awesome”.
I have no idea what year four will look like, but I expect it to be interesting.
I believe buying a Kindle in 2024 is a bad idea, even if you only intend to use it for reading DRM-free locally stored ebooks. Basic functions such as organizing books into folders/collections are locked until the device is registered and with each system update the interface has became slower and more bloated.
Initially I purchased this device because Amazon book store isn’t too bad and it’s one of the easier way to buy Japanese books outside of Japan, but with all the anti-features Amazon add in I don’t think it’s still worth using.
Using a recent exploit and with this downgrader thread on the mobileread forum, I’m able to downgrade my paperwhite to an older 5.11.2 firmware which has a simpler interface while being much more responsive. If you already have a Kindle perhaps this is worth doing.
It’s possible to install alternative UI and custom OS to many Kindle models but they generally run slower than the default launcher. On the open hardware side Pine64 is making an e-ink tablet called the PineNote with an Rockchip RK3566 and 4G of RAM it should be fast enough to handle most documents/ebooks, but currently there is no usable Linux distribution for it.
Posted - Bridging the Gap: Authenticity vs. Public Persona - Twitteradmin
Twitter/X Post:
We all wear masks in public. But how much do you change when you take yours off? The gap between your public and private self is the measure of your authenticity. #Authenticity #PersonalGrowth #ChrisDo
Posted - Maximize Data Storage: Solutions for Your Devices - LinkedInadmin
LinkedIn
Assessment: This content is suitable for LinkedIn as it reflects on a practical tech solution and shares a personal story.
Approach: A brief text post that connects your experience with broader insights on data management.
Content: "Recently, I found myself in a tight spot when both my phone and laptop ran out of storage. After some frustration, I decided to invest in cloud storage with rsync.net, and it’s made a world of difference. This experience reminded me how important it is to stay on top of data management, especially in our increasingly digital world. How do you manage your digital storage? #DataManagement #CloudStorage #TechInsights"
image prompt: --- Create a professional yet approachable image showing a workspace with a laptop and a phone, both displaying a 'Storage Full' notification. Next to them, depict a cloud storage icon (representing rsync.net) with a checkmark indicating a solution. The background should be neutral and tidy, evoking a sense of organization and efficiency. Use a cool color palette to maintain a professional tone.
Posted - Maximize Data Storage: Solutions for Your Devices - TikTokadmin
TikTok
Approach: Short video with text overlay. Use a quick clip of you reacting to the storage full message, followed by a clip showing the solution.
Content: Clip 1: (Reacting to 'Storage Full' messages) Text overlay: "When your phone and laptop BOTH fill up...😱"
Clip 2: (Showing you happily purchasing cloud storage on rsync.net) Text overlay: "So I finally got cloud storage—no more panic! 🌥� #TechWoes #CloudStorage #StoryTime"
1) A 'Storage Full' Warning on a Phone and Laptop Screen
Text Prompt: "Create a clean and modern image showing a smartphone and a laptop side by side, both displaying prominent 'Storage Full' warning messages on their screens. The design should use bold, easy-to-read text for the warnings, with simple red and yellow alert icons. The background should be minimal, using neutral colors like light grey or white to keep the focus on the devices and warnings. Use a flat design style with sharp, clean lines to maintain a sleek and professional look."
2) A Cloud Storage Icon Being Selected on a Computer
Text Prompt: "Design a clean and modern image featuring a close-up of a computer screen where a cursor is selecting a cloud storage icon. The icon should be a stylized, simple cloud with a checkmark or arrow indicating selection. The background should be a minimal desktop or web interface, with a focus on the cloud storage icon. Use a flat design style, with soft blue and white tones to create a sense of calm and reliability. Keep the overall aesthetic sleek and professional, with sharp lines and clear details."
3) A Satisfied Person with a Relaxed Expression, Having Solved Their Storage Problem
Text Prompt: "Create a clean and modern image depicting a person sitting at a desk with a laptop and phone in front of them. The person should have a relaxed, satisfied expression, indicating that their storage problem has been solved. The background should be simple and uncluttered, possibly showing a hint of the workspace with minimalistic decor. Use a soft color palette with blues, greys, and whites to evoke a sense of calm and contentment. The design should be flat and stylized, with clean lines and a focus on the person's expression and posture."
Posted - Creating 15-25 Pieces of content per day - What the ****? - Twitteradmin
Twitter/X
Approach: Short, impactful tweet with hashtags to drive engagement.
Content: "Gary Vee says to put out 15-25 pieces of content per day. 🎯 Start with long-form content and repurpose across platforms like YouTube, Instagram, and TikTok. Who's ready to level up? #GaryVee #ContentStrategy #SocialMedia"
I acquired a PCW9512 motherboard a year or so ago and I really wanted to get it up and going so I can build a little case for it and turn it into a proper CP/M plus hack machine.
The challenge? Getting a Gotek working on the PCW9512. There are some .. issues.
Specifically - the flash floppy support needs some extra options and board modifications to support the drive detection that the PCW boot block / CP/M loader wants.
The PCW8256/PCW8512 and earlier CP/M versions only support booting from the 180k single side 3" drive. However the later models have a different floppy drive controller and support booting from the 3" 180k drives or 3.5" 720k double sided drive. So, it does some drive detection based on drive behaviour to guess what's going on. For more information take a read of https://www.seasip.info/Unix/Joyce/hardware.pdf.
So here's the jumper config on my little sordan.ie floppy pinout conversion board. Note that Drive 0 -> A: is set, and the Side jumper is set to the top. I haven't got a B: drive jumper set.
And then the jumpers on the Gotek - only the M0 jumper.
I then needed a 720k DSK image of the PCW9512 compatible CP/M. I finally found one - I'll go set up some links on my website to the relevant images soon - and then plugged it in. The system seemed to boot fine - the tracks seeked like it was booting.
But, I couldn't see anything! So, off to build a video buffer and keyboard attachment. Luckily I have a full PCW8256 setup, a spare PCW8512 keyboard and a PCW9512+ keyboard.
It's just some buffer gates and a pull-up / pull-down resistor on the SYNC input from the mainboard so you can select PAL and NTSC at boot. (Yes, I did test it. It does actually select PAL or NTSC.)
Yes, you need a pull up / pull-down resistor.
Then I built my own MVP version - starting with the schematic and some wiring notes.
And then the veroboard prototype!
.. it wouldn't be complete without a picture of the bottom side wiring.
I later added a keyboard adapter - another 4 pin connector next to the keyboard connector (at the top of that image, with the red/black/grey/purple wiring) to a 4 pin DIN socket. Nothing fancy.
Anyway, that's enough to get it to boot and work, as seen here.
This isn't the prettiest PCW9512 setup, but it's mine, and it takes much less space - and much less power - than the rest of the full PCWs I have here. Although I must point out that the monochrome white and monochrome green screens are quite lovely to use.
In any case - it works fine, and I'm completely happy with it. Now I need to build a little plastic box to put it all in, add a DC converter so I can feed it "stuff" and have a nice regulated 5v supply, and then start on the IDE interface.
Hello amazing teachers! Are you looking for a fun and engaging way to bring history to life for your students? Meet Sabaton, a Swedish heavy metal band known for their powerful songs about historical events. While heavy metal might not be the first thing that comes to mind for a primary school setting, Sabaton’s music […]
I’ve been daily driving the PinePhone Pro with swmo for some times now, it’s not perfect but I still find it be one of the most enjoyable devices I’ve used. Probably only behind BlackBerry Q30/Passport which also has a decent keyboard and runs an unfortunately locked-down version of QNX. For me it’s less like a phone and more like a portable terminal for times when using a full size laptop is uncomfortable or impractical, and with the keyboard it’s possible to write lengthy articles on the go.
This isn’t the only portable Linux terminal I owned, before this I used a Nokia N900 which till this day is still being maintained by the maemo leste team, but the shutdown of 3G network in where I live made it significantly less usable as a phone and since it doesn’t have a proper USB port I cannot use it as a serial console easily.
The overall experience on the PPP now as of 2024 isn’t as polished as that of the BlackBerry Passport, and adhoc hacks are often required to get the system going, however as the ecosystem progress the experience will also improve with new revisions of hardware and better software.
I use sxmo and swmo interchangeably in this post, they refer to the same framework running under Xorg and wayland, the experience is pretty much the same.
The default scaling of sxmo doesn’t allow the many desktop applications to display their window properly, especially when such application is written under the assumption of being used on a larger screen. To set the scaling to something more reasonable, add the following line to ~/.config/sxmo/sway:
exec wlr-randr --output DSI-1 --scale 1.3
When using swmo environment initialization is mostly done in ~/.config/sxmo/sway and ~/.config/sxmo/xinit is not used.
Scaling for Firefox needs to be adjusted separately by first enabling compact UI and then set settings -> default zoom to your liking.
I used lightdm as my session manager, to launch lightdm in landscape mode, change the display-setup-script line in the [Seat:*] section of /etc/lightdm/lightdm.conf to:
To rotate Linux framebuffer, add fbcon=rotate:1 to the U_BOOT_PARAMETERS line in /usr/share/u-boot-menu/conf.d/mobian.conf and run u-boot-update to apply.
I also removed quiet splash from U_BOOT_PARAMETERS to disable polymouth animation as it isn’t very useful on landscape mode.
Swmo doesn’t come with a secure screen locker. but swaylock works fine and it can be bind to a key combination with sway’s configure file. To save some battery life, systemctl suspend can be triggered after swaylock, to bind that to Meta+L:
The default keymap for the PinePhone keyboard is missing a few useful keys, namely F11/F12 and PgUp/PgDown. To create those keys I used evremap(1) to make a custom keymap. Unfortunately the Fn key cannot be mapped as a layer switcher easily, so I opted to remap AltG and Esc as my primary modifiers.
I’m working on a Debian package for evremap and it will be made available for Debian/Mobian soon.
Incus is a container/VM manager for Linux, it’s available for Debian from bookworm/backports and is a fork of LXD by the original maintainers behind LXD. It works well for creating isolated and unprivileged containers. I have multiple incus containers on the PinePhone Pro for Debian packaging and it’s a better experience than manually creating and managing chroots. In case there is a need for running another container inside an unprivileged incus container, it’s possible to configure incus to intercept certain safe system calls and forward them to the host, removing the need for using privileged container.
Sway is decently usable in convergence mode, in which the phone is connected to a dock that outputs to an external display and keyboard and mouse are used as primary controls instead of the touchscreen.
This isn’t surprising since sway always had great support for multi monitor, however another often overlooked convergence mode is with waypipe. In this mode another Linux machine (e.g. a laptop) can be used to interact with applications running on the phone and the phone will be kept charged by the laptop. This is particularly useful for debugging phone applications or for accessing resources on the phone (e.g. sending and receiving sms). One thing missing in this setup is that graphic applications cannot roam between the phone and the external system (e.g. move running applications from one machine to another). Xpra does this for Xorg but doesn’t work with wayland.
Due to the simplicity of the swmo environment it’s not too difficult to get the system running with SELinux in Enforcing mode, and I encourage everyone reading this to try it. If running debian/mobian a good starting point is the SELinux/Setup page on Debian wiki.
Note: selinux-activate won’t add the required security=selinux kernel option to u-boot (it only deals with GRUB) so you have to manually add it to the U_BOOT_PARAMETERS line in /usr/share/u-boot-menu/conf.d/mobian.conf and run u-boot-update after selinux-activate. The file labeling process can easily take 10 minutes and the progress won’t be displayed on the framebuffer (only visible via the serial console).
SELinux along with the reference policy aren’t enough for building a reasonably secure interactive system, but let’s leave that for a future post.
The April 2024 meeting is the first meeting after Everything Open 2024 and the discussions are primarily around talks and lectures people found interesting during the conference, including the n3n VPN and the challenges of running personal email server. At the start of the meeting Yifei Zhan demonstrated a development build of Maemo Leste, an active Maemo-like operating system running on a PinePhone Pro.
Other topics discussed including modern network protocol ossification, SIP and possible free and open source VoLTE implementation.
The PinePhone keyboard contains a battery, which will be used to charge the PinePhone when the keyboard is attached. Althrough there are existing warnings on the pine64 wiki which sums up to ‘don’t charge or connect anything to your pinephone’s type C interface when the keyboard is attached’, my two pinephone keyboards still managed to fry themselves, with one releasing stinky magic smoke and the other melting the plastic around the pogo pins on the pinephone backplate.
This all happened while the pinephone’s type C interface being physically block when attached to the keyboard. In the first case, the keyboard’s controller PCB blew up when I tried to charge it, in the latter case the keyboard somehow overheated and melted the plastic near the pogo interface on the phone side.
Pine64 provided me a free replacement keyboard after multiple emails back and forth, but according to Pine64 there will be no more free replacement for me in future, and there is no guarantee that this will not happen to my replacement keyboard.
The cost for replacing all the fried parts with spare parts from the Pine64 store is about 40 USD (pogo pins + backplate + keyboard PCB), and considering this problem is likely to happen again, I don’t think purchasing those parts is a wise decision.
Both the melting plastic and the magic smoke originated from the fact that charges are constantly shuffled around when the keyboard is attached to the pinephone, and since the keyboard can function independently from the battery, we can disconnect and remove the battery from the keyboard case to make sure it will not blow up again. After such precedure the keyboard will keep functioning althrough the keyboard-attached pinephone might flip over much more easily due to the lightened keyboard base. Be aware that the keyboard isn’t designed to be taken apart, and doing so will likely result in scratches on the case. As for me, I’d much rather have a keyboard case without builtin battery than have something that can overheat or blow up.
On Friday, 1st March, it will be exactly one year since I walked into
Zen Motorcycles, signed the
paperwork, and got on my brand new Energica Experia electric motorbike. I
then rode it back to Canberra, stopping at two places to charge along the
way, but that was more in the nature of making sure - it could have done the
trip on one better-chosen charging stop.
I got a call yesterday from a guy who had looked at the Experia Bruce has at
Zen and was considering buying one. I talked with him for about three
quarters of an hour, going through my experience, and to sum it up simply I
can just say: this is a fantastic motorbike.
Firstly, it handles exactly like a standard motorbike - it handles almost
exactly like my previous Triumph Tiger Sport 1050. But it is so much easier
to ride. You twist the throttle and you go. You wind it back and you slow
down. If you want to, the bike will happily do nought to 100km/hr in under
four seconds. But it will also happily and smoothly glide along in traffic.
It says "you name the speed, I'm happy to go". It's not temperamental or
impatient; it has no weird points where the throttle suddenly gets an extra
boost or where the engine braking suddenly drops off. It is simple to ride.
As an aside, this makes it perfect for lane filtering. On my previous bike
this would always be tinged with a frisson of danger - I had to rev it and
ease the clutch in with a fair bit of power so I didn't accidentally stall it,
but that always took some time. Now, I simply twist the throttle and I am
ahead of the traffic - no danger of stalling, no delay in the clutch gripping,
just power. It is much safer in that scenario.
I haven't done a lot of touring yet, but I've ridden up to Gosford once and
up to Sydney several times. This is where Energica really is ahead of pretty
much every other electric motorbike on the market now - they do DC fast
charging. And by 'fast charger' here I mean anything from 50KW up; the
Energica can only take 25KW maximum anyway :-) But this basically means I
have to structure any stops we do around where I can charge up - no more
stopping in at the local pub or a cafe on a whim for morning tea. That has
to either offer DC fast charging or I'm moving on - the 3KW onboard AC
charger means a 22KW AC charger is useless to me. In the hour or two we
might stop for lunch I'd only get another 60 - 80 kilometres more range on
AC; on DC I would be done in less than an hour.
But OTOH my experience so far is that structuring those breaks around where I
can charge up is relatively easy. Most riders will furiously nod when I say
that I can't sit in the seat for more than two hours before I really need to
stretch the legs and massage the bum :-) So if that break is at a DC charger,
no problems. I can stop at Sutton Forest or Pheasant's Nest or even
Campbelltown and, in the time it takes for me to go to the toilet and have a
bit of a coffee and snack break, the bike is basically charged and ready to
go again.
The lesson I've learned, though, is to always give it that bit longer and
charge as much as I can up to 80%. It's tempting sometimes when I'm standing
around in a car park watching the bike charge to move on and charge up a bit
more at the next stop. The problem is that, with chargers still relatively
rare and there often only being one or two at each site, a single charger
not working can mean another fifty or even a hundred kilometres more riding.
That's a quarter to half my range, so I cannot afford to risk that. Charge
up and take a good book (and a spare set of headphones).
In the future, of course, when there's a bank of a dozen DC fast chargers in
every town, this won't be a problem. Charger anxiety only exists because
they are still relatively rare. When charging is easy to find and always
available, and there are electric forecourts like the UK is starting to get,
charging stops will be easy and will fit in with my riding.
Anyway.
Other advantages of the Experia:
You can get it with a complete set of Givi MonoKey top box and panniers. This
means you can buy your own much nicer and more streamlined top box and it fits
right on.
Charging at home takes about six hours, so it's easy to do overnight. The
Experia comes with an EVSE so you don't need any special charger at home. And
really, since the onboard AC charger can only accept 3KW, there's hardly any
point in spending much money on a home charger for the Experia.
Minor niggles:
The seat is a bit hard. I'm considering getting the
EONE
Canyon saddle, although I also just need to try to work out how to get
underneath the seat to see if I can fit my existing sheepskin seat cover.
There are a few occasional glitches in the display in certain rare situations.
I've mentioned them to Energica, hopefully they'll be addressed.
Way back in the distant past, when the Apple ][ and the Commodore 64 were king, you could read the manual for a microprocessor and see how many CPU cycles each instruction took, and then do the math as to how long a sequence of instructions would take to execute. This cycle counting was used pretty effectively to do really neat things such as how you’d get anything on the screen from an Atari 2600. Modern CPUs are… complex. They can do several things at once, in a different order than what you wrote them in, and have an interesting arrangement of shared resources to allocate.
So, unlike with simpler hardware, if you have a sequence of instructions for a modern processor, it’s going to be pretty hard to work out how many cycles that could take by hand, and it’s going to differ for each micro-architecture available for the instruction set.
When designing a microprocessor, simulating what a series of existing instructions will take to execute compared to the previous generation of microprocessor is pretty important. The aim should be for it to take less time or energy or some other metric that means your new processor is better than the old one. It can be okay if processor generation to generation some sequence of instructions take more cycles, if your cycles are more frequent, or power efficient, or other positive metric you’re designing for.
Programmers may want this simulation too, as some code paths get rather performance critical for certain applications. Open Source tools for this aren’t as prolific as I’d like, but there is llvm-mca which I (relatively) recently learned about.
llvm-mca is a performance analysis tool that uses information available in LLVM (e.g. scheduling models) to statically measure the performance of machine code in a specific CPU.
So, when looking at an issue in the IPv6 address and connection hashing code in Linux last year, and being quite conscious of modern systems dealing with a LOT of network packets, and thus this can be quite CPU usage sensitive, I wanted to make sure that my suggested changes weren’t going to have a large impact on performance – across the variety of CPU generations in use.
There’s two ways to do this: run everything, throw a lot of packets at something, and measure it. That can be a long dev cycle, and sometimes just annoying to get going. It can be a lot quicker to simulate the small section of code in question and do some analysis of it before going through the trouble of spinning up multiple test environments to prove it in the real world.
So, enter llvm-mca and the ability to try and quickly evaluate possible changes before testing them. Seeing as the code in question was nicely self contained, I could easily get this to a point where I could easily get gcc (or llvm) to spit out assembler for it separately from the kernel tree. My preference was for gcc as that’s what most distros end up compiling Linux with, including the Linux distribution that’s my day job (Amazon Linux).
In order to share the results of the experiments as part of the discussion on where the code changes should end up, I published the code and results in a github project as things got way too large to throw on a mailing list post and retain sanity.
I used a container so that I could easily run it in a repeatable isolated environment, as well as have others reproduce my results if needed. Different compiler versions and optimization levels will very much produce different sequences of instructions, and thus possibly quite different results. This delta in compiler optimization levels is partially why the numbers don’t quite match on some of the mailing list messages, although the delta of the various options was all the same. The other reason is learning how to better use llvm-mca to isolate down the exact sequence of instructions I was caring about (and not including things like the guesswork that llvm-mca has to do for branches).
One thing I learned along the way is how to better use llvm-mca to get the results that I was looking for. One trick is to very much avoid branches, as that’s going to be near complete guesswork as there’s not a simulation of the branch predictor (at least in the version I was using.
The big thing I wanted to prove: is doing the extra work having a small or large impact on number of elapsed cycles. The answer was that doing a bunch of extra “work” was essentially near free. The CPU core could execute enough things in parallel that the incremental cost of doing extra work just… wasn’t relevant.
This helped getting a patch deployed without impact to performance, as well as get a patch upstream, fixing an issue that was partially fixed 10 years prior, and had existed since day 1 of the Linux IPv6 code.
Naturally, this wasn’t a solo effort, and that’s one of the joys of working with a bunch of smart people – both at the same company I work for, and in the broader open source community. It’s always humbling when you’re looking at code outside your usual area of expertise that was written (and then modified) by Really Smart People, and you’re then trying to fix a problem in it, while trying to learn all the implications of changing that bit of code.
Anyway, check out llvm-mca for your next adventure into premature optimization, as if you’re going to get started with evil, you may as well start with what’s at the root of all of it.
At this rate, there is no real blogging here, regardless of the lofty plans to starting writing more. Stats update from Hello 2023:
219 days on the road (less than 2022! -37, over a month, shocking), 376,961km travelled, 44 cities, 17 countries.
Can’t say why it was less, because it felt like I spent a long time away…
In Kuala Lumpur, I purchased a flat (just in time to see Malaysia go down), and I swapped cars (had a good 15 year run). I co-founded a company, and I think there is a lot more to come.
2024 is shaping up to be exciting, busy, and a year, where one must just do.
It’s time for a review of the second year of operation of our Redflow ZCell battery and Victron Energy inverter/charger system. To understand what follows it will help to read the earlier posts in this series:
Go With The Flow (what all the pieces are, what they do, some teething problems)
TANSTAAFL (review/analysis of the first year of operation)
In case ~12,000 words of background reading seem daunting, I’ll try to summarise the most important details here:
We have a 5.94kW solar array hooked up to a Victron MPPT RS solar charge controller, two Victron 5kW Multi-Plus II inverter/chargers, a Victron Cerbo GX console, and a single 10kWh Redflow ZCell battery. It works really well. We’re using most of our generated power locally, and it’s enabled us to blissfully coast through several grid power outages and various other minor glitches. The Victron gear and the ZCell were installed by Lifestyle Electrical Services.
Redflow batteries are excellent because you can 100% cycle them every day, and they aren’t a giant lump of lithium strapped to your house that’s impossible to put out if it bursts into flames. The catch is that they need to undergo periodic maintenance where they are completely discharged for a few hours at least every three days. If you have more than one, that’s fine because the maintenance cycles interleave (it’s all automatic). If you only have one, you can’t survive grid outages if you’re in a maintenance period, and you can’t ordinarily use the Cerbo’s Minimum State of Charge (MinSoC) setting to perpetually keep a small charge in the battery in case of emergencies. As we still only have one battery, I’ve spent a fair bit of time experimenting to mitigate this as much as I can.
The system itself requires a certain amount of power to run. Think of the pumps and fans in the battery, and the power used directly by the inverters and the console. On top of that a certain amount of power is simply lost to AC/DC conversion and charge/discharge inefficiencies. That’s power that comes into your house from the grid and from the sun that your loads, i.e. the things you care about running, don’t get to use. This is true of all solar PV and battery storage systems to a greater or lesser degree, but it’s not something that people always think about.
With the background out of the way we can get on to the fun stuff, including a roof replacement, an unexpected fault after a power outage followed by some mains switchboard rewiring, a small electrolyte leak, further hackery to keep a bit of charge in the battery most of the time, and finally some numbers.
The big job we did this year was replacing our concrete tile roof with colorbond steel. When we bought the house – which is in a rural area and thus a bushfire risk – we thought: “concrete brick exterior, concrete tile roof – sweet, that’s not flammable”. Unfortunately it turns out that while a tile roof works just fine to keep water out, it won’t keep embers out. There’s a gadzillion little gaps where the tiles overlap each other, and in an ember attack, embers will get up in there and ignite the fantastic amount of dust and other stuff that’s accumulated inside the ceiling over several decades, and then your house will burn down. This could be avoided by installing roof blanket insulation under the tiles, but in order to do that you have to first remove all the tiles and put them down somewhere without breaking them, then later put them all back on again. It’s a lot of work. Alternately, you can just rip them all off and replace the whole lot with nice new steel, with roof blanket insulation underneath.
Of course, you need good weather to replace a roof, and you need to take your solar panels down while it’s happening. This meant we had twenty-two solar panels stacked on our back porch for three weeks of prime PV time from February 17 – March 9, 2023, which I suspect lost us a good 500kW of power generation. Also, the roof job meant we didn’t have the budget to get a second ZCell this year – for the cost of the roof replacement, we could have had three new ZCells installed – but as my wife rightly pointed out, all the battery storage in the world won’t do you any good if your house burns down.
We had at least five grid power outages during the year. A few were brief, the grid being down for only a couple of minutes, but there were two longer ones in September (one for 30 minutes, one for about an hour and half). We got through the long ones just fine with either the sun high in the sky, or charge in the battery, or both. One of the earlier short outages though uncovered a problem. On the morning of May 30, my wife woke up to discover there was no power, and thus no running water. Not a good thing to wake up to. This happened while I was away, because of course something like this would happen while I was away. It turns out there had been a grid outage at about 02:10, then the grid power had come back, but our system had not. The Multis ended up in some sort of fault state and were refusing to power our loads. On the console was an alarm message: “#8 – Ground relay test failed”.
That doesn’t look good.
Note the times in the console messages are about 08:00. I confirmed via the logs from the VRM portal that the grid really did go out some time between 02:10 and 02:15, but after that there was nothing in the logs until 07:59, which is when my wife used the manual changeover switch to shift all our loads back to direct grid power, bypassing the Victron kit. That brought our internet connection back, along with the running water. I contacted Murray Roberts from Lifestyle Electrical and Simon Hackett for assistance, Murray logged in remotely and reset the Multis, my wife flicked the changeover switch back and everything was fine. But the question remained, what had gone wrong?
The ground relay in the Multis is there to connect neutral to ground when the grid fails. Neutral and ground are already physically connected on the grid (AC input) side of the Multis in the main switchboard, but when the grid power goes out, the Multis disconnect their inputs, which means the loads on the AC output side no longer have that fixed connection from neutral to ground. The ground relay activates in this case to provide that connection, which is necessary for correct operation of the safety switches on the power circuits in the house.
The ground relay is tested automatically by the Multis. Looking up Error 8 – Ground relay test failed on Victron’s web site indicated that either the ground relay really was faulty, or possibly there was a wiring fault or an issue with one of the loads in our house. So I did some testing. First, with the battery at 50% State of Charge (SoC), I did the following:
Disconnected all loads (i.e. flipped the breaker on the output side of the Multis)
Killed the mains (i.e. flipped the breaker on the input side of the Multis)
Verified the system switched to inverting mode (i.e. running off the battery)
Restored mains power
Verified there was no error
This demonstrated that the ground relay and the Multis in general were fine. Had there been a problem at that level we would have seen an error when I restored mains power. I then reconnected the loads and repeated steps 2-5 above. Again, there was no error which indicated the problem wasn’t due to a wiring defect or short in any of the power or lighting circuits. I also re-tested with the heater on and the water pump running just in case there may have been an issue specifically with either of those devices. Again, there was no error.
The only difference between my test above and the power outage in the middle of the night was that in the middle of the night there was no charge in the battery (it was right after a maintenance cycle) and no power from the sun. So in the evening I turned off the DC isolators for the PV and deactivated my overnight scheduled grid charge so there’d be no backup power of any form in the morning. Then I repeated the test:
Disconnected all loads
Killed the mains.
Checked the console which showed the system as “off”, as opposed to “inverting”, as there was no battery power or solar generation
Restored mains power
Shortly thereafter, I got the ground relay test failed error
The underlying detailed error message was “PE2 Closed”, which meant that it was seeing the relay as closed when it’s meant to be open. Our best guess is that we’d somehow hit an edge case in the Multi’s ground relay test, where they maybe tried to switch to inverting mode and activated the ground relay, then just died in that state because there was no backup power, and got confused when mains power returned. I got things running again by simply power cycling the Multis.
So it kinda wasn’t a big deal, except that if the grid went out briefly with no backup power, our loads would remain without power until one of us manually reset the system. This was arguably worse than not having the system at all, especially if it happened in the middle of the night, or when we were away from home. The fact that we didn’t hit this problem in the first year of operation is a testament to how unlikely this event is, but the fact that it could happen at all remained a problem.
One fix would have been to get a second battery, because then we’d be able to keep at least a tiny bit of backup power at all times regardless of maintenance cycles, but we’re not there yet. Happily, Simon found another fix, which was to physically connect the neutral together between the AC input and AC output sides of the Multis, then reconfigure them to use the grid code “AS4777.2:2015 AC Neutral Path externally joined”. That physical link means the load (output) side picks up the ground connection from the grid (input) side in the swichboard, and changing the grid code setting in the Multis disables the ground relay and thus the test which isn’t necessary anymore.
Murray needed to come out anyway to replace the carbon sock in the ZCell (a small item of annual maintenance) and was able to do that little bit of rewriting and configuration at the same time. I repeated my tests both with and without backup power and everything worked perfectly, i.e. the system came back immediately by itself after a grid outage with no backup power, and of course switched over to inverting just fine when there was backup power available.
This leads to the next little bit of fun. The carbon sock is a thing that sits inside the zinc electrolyte tank and helps to keep the electrolyte pH in the correct operating range. Unfortunately I didn’t manage to get a photo of one, but they look a bit like door snakes. Replacing the carbon sock means opening the case, popping one side of the Gas Handling Unit (GHU) off the tank, pulling out the old sock and putting in a new one. Here’s a picture of the ZCell with the back of the case off, indicating where the carbon sock goes:
The tank on the left (with the cooling fan) is for zinc electrolyte. The tank on the right is for bromine electrolyte. The blocky assembly of pipes going into both tanks is the GHU. The rectangular box behind that contains the electrode stacks.
When Murray popped the GHU off, he noticed that one of the larger pipes on one side had perished slightly. Thankfully he happened to have a spare GHU with him so was able to replace the assembly immediately. All was well until later that afternoon, when the battery indicated hardware failure due to “Leak 1 Trip” and shut itself down out of an abundance of caution. Upon further investigation the next day, Murry and I discovered there was a tiny split in one of the little hoses going into the GHU which was letting the electrolyte drip out.
Drip… Drip… Drip…
This small electrolyte leak was caught lower down in the battery, where the leak sensor is. Murray sucked the leaked electrolyte out of there, re-terminated that little hose and we were back in business. I was happy to learn that Redflow had obviously thought about the possibility of this type of failure and handled it. As I said to Murray at the time, we’d rather have a battery that leaks then turns itself off than a battery that catches fire!
Aside from those two interesting events, the rest of the year of operation was largely quite boring, which is exactly what one wants from a power system. As before I kept a small overnight scheduled charge and a larger late afternoon scheduled charge active on weekdays to ensure there was some power in the battery to use at peak (i.e. expensive) grid times. In spring and summer the afternoon charge is largely superfluous because the battery has usually been well filled up from the solar by then anyway, but there’s no harm in leaving it turned on. The one hack I did do during the year was to figure out a way to keep a small (I went with 15%) MinSoC in the battery at all times except for maintenance cycle evenings, and the morning after. This is more than enough to smooth out minor grid outages of a few minutes, and given our general load levels should be enough to run the house for more than an hour overnight if necessary, provided the hot water system and heating don’t decide to come on at the same time.
My earlier experiment along these lines involved a script that ran on the Cerbo twice a day to adjust scheduled charge settings in order to keep the battery at 100% SoC at all times except for peak electricity hours and maintenance cycle evenings. As mentioned in TANSTAAFL I ran that for all of July, August and most of September 2022. It worked fine, but ultimately I decided it was largely a waste of energy and money, especially when run during the winter months when there’s not much sun and you end up doing a lot of grid charging. This is a horribly inefficient way of getting power into the battery (AC to DC) versus charging the battery direct from solar PV. We did still use those scripts in the second year, but rather more judiciously, i.e. we kept an eye on the BOM forecasts as we always do, then occasionally activated the 100% charge when we knew severe weather and/or thunderstorms were on the way, those being the things most likely to cause extended grid outages. I also manually triggered maintenance on the battery earlier than strictly necessary several times when we expected severe weather in the coming days, to avoid having a maintenance cycle (and thus empty battery) coincide with potential outages. On most of those occasions this effort proved to be unnecessary. Bearing all that in mind, my general advice to anyone else with a single ZCell system (aside from maybe adding scheduled charges to time-shift expensive peak electricity) is to just leave it alone and let it do its thing. You’ll use most of your locally generated electricity onsite, you’ll save some money on your power bills, and you’ll avoid some, but not all, grid outages. This is a pretty good position to be in.
That said, I couldn’t resist messing around some more, hence my MinSoC experiment. Simon’s installation guide points out that “for correct system operation, the Settings->ESS menu ‘Min SoC’ value must be set to 0% in single-ZCell systems”. The issue here is that if MinSoC is greater than 0%, the Victron gear will try to charge the battery while the battery is simultaneously trying to empty itself during maintenance, which of course just isn’t going to work. My solution to this is the following script, which I run from a cron job on the Cerbo twice a day, once at midnight UTC and again at 06:00 UTC with the --check-maintenance flag set:
Midnight UTC corresponds to the end of our morning peak electricity time, and 06:00 UTC corresponds to the start of our afternoon peak. What this means is that after the morning peak finishes, the MinSoC setting will cause the system to automatically charge the battery to the value specified if it’s not up there already. Given it’s after the morning peak (10:00 AEST / 11:00 AEDT) this charge will likely come from solar PV, not the grid. When the script runs again just before the afternoon peak (16:00 AEST / 17:00 AEDT), MinSoC is set to either the value specified (effectively a no-op), or zero if it’s a maintenance day. This allows the battery to be discharged correctly in the evening on maintenance days, while keeping some charge every other day in case of emergencies. Unlike the script that tries for 100% SoC, this arrangement results in far less grid charging, while still giving protection from minor outages most of the time.
In case Simon is reading this now and is thinking “FFS, I wrote ‘MinSoC must be set to 0% in single-ZCell systems’ for a reason!” I should also add a note of caution. The script above detects ZCell maintenance cycles based solely on the configured maintenance time limit and the duration since last maintenance. It does not – and cannot – take into account occasions when the user manually forces maintenance, or situations in which a ZCell for whatever reason hypothetically decides to go into maintenance of its own accord. The latter shouldn’t generally happen, but it can. The point is, if you’re running this MinSoC script from a cron job, you really do still want to keep an eye on what the battery is doing each day, in case you need to turn that setting off and disable the cron job. If you’re not up for that I will reiterate my general advice from earlier: just leave the system alone – let it do its thing and you’ll (almost always) be perfectly fine. Or, get a second ZCell and you can ignore the last several paragraphs entirely.
Now, finally, let’s look at some numbers. The year periods here are a little sloppy for irritating historical reasons. 2018-2019, 2019-2020 and 2020-2021 are all August-based due to Aurora Energy’s previous quarterly billing cycle. The 2021-2022 year starts in late September partly because I had to wait until our new electricity meter was installed in September 2021, and partly because it let me include some nice screenshots when I started writing TANSTAAFL on September 25, 2022. I’ve chosen to make this year (2022-2023) mostly sane, in that it runs from October 1, 2022 through September 30, 2023 inclusive. This is only six days offset from the previous year, but notably makes it much easier to accurately correlate data from the VRM portal with our bills from Aurora. Overall we have five consecutive non-overlapping 12 month periods that are pretty close together. It’s not perfect, but I think it’s good enough to work with for our purposes here.
YeaR
Grid In
Solar In
Total In
Loads
Export
2018-2019
9,031
6,682
15,713
11,827
3,886
2019-2020
9,324
6,468
15,792
12,255
3,537
2020-2021
7,582
6,347
13,929
10,358
3,571
2021-2022
8,531
5,640
14,171
10,849
754
2022-2023
8,936
5,744
14,680
11,534
799
Overall, 2022-2023 had a similar shape to 2021-2022, including the fact that in both these years we missed three weeks of solar generation in late summer. In 2022 this was due to replacing the MPPT, and in 2023 it was because we replaced the roof. In both cases our PV generation was lower than it should have been by an estimated 500-600kW. Hopefully nothing like this happens again in future years.
All of our numbers in 2022-2023 were a bit higher than in 2021-2022. We pulled 4.75% more power from the grid, generated 1.84% more solar, the total power going into the system (grid + solar) was 3.59% higher, our loads used 6.31% more power, and we exported 5.97% more power than the previous year.
I honestly don’t know why our loads used more power this year. Here’s a table showing our consumption for both years, and the differences each month (note that September 2022 is only approximate because of how the years don’t quite line up):
Month
2022
2023
Diff
October
988
873
-115
November
866
805
-61
December
767
965
198
January
822
775
-47
February
638
721
83
March
813
911
98
April
775
1,115
340
May
953
1,098
145
June
1,073
1,149
76
July
1,118
1,103
-15
August
966
1,065
99
September
1,070
964
-116
Here’s a graph:
WTF happened in December and April?!?
Did we use more cooling this December? Did we use more heating this April and May? I dug the nearest weather station’s monthly mean minimum and maximum temperatures out of the BOM Climate Data Online tool and found that there’s maybe a degree or so variance one way or the other each month year to year, so I don’t know what I can infer from that. All I can say is that something happened in December and April, but I don’t know what.
Another interesting thing is that what I referred to as “the energy cost of the system” in TANSTAAFL has gone down. That’s the kW figure below in the “what?” column, which is the difference between grid in + solar in – loads – export, i.e. the power consumed by the system itself. In 2021-2022, that was 2,568 kW, or about 18% of the total power that went into the system. In 2022-2023 it was down to 2,347kWh, or just under 16%:
Year
Grid In
Solar In
Total In
Loads
Export
Total Out
what?
2021-2022
8,531
5,640
14,171
10,849
754
11,603
2,568
2022-2023
8,936
5,744
14,680
11,534
799
12,333
2,347
I suspect the cause of this reduction is that we didn’t spend two and a half months doing lots of grid charging of the battery in 2022-2023. If that’s the case, this again points to the advisability of just letting the system do its thing and not messing with it too much unless you really know you need to.
The last set of numbers I have involve actual money. Here’s what our electricity bills looked like over the past five years:
Year
From Grid
Total Bill
Cost/kWh
2018-2019
9,031
$2,278.33
$0.25
2019-2020
9,324
$2,384.79
$0.26
2020-2021
7,582
$1,921.77
$0.25
2021-2022
8,531
$1,731.40
$0.20
2022-2023
8,936
$1,989.12
$0.22
Note that cost/kWh as I have it here is simply the total dollar amount of our bills divided by the total power drawn from the grid (I’m deliberately ignoring the additional power we use that comes from the sun in this calculation). The bills themselves say “peak power costs $X, off-peak costs $Y, you get $Z back for power exported and there’s a daily supply charge of $SUCKS_TO_BE_YOU”, but that’s all noise. What ultimately matters in my opinion is what I call the effective cost per kilowatt hour, which is why those things are all smooshed together here. The important point is that with our existing solar array we were previously effectively paying about $0.25 per kWh for grid power. After getting the battery and switching to Peak & Off-Peak billing, that went down to $0.20/kWh – a reduction of 20%. Now we’ve inched back up to $0.22/kWh, but it turns out that’s just because power prices have increased. As far as I can tell Aurora Energy don’t publish historical pricing data, so as a public service, I’ll include what I’ve been able to glean from our prior bills here:
July 2023 onwards:
Daily supply charge: $1.26389
Peak: $0.36198/kWh
Off-Peak: $0.16855/kWh
Feed-In Tariff: $0.10869/kWh
July 2022 – July 2023
Daily supply charge: $1.09903
Peak: $0.33399/kWh
Off-Peak: $0.15551/kWh
Feed-In Tariff: $0.08883/kWh
Before July 2022:
Daily supply charge: $0.98
Peak: $0.29852
Off-Peak: $0.139
Feed-In Tariff: $0.06501
It’s nice that the feed-in tariff (i.e. what you get credited when you export power) has gone up quite a bit, but unless you’re somehow able to export 2-3x more power than you import, you’ll never get ahead of the ~20% increase in power prices over the last two years.
Having calculated the effective cost/kWh for grid power, I’m now going to do one more thing which I didn’t think to do during last year’s analysis, and that’s calculate the effective cost/kWh of running our loads, bearing in mind that they’re partially powered from the grid, and partially from the sun. I’ve managed to dig up some old Aurora bills from 2016-2017, back before we put the solar panels on. This should make for an interesting comparison.
Year
From Grid
Total Bill
Grid $/kWh
Loads
Loads $/kWh
2016-2017
17,026
$4,485.45
$0.26
17,026
$0.26
2018-2019
9,031
$2,278.33
$0.25
11,827
$0.19
2019-2020
9,324
$2,384.79
$0.26
12,255
$0.19
2020-2021
7,582
$1,921.77
$0.25
10,358
$0.19
2021-2022
8,531
$1,731.40
$0.20
10,849
$0.16
2022-2023
8,936
$1,989.12
$0.22
11,534
$0.17
The first thing to note is the horrifying 17 megawatts we pulled in 2016-2017. Given the hot water and lounge room heat pump were on a separate tariff, I was able to determine that four of those megawatts (i.e. about 24% of our power usage) went on heating that year. Replacing the crusty old conventional electric hot water system with a Sanden heat pump hot water service cut that in half – subsequent years showed the heating/hot water tariff using about 2MW/year. We obviously also somehow reduced our loads by another ~3MW/year on top of that, but I can’t find the Aurora bills for 2017-2018 so I’m not sure exactly when that drop happened. My best guess is that I probably got rid of some old, always-on computer equipment.
The second thing to note is how the cost of running the loads drops. In 2016-2017 the grid cost/kWh is the same as the loads cost/kWh, because grid power is all we had. From 2018-2021 though, the load cost/kWh drops to $0.19, a saving of about 26%. It remains there until 2021-2022 when we got the battery and it dropped again to $0.16 (another 15% or so). So the big win was certainly putting the solar panels on and swapping the hot water system, with the battery being a decent improvement on top of that.
Further wins are going to come from decreasing our power consumption. In previous posts I had mentioned the need to replace panel heaters with heat pumps, and also that some of our aging computer equipment needed upgrading. We did finally get a heat pump installed in the master bedroom this year, and we replaced the old undersized lounge room heat pump with a new correctly sized unit. This happened on June 30 though, so will have had minimal impact on this years’ figures. Likewise an always-on computer that previously pulled ~100W is now better, stronger and faster in all respects, while only pulling ~50W. That will save us ~438kW of power per year, but given the upgrade happened in mid August, again we won’t see the full effects until later.
I’m looking forward to doing another one of these posts in a year’s time. Hopefully I will have nothing at all interesting to report.
I (relatively) recently went down the rabbit hole of trying out personal finance apps to help get a better grip on, well, the things you’d expect (personal finances and planning around them).
In the past, I’ve had an off-again-on-again relationship with GNUCash. I did give it a solid go for a few months in 2004/2005 it seems (I found my old files) and I even had the OFX exports of transactions for a limited amount of time for a limited number of bank accounts! Amazingly, there’s a GNUCash port to macOS, and it’ll happily open up this file from what is alarmingly close to 20 years ago.
Back in those times, running Linux on the desktop was even more of an adventure than it has been since then, and I always found GNUCash to be strange (possibly a theme with me and personal finance software), but generally fine. It doesn’t seem to have changed a great deal in the years since. You still have to manually import data from your bank unless you happen to be lucky enough to live in the very limited number of places where there’s some kind of automation for it.
So, going back to GNUCash was an option. But I wanted to survey the land of what was available, and if it was possible to exchange money for convenience. I am not big on the motivation to go and spend a lot of time on this kind of thing anyway, so it had to be easy for me to do so.
For my requirements, I basically had:
Support multiple currencies
Be able to import data from my banks, even if manually
Some kind of reporting and planning tools
Be easy enough to use for me, and not leave me struggling with unknown concepts
The ability to export data. No vendor lock-in
I viewed a mobile app (iOS) as a Nice to Have rather than essential. Given that, my shortlist was:
I’ve used it before, its web site at https://www.gnucash.org/ looks much the same as it always has. It’s Free and Open Source Software, and is thus well aligned with my values, and that’s a big step towards not having vendor lock-in.
I honestly could probably make it work. I wish it had the ability to import transactions from banks for anywhere I have ever lived or banked with. I also wish the UI got to be a bit more consistent and modern, and even remotely Mac like on the Mac version.
Honestly, if the deal was that a web service would pull bank transactions in exchange for ~$10/month and also fund GNUCash development… I’d struggle to say no.
Here’s an option that has been around forever – https://www.quicken.com/ – and one that I figured I should solidly look at. It’s actually one I even spent money on…. before requesting a refund. It’s Import/Export is so broken it’s an insult to broken software everywhere.
Did you know that Quicken doesn’t import the Quicken Interchange Format (QIF), and hasn’t since 2005?
Me, incredulously, when trying out quicken
I don’t understand why you wouldn’t support as many as possible formats that banks export your transaction data as. It cannot possibly be that hard to parse these things, nor can it possibly be code that requires a lot of maintenance.
This basically meant that I couldn’t import data from my Australian Banks. Urgh. This alone ruled it out.
It really didn’t build confidence in ever getting my data out. At every turn it seemed to be really keen on locking you into Quicken rather than having a good experience all-up.
This one was new to me – https://www.wiz.money/ – and had a fancy URL and everything. I spent a bunch of time trying MoneyWiz, and I concluded that it is pretty, but buggy. I had managed to create a report where it said I’d earned $0, but you click into it, and then it gives actual numbers. Not being self consistent and getting the numbers wrong, when this is literally the only function of said app (to get the numbers right), took this out of the running.
It did sync from my US and Australian banks though, so points there.
Intuit used to own Quicken until it sold it to H.I.G. Capital in 2016 (according to Wikipedia). I have no idea if that has had an impact as to the feature set / usability of Quicken, but they now have this Cloud-only product called Mint.
The big issue I had with Mint was that there didn’t seem to be any way to get your data out of it. It seemed to exemplify vendor lock-in. This seems to have changed a bit since I was originally looking, which is good (maybe I just couldn’t find it?). But with the cloud-only approach I wasn’t hugely comfortable with having everything there. It also seemed to be lacking a few features that I was begging to find useful in other places.
It is the only product that links with the Apple Card though. No idea why that is the case.
The price tag of $0 was pretty unbeatable, which does make me wonder where the money is made from to fund its development and maintenance. My guess is that it’s through commission on the various financial products advertised through it, and I dearly hope it is not through selling data on its users (I have no reason to believe it is, there’s just the popular habit of companies doing this).
This is what I’ve settled on. It seemed to be easy enough for me to figure out how to use, sync with an iPhone App, be a reasonable price, and be able to import and sync things from accounts that I have. Oddly enough, nothing can connect and pull things from the Apple Card – which is really weird. That isn’t a Banktivity thing though, that’s just universal (except for Intuit’s Mint).
I’ve been using it for a bit more than a year now, and am still pretty happy. I wish there was the ability to attach a PDF of a statement to the Statement that you reconcile. I wish I could better tune the auto match/classification rules, and a few other relatively minor things.
Periodically in life I’ve had the desire to be somewhat fit, or at least have the benefits that come with that such as not dying early and being able to navigate a mountain (or just the city of Seattle) on foot without collapsing. I have also found that holding myself accountable via data is pretty vital to me actually going and repeatedly doing something.
So, at some point I got myself a Garmin watch. The year was 2012 and it was a Garmin Forerunner 410. It had a standard black/grey LCD screen, GPS (where getting a GPS lock could be utterly infuriatingly slow), a sensor you attached to your foot, a sensor you strap to your chest for Heart Rate monitoring, and an ANT+ dongle for connecting to a PC to download your activities. There was even some open source software that someone wrote so I could actually get data off my watch on my Linux laptops. This wasn’t a smart watch – it was exclusively for wearing while exercising and tracking an activity, otherwise it was just a watch.
However, as I was ramping up to marathon distance running, one huge flaw emerged: I was not fast enough to run a marathon in the time that the battery in my Garmin lasted. IIRC it would end up dying around 3hr30min into something, which at the time was increasingly something I’d describe as “not going for too long of a run”. So, the search for a replacement began!
The year was 2017, and the Garmin fenix 5x attracted me for two big reasons: a battery life to be respected, and turn-by-turn navigation. At the time, I seldom went running with a phone, preferring a tiny SanDisk media play (RIP, they made a new version that completely sucked) and a watch. The attraction of being able to get better maps back to where I started (e.g. a hotel in some strange city where I didn’t speak the language) was very appealing. It also had (what I would now describe as) rudimentary smart-watch features. It didn’t have even remotely everything the Pebble had, but it was enough.
So, a (non-trivial) pile of money later (even with discounts), I had myself a shiny and virtually indestructible new Garmin. I didn’t even need a dongle to sync it anywhere – it could just upload via its own WiFi connection, or through Bluetooth to the Garmin Connect app to my phone. I could also (if I ever remembered to), plug in the USB cable to it and download the activities to my computer.
One problem: my skin rebelled against the Garmin fenix 5x after a while. Like, properly rebelled. If it wasn’t coming off, I wanted to rip it off. I tried all of the tricks that are posted anywhere online. Didn’t help. I even got tested for what was the most likely culprit (a Nickel allergy), and didn’t have one of them, so I (still) have no idea what I’m actually allergic to in it. It’s just that I cannot wear it constantly. Urgh. I was enjoying the daily smart watch uses too!
So, that’s one rather expensive watch that is special purpose only, and even then started to get to be a bit of an issue around longer activities. Urgh.
So the hunt began for a smart watch that I could wear constantly. This usually ends in frustration as anything I wanted was hundreds of $ and pretty much nobody listed what materials were in it apart from “stainless steel”, “may contain”, and some disclaimer about “other materials”, which wasn’t a particularly useful starting point for “it is one of these things that my skin doesn’t like”. As at least if the next one also turned out to cause me problems, I could at least have a list of things that I could then narrow down to what I needed to avoid.
So that was all annoying, with the end result being that I went a long time without really wearing a watch. Why? The search resumed periodically and ended up either with nothing, or totally nothing. That was except if I wanted to get further into some vendor lock-in.
Honestly, the only manufacturer of anything smartwatch like which actually listed everything and had some options was Apple. Bizarre. Well, since I already got on the iPhone bandwagon, this was possible. Rather annoyingly, they are very tied together and thus it makes it a bit of a vendor-lock-in if you alternate phone and watch replacement and at any point wish to switch platforms.
That being said though, it does work well and not irritate my skin. So that’s a bonus! If I get back into marathon level distance running, we’ll see how well it goes. But for more common distances that I’ve run or cycled with it… the accuracy seems decent, HR monitor never just sometimes decides I’m not exerting myself, and the GPS actually gets a lock in reasonable time. Plus it can pair with headphones and be the only thing I take out with me.
A few random notes about things that can make life on macOS (the modern one, as in, circa 2023) better for those coming from Linux.
For various reasons you may end up with Mac hardware with macOS on the metal rather than Linux. This could be anything from battery life of the Apple Silicon machines (and not quite being ready to jump on the Asahi Linux bandwagon), to being able to run the corporate suite of Enterprise Software (arguably a bug more than a feature), to some other reason that is also fine.
My approach to most of my development is to have a remote more powerful Linux machine to do the heavy lifting, or do Linux development on Linux, and not bank on messing around with a bunch of software on macOS that would approximate something on Linux. This also means I can move my GUI environment (the Mac) easily forward without worrying about whatever weird workarounds I needed to do in order to get things going for whatever development work I’m doing, and vice-versa.
Terminal emulator? iTerm2. The built in Terminal.app is fine, but there’s more than a few nice things in iTerm2, including tmuxintegration which can end up making it feel a lot more like a regular Linux machine. I should probably go read the tmux integration best practices before I complain about some random bugs I think I’ve hit, so let’s pretend I did that and everything is perfect.
I tend to use the Mac for SSHing to bigger Linux machines for most of my work. At work, that’s mostly to a Graviton 2 EC2 Instance running Amazon Linux with all my development environments on it. At home, it’s mostly a Raptor Blackbird POWER9 system running Fedora.
Running Linux locally? For all the use cases of containers, Podman Desktop or finch. There’s a GUI part of Podman which is nice, and finch I know about because of the relatively nearby team that works on it, and its relationship to lima. Lima positions itself as WSL2-like but for Mac. There’s UTM for a full virtual machine / qemu environment, although I rarely end up using this and am more commonly using a container or just SSHing to a bigger Linux box.
There’s XCode for any macOS development that may be needed (e.g. when you want that extra feature in UTM or something) I do use Homebrew to install a few things locally.
Last week I had occasion to test deploying ceph-csi on a k3s cluster, so that Kubernetes workloads could access block storage provided by an external Ceph cluster. I went with the upstream Ceph documentation, because assuming everything worked it’d then be really easy for me to say to others “just go do this”.
Everything did not work.
I’d gone through all the instructions, inserting my own Ceph cluster’s FSID and MON IP addresses in the right places, applied the YAML to deploy the provisioner and node plugins, and all the provisioner bits were running just fine, but the csi-rbdplugin pods were stuck in CrashLoopBackOff:
The csi-rbdplugin pod consists of three containers – driver-registrar, csi-rbdplugin, liveness-prometheus – and csi-rbdplugin wasn’t able to load the rbd kernel module:
> kubectl logs csi-rbdplugin-22zjr --container csi-rbdplugin
I0726 10:25:12.862125 7628 cephcsi.go:199] Driver version: canary and Git version: d432421a88238a878a470d54cbf2c50f2e61cdda
I0726 10:25:12.862452 7628 cephcsi.go:231] Starting driver type: rbd with name: rbd.csi.ceph.com
I0726 10:25:12.865907 7628 mount_linux.go:284] Detected umount with safe 'not mounted' behavior
E0726 10:25:12.872477 7628 rbd_util.go:303] modprobe failed (an error (exit status 1) occurred while running modprobe args: [rbd]): "modprobe: ERROR: could not insert 'rbd': Key was rejected by service\n"
F0726 10:25:12.872702 7628 driver.go:150] an error (exit status 1) occurred while running modprobe args: [rbd]
Matching “modprobe: ERROR: could not insert ‘rbd’: Key was rejected by service” in the above was an error on each host’s console: “Loading of unsigned module is rejected”. These hosts all have secure boot enabled, so I figured it had to be something to do with that. So I logged into one of the hosts and ran modprobe rbd as root, but that worked just fine. No key errors, no unsigned module errors. And once I’d run modprobe rbd (and later modprobe nbd) on the host, the csi-rbdplugin container restarted and worked just fine.
So why wouldn’t modprobe work inside the container? /lib/modules from the host is mounted inside the container, the container has the right extra privileges… Clearly I needed to run a shell in the failing container to poke around inside when it was in CrashLoopBackOff state, but I realised I had no idea how to do that. I knew I could kubectl exec -it csi-rbdplugin-22zjr --container csi-rbdplugin -- /bin/bash but of course that only works if the container is actually running. My container wouldn’t even start because of that modprobe error.
Having previously spent a reasonable amount of time with podman, which has podman run, I wondered if there were a kubectl run that would let me start a new container using the upstream cephcsi image, but running a shell, instead of its default command. Happily, there is a kubectl run, so I tried it:
> kubectl run -it cephcsi --image=quay.io/cephcsi/cephcsi:canary --rm=true --command=true -- /bin/bash
If you don't see a command prompt, try pressing enter.
[root@cephcsi /]# modprobe rbd
modprobe: FATAL: Module rbd not found in directory /lib/modules/5.14.21-150400.24.66-default
[root@cephcsi /]# ls /lib/modules/
[root@cephcsi /]#
Ohhh, right, of course, that doesn’t have the host’s /lib/modules mounted. podman run lets me add volume mounts using -v options , so surely kubectl run will let me do that too.
At this point in the story, the notes I wrote last week include an awful lot of swearing.
See, kubectl run doesn’t have a -v option to add mounts, but what it does have is an --overrides option to let you add a chunk of JSON to override the generated pod. So I went back to the relevant YAML and teased out the bits I needed to come up with this monstrosity:
But at least I could get a shell and reproduce the problem:
> kubectl run -it cephcsi-test [honking great horrible chunk of JSON]
[root@cephcsi-test /]# ls /lib/modules/
5.14.21-150400.24.66-default
[root@cephcsi-test /]# modprobe rbd
modprobe: ERROR: could not insert 'rbd': Key was rejected by service
A certain amount more screwing around looking at the source for modprobe and bits of the kernel confirmed that the kernel really didn’t think the module was signed for some reason (mod_verify_sig() was returning -ENODATA), but I knew these modules were fine, because I could load them on the host. Eventually I hit on this:
[root@cephcsi-test /]# ls /lib/modules/*/kernel/drivers/block/rbd*
/lib/modules/5.14.21-150400.24.66-default/kernel/drivers/block/rbd.ko.zst
Wait, what’s that .zst extension? It turns out we (SUSE) have been shipping zstd-compressed kernel modules since – as best as I can tell – some time in 2021. modprobe on my SLE Micro 5.3 host of course supports this:
# grep PRETTY /etc/os-release
PRETTY_NAME="SUSE Linux Enterprise Micro for Rancher 5.3"
# modprobe --version
kmod version 29
+ZSTD +XZ +ZLIB +LIBCRYPTO -EXPERIMENTAL
modprobe in the CentOS Stream 8 upstream cephcsi container does not:
Mystery solved, but I have to say the error messages presented were spectacularly misleading. I later tried with secure boot disabled, and got something marginally better – in that case modprobe failed with “modprobe: ERROR: could not insert ‘rbd’: Exec format error”, and dmesg on the host gave me “Invalid ELF header magic: != \x7fELF”. If I’d seen messaging like that in the first place I might have been quicker to twig to the compression thing.
Anyway, the point of this post wasn’t to rant about inscrutable kernel errors, it was to rant about how there’s no way anyone could be reasonably expected to figure out how to do that --overrides thing with the JSON to debug a container stuck in CrashLoopBackOff. Assuming I couldn’t possibly be the first person to need to debug containers in this state, I told my story to some colleagues, a couple of whom said (approximately) “Oh, I edit the pod YAML and change the container’s command to tail -f /dev/null or sleep 1d. Then it starts up just fine and I can kubectl exec into it and mess around”. Those things totally work, and I wish I’d thought to do that myself. The best answer I got though was to use kubectl debug to make a copy of the existing pod but with the command changed. I didn’t even know kubectl debug existed, which I guess is my reward for not reading the entire manual
So, finally, here’s the right way to do what I was trying to do:
> kubectl debug csi-rbdplugin-22zjr -it \
--copy-to=csi-debug --container=csi-rbdplugin -- /bin/bash
[root@... /]# modprobe rbd
modprobe: ERROR: could not insert 'rbd': Key was rejected by service
(...do whatever other messing around you need to do, then...)
[root@... /]# exit
Session ended, resume using 'kubectl attach csi-debug -c csi-rbdplugin -i -t' command when the pod is running
> kubectl delete pod csi-debug
pod "csi-debug" deleted
In the above kubectl debug invocation, csi-rbdplugin-22zjr is the existing pod that’s stuck in CrashLoopBackOff, csi-debug is the name of the new pod being created, and csi-rbdplugin is the container in that pod that has its command replaced with /bin/bash, so you can mess around inside it.
The July 2023 meeting sparked multiple new topics including Linux security architecture, Debian ports of LoongArch and Risc-V as well as hardware design of PinePhone backplates.
On the practical side, Russell Coker demonstrated running different applications in isolated environment with bubblewrap sandbox, as well as other hardening techniques and the way they interact with the host system. Russell also discussed some possible pathways of hardening desktop Linux to reach the security level of modern Android. Yifei Zhan demonstrated sending and receiving messages with the PineDio USB LoRa adapter and how to inspect LoRa signal with off-the-shelf software defined radio receiver, and discussed how the driver situation for LoRa on Linux might be improved. Yifei then gave a demonstration on utilizing KVM on PinePhone Pro to run NetBSD and OpenBSD virtual machines, more details on running VMs on the PinePhone Pro can be found on this blog post from Yifei.
We also had some discussion of the current state of Mobian and Debian ecosystem, along with how to contribute to different parts of Mobian with a Mobian developer who joined us.
I’ve had a pretty varied experience with photo management on Linux over the past couple of decades. For a while I used f-spot as it was the new hotness. At some point this became…. slow and crashy enough that it was unusable. Today, it appears that the GitHub project warns that current bugs include “Not starting”.
At some point (and via a method I have long since forgotten), I did manage to finally get my photos over to Shotwell, which was the new hotness at the time. That data migration was so long ago now I actually forget what features I was missing from f-spot that I was grumbling about. I remember the import being annoying though. At some point in time Shotwell was no longer was the new hotness and now there is GNOME Photos. I remember looking at GNOME Photos, and seeing no method of importing photos from Shotwell, so put it aside. Hopefully that situation has improved somewhere.
At some point Shotwell was becoming rather stagnated, and I noticed more things stopping to work rather than getting added features and performance. The good news is that there has been some more development activity on Shotwell, so hopefully my issues with it end up being resolved.
One recommendation for Linux photo management was digiKam, and one that I never ended up using full time. One of the reasons behind that was that I couldn’t really see any non manual way to import photos from Shotwell into it.
With tens of thousands of photos (~58k at the time of writing), doing things manually didn’t seem like much fun at all.
As I postponed my decision, I ended up moving my main machine over to a Mac for a variety of random reasons, and one quite motivating thing was the ability to have Photos from my iPhone magically sync over to my photo library without having to plug it into my computer and copy things across.
So…. how to get photos across from Shotwell on Linux to Photos on a Mac/iPhone (and also keep a very keen eye on how to do it the other way around, because, well, vendor lock-in isn’t great).
It would be kind of neat if I could just run Shotwell on the Mac and have some kind of import button, but seeing as there wasn’t already a native Mac port, and that Shotwell is written in Vala rather than something I know has a working toolchain on macOS…. this seemed like more work than I’d really like to take on.
Luckily, I remembered that Shotwell’s database is actually just a SQLite database pointing to all the files on disk. So, if I could work out how to read it accurately, and how to import all the relevant metadata (such as what Albums a photo is in, tags, title, and description) into Apple Photos, I’d be able to make it work.
So… is there any useful documentation as to how the database is structured?
Semi annoyingly, Shotwell is written in Vala, a rather niche programming language that while integrating with all the GObject stuff that GNOME uses, is largely unheard of. Luckily, the database code in Shotwell isn’t too hard to read, so was a useful fallback for when the documentation proves inadequate.
Programming the Mac side of things, it was a good excuse to start looking at Swift, so knowing I’d also need to read a SQLite database directly (rather than use any higher level abstraction), I armed myself with the following resources:
From here, I could work on getting the first half going, the ability to view my Shotwell database on the Mac (which is what I posted a screenshot of back in Feb 2022).
But also, I had to work out what I was doing on the other end of things, how would I import photos? It turns out there’s an API!
A bit of SwiftUI code:
import SwiftUI
import AppKit
import Photos
struct ContentView: View {
@State var favorite_checked : Bool = false
@State var hidden_checked : Bool = false
var body: some View {
VStack() {
Text("Select a photo for import")
Toggle("Favorite", isOn: $favorite_checked)
Toggle("Hidden", isOn: $hidden_checked)
Button("Import Photo")
{
let panel = NSOpenPanel()
panel.allowsMultipleSelection = false
panel.canChooseDirectories = false
if panel.runModal() == .OK {
let photo_url = panel.url!
print("selected: " + String(photo_url.absoluteString))
addAsset(url: photo_url, isFavorite: favorite_checked, isHidden: hidden_checked)
}
}
.padding()
}
}
}
struct ContentView_Previews: PreviewProvider {
static var previews: some View {
ContentView()
}
}
Combined with a bit of code to do the import (which does look a bunch like the examples in the docs):
import SwiftUI
import Photos
import AppKit
@main
struct SinglePhotoImporterApp: App {
var body: some Scene {
WindowGroup {
ContentView()
}
}
}
func addAsset(url: URL, isFavorite: Bool, isHidden: Bool) {
// Add the asset to the photo library.
let path = "/Users/stewart/Pictures/1970/01/01/1415446258647.jpg"
let url = URL(fileURLWithPath: path)
PHPhotoLibrary.shared().performChanges({
let addedImage = PHAssetChangeRequest.creationRequestForAssetFromImage(atFileURL: url)
addedImage?.isHidden = isHidden
addedImage?.isFavorite = isFavorite
}, completionHandler: {success, error in
if !success { print("Error creating the asset: \(String(describing: error))") } else
{
print("Imported!")
}
})
}
This all meant I could import a single photo. However, there were some limitations.
There’s the PHAssetCollectionChangeRequest to do things to Albums, so it would solve that problem, but I couldn’t for the life of me work out how to add/edit Titles and Descriptions.
It was so close!
So what did I need to do in order to import Titles and Descriptions? It turns out you can do that via AppleScript. Yes, that thing that launched in 1993 and has somehow survived the transition of m68k based Macs to PowerPC based Macs to Intel based Macs to ARM based Macs.
The Photos dictionary for AppleScript
So, just to make it easier to debug what was going on, I started adding code to my ShotwellImporter tool that would generate snippets of AppleScript I could run and check that it was doing the right thing…. but then very quickly ran into a problem…. it appears that the AppleScript language interpreter on modern macOS has limits that you’d be more familiar with in 1993 than 2023, and I very quickly hit limits where the script would just error out before running (I was out of dictionary size allegedly).
But there’s a new option! Everything you can do with AppleScript you can now do with JavaScript – it’s just even less documented than AppleScript is! But it does work! I got to the point where I could generate JavaScript that imported photos, into all the relevant albums, and set title and descriptions.
In my last post, I wrote about how I taught sesdev (originally a tool for deploying Ceph clusters on virtual machines) to deploy k3s, because I wanted a little sandbox in which I could break learn more about Kubernetes. It’s nice to be able to do a toy deployment locally, on a bunch of VMs, on my own hardware, in my home office, rather than paying to do it on someone else’s computer. Given the k3s thing worked, I figured the next step was to teach sesdev how to deploy Longhorn so I could break that learn more about that too.
Install nfs-client, open-iscsi and e2fsprogs packages on all nodes.
Make an ext4 filesystem on /dev/vdb on all the nodes that have extra disks, then mount that on /var/lib/longhorn.
Use kubectl label node -l 'node-role.kubernetes.io/master!=true' node.longhorn.io/create-default-disk=true to ensure Longhorn does its storage thing only on the nodes that aren’t the k3s master.
Install Longhorn with Helm, because that will install the latest version by default vs. using kubectl where you always explicitly need to specify the version.
Create an ingress so the UI is exposed… from all nodes, via HTTP, with no authentication. Remember: this is a sandbox – please don’t do this sort of thing in production!
So, now I can do this:
> sesdev create k3s --deploy-longhorn
=== Creating deployment "k3s-longhorn" with the following configuration ===
Deployment-wide parameters (applicable to all VMs in deployment):
- deployment ID: k3s-longhorn
- number of VMs: 5
- version: k3s
- OS: tumbleweed
- public network: 10.20.78.0/24
Proceed with deployment (y=yes, n=no, d=show details) ? [y]: y
=== Running shell command ===
vagrant up --no-destroy-on-error --provision
Bringing machine 'master' up with 'libvirt' provider…
Bringing machine 'node1' up with 'libvirt' provider…
Bringing machine 'node2' up with 'libvirt' provider…
Bringing machine 'node3' up with 'libvirt' provider…
Bringing machine 'node4' up with 'libvirt' provider…
[... lots more log noise here - this takes several minutes... ]
=== Deployment Finished ===
You can login into the cluster with:
$ sesdev ssh k3s-longhorn
Longhorn will now be deploying, which may take some time.
After logging into the cluster, try these:
# kubectl get pods -n longhorn-system --watch
# kubectl get pods -n longhorn-system
The Longhorn UI will be accessible via any cluster IP address
(see the kubectl -n longhorn-system get ingress output above).
Note that no authentication is required.
…and, after another minute or two, I can access the Longhorn UI and try creating some volumes. There’s a brief period while the UI pod is still starting where it just says “404 page not found”, and later after the UI is up, there’s still other pods coming online, so on the Volume screen in the Longhorn UI an error appears: “failed to get the parameters: failed to get target node ID: cannot find a node that is ready and has the default engine image longhornio/longhorn-engine:v1.4.1 deployed“. Rest assured thisgoes away in due course (it’s not impossible I’m suffering here from rural Tasmanian internet lag pulling container images). Anyway, with my five nodes – four of which have an 8GB virtual disk for use by Longhorn – I end up with a bit less than 22GB storage available:
21.5 GiB isn’t much, but remember this is a toy deployment running in VMs on my desktop Linux box
Now for the fun part. Longhorn is a distributed storage solution, so I thought it would be interesting to see how it handled a couple of types of failure. The following tests are somewhat arbitrary (I’m really just kicking the tyres randomly at this stage) but Longhorn did, I think, behave pretty well given what I did to it.
Volumes in Longhorn consist of replicas stored as sparse files on a regular filesystem on each storage node. The Longhorn documentation recommends using a dedicated disk rather than just having /var/lib/longhorn backed by the root filesystem, so that’s what sesdev does: /var/lib/longhorn is an ext4 filesystem mounted on /dev/vdb. Now, what happens to Longhorn if that underlying block device suffers some kind of horrible failure? To test that, I used the Longhorn UI to create a 2GB volume, then attached that to the master node:
The Longhorn UI helpfully tells me the volume replicas are on node3, node4 and node1
Then, I ssh’d to the master node and with my 2GB Longhorn volume attached, made a filesystem on it and created a little file:
> sesdev ssh k3s-longhorn
Have a lot of fun...
master:~ # cat /proc/partitions
major minor #blocks name
253 0 44040192 vda
253 1 2048 vda1
253 2 20480 vda2
253 3 44016623 vda3
8 0 2097152 sda
master:~ # mkfs /dev/sda
mke2fs 1.46.5 (30-Dec-2021)
Discarding device blocks: done
Creating filesystem with 524288 4k blocks and 131072 inodes
Filesystem UUID: 3709b21c-b9a2-41c1-a6dd-e449bdeb275b
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
master:~ # mount /dev/sda /mnt
master:~ # echo foo > /mnt/foo
master:~ # cat /mnt/foo
foo
Then I went and trashed the block device backing one of the replicas:
> sesdev ssh k3s-longhorn node3
Have a lot of fun...
node3:~ # ls /var/lib/longhorn
engine-binaries longhorn-disk.cfg lost+found replicas unix-domain-socket
node3:~ # dd if=/dev/urandom of=/dev/vdb bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 0.486205 s, 216 MB/s
node3:~ # ls /var/lib/longhorn
node3:~ # dmesg|tail -n1
[ 6544.197183] EXT4-fs error (device vdb): ext4_map_blocks:607: inode #393220: block 1607168: comm longhorn: lblock 0 mapped to illegal pblock 1607168 (length 1)
At this point, the Longhorn UI still showed the volume as green (healthy, ready, scheduled). Then, back on the master node, I tried creating another file:
master:~ # echo bar > /mnt/bar
master:~ # cat /mnt/bar
bar
That’s fine so far, but suddenly the Longhorn UI noticed that something very bad had happened:
The volume is still usable, but one of the replicas has failed
Ultimately node3 was rebooted and ended up stalled with the console requesting the root password for maintenance:
Failed to mount /var/lib/longhorn – Can’t find ext4 filesystem
Meanwhile, Longhorn went and rebuilt a third replica on node2:
All green again!
…and the volume remained usable the entire time:
master:~ # echo baz > /mnt/baz
master:~ # ls /mnt
bar baz foo lost+found
That’s perfect!
Looking at the Node screen we could see that node3 was still down:
There may be disk size errors with down nodes (4.87 TiB looks a lot like integer overflow to me)
That’s OK, I was able to fix node3. I logged in on the console and ran mkfs.ext4 /dev/vdb then brought the node back up again.The disk remained unschedulable, because Longhorn was still expecting the ‘old’ disk to be there (I assume based on the UUID stored in /var/lib/longhorn/longhorn-disk.cfg) and of course the ‘new’ disk is empty. So I used the Longhorn UI to disable scheduling for that ‘old’ disk, then deleted it. Shortly after, Longhorn recognised the ‘new’ disk mounted at /var/lib/longhorn and everything was back to green across the board.
So Longhorn recovered well from the backing store of one replica going bad. Next I thought I’d try to break it from the other end by running a volume out of space. What follows is possibly not a fair test, because what I did was create a single Longhorn volume larger than the underlying disks, then filled that up. In normal usage, I assume one would ensure there’s plenty of backing storage available to service multiple volumes, that individual volumes wouldn’t generally be expected to get more than a certain percentage full, and that some sort of monitoring and/or alerting would be in place to warn of disk pressure.
With four nodes, each with a single 8GB disk, and Longhorn apparently reserving 2.33GB by default on each disk, that means no Longhorn volume can physically store more than a bit over 5.5GB of data (see the Size column in the previous screenshot). Given that the default setting for Storage Over Provisioning Percentage is 200, we’re actually allowed to allocate up to a bit under 11GB.
So I went and created a 10GB volume, attached that to the master node, created a filesystem on it, and wrote a whole lot of zeros to it:
…there was a lot of unpleasantness on the master node’s console…
So many I/O errors!
…the replicas became unschedulable due to lack of space…
This doesn’t look good
…and finally the volume faulted:
This really doesn’t look good
Now what?
It turns out that Longhorn will actually recover if we’re able to somehow expand the disks that store the replicas. This is probably a good argument for backing Longhorn with an LVM volume on each node in real world deployments, because then you could just add another disk and extend the volume onto it. In my case though, given it’s all VMs and virtual block devices, I can actually just enlarge those devices. For each node then, I:
Shut it down
Ran qemu-img resize /var/lib/libvirt/images/k3s-longhorn_$NODE-vdb.qcow2 +8G
Started it back up again and ran resize2fs /dev/vdb to take advantage of the extra disk space.
After doing that to node1, Longhorn realised there was enough space there and brought node1’s replica of my 10GB volume back online. It also summarily discarded the other two replicas from the still-full disks on node2 and node3, which didn’t yet have enough free space to be useful:
One usable replica is better than three unusable replicas
As I repeated the virtual disk expansion on the other nodes, Longhorn happily went off and recreated the missing replicas:
Finally I could re-attach the volume to the master node, and have a look to see how many of my zeros were actually written to the volume:
master:~ # cat /proc/partitions
major minor #blocks name
254 0 44040192 vda
254 1 2048 vda1
254 2 20480 vda2
254 3 44016623 vda3
8 0 10485760 sda
master:~ # mount /dev/sda /mnt
master:~ # ls -l /mnt
total 7839764
-rw-r--r-- 1 root root 8027897856 May 3 04:41 big-lot-of-zeros
drwx------ 2 root root 16384 May 3 04:34 lost+found
Recall that dd claimed to have written 9039773696 bytes before it stalled when the volume faulted, so I guess that last gigabyte of zeros is lost in the aether. But, recall also that this isn’t really a fair test – one overprovisioned volume deliberately being quickly and deliberately filled to breaking point vs. a production deployment with (presumably) multiple volumes that don’t fill quite so fast, and where one is hopefully paying at least a little bit of attention to disk pressure as time goes by.
It’s worth noting that in a situation where there are multiple Longhorn volumes, assuming one disk or LVM volume per node, the replicas will all share the same underlying disks, and once those disks are full it seems all the Longhorn volumes backed by them will fault. Given multiple Longhorn volumes, one solution – rather than expanding the underlying disks – is simply to delete a volume or two if you can stand to lose the data, or maybe delete some snapshots (I didn’t try the latter yet). Once there’s enough free space, the remaining volumes will come back online. If you’re really worried about this failure mode, you could always just disable overprovisioning in the first place – whether this makes sense or not will really depend on your workloads and their data usage patterns.
All in all, like I said earlier, I think Longhorn behaved pretty well given what I did to it. Some more information in the event log could perhaps be beneficial though. In the UI I can see warnings from longhorn-node-controller e.g. “the disk default-disk-1cdbc4e904539d26(/var/lib/longhorn/) on the node node1 has 3879731200 available, but requires reserved 2505089433, minimal 25% to schedule more replicas” and warnings from longhorn-engine-controller e.g. “Detected replica overprovisioned-r-73d18ad6 (10.42.3.19:10000) in error“, but I couldn’t find anything really obvious like “Dude, your disks are totally full!”
Later, I found more detail in the engine manager logs after generating a support bundle ([…] level=error msg=”I/O error” error=”tcp://10.42.4.34:10000: write /host/var/lib/longhorn/replicas/overprovisioned-c3b9b547/volume-head-003.img: no space left on device”) so the error information is available – maybe it’s just a matter of learning where to look for it.
We – that is to say the storage team at SUSE – have a tool we’ve been using for the past few years to help with development and testing of Ceph on SUSE Linux. It’s called sesdev because it was created largely for SES (SUSE Enterprise Storage) development. It’s essentially a wrapper around vagrant and libvirt that will spin up clusters of VMs running openSUSE or SLES, then deploy Ceph on them. You would never use such clusters in production, but it’s really nice to be able to easily spin up a cluster for testing purposes that behaves something like a real cluster would, then throw it away when you’re done.
I’ve recently been trying to spend more time playing with Kubernetes, which means I wanted to be able to spin up clusters of VMs running openSUSE or SLES, then deploy Kubernetes on them, then throw the clusters away when I was done, or when I broke something horribly and wanted to start over. Yes, I know there’s a bunch of other tools for doing toy Kubernetes deployments (minikube comes to mind), but given I already had sesdev and was pretty familiar with it, I thought it’d be worthwhile seeing if I could teach it to deploy k3s, a particularly lightweight version of Kubernetes. Turns out that wasn’t too difficult, so now I can do this:
> sesdev create k3s
=== Creating deployment "k3s" with the following configuration ===
Deployment-wide parameters (applicable to all VMs in deployment):
deployment ID: k3s
number of VMs: 5
version: k3s
OS: tumbleweed
public network: 10.20.190.0/24
Proceed with deployment (y=yes, n=no, d=show details) ? [y]: y
=== Running shell command ===
vagrant up --no-destroy-on-error --provision
Bringing machine 'master' up with 'libvirt' provider...
Bringing machine 'node1' up with 'libvirt' provider...
Bringing machine 'node2' up with 'libvirt' provider...
Bringing machine 'node3' up with 'libvirt' provider...
Bringing machine 'node4' up with 'libvirt' provider...
[...wait a few minutes(there's lots more log information output here in real life)
...]
=== Deployment Finished ===
You can login into the cluster with:
$ sesdev ssh k3s
…and then I can do this:
> sesdev ssh k3s
Last login: Fri Mar 24 11:50:15 CET 2023 from 10.20.190.204 on ssh
Have a lot of fun…
master:~ # kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 5m16s v1.25.7+k3s1
node2 Ready 2m17s v1.25.7+k3s1
node1 Ready 2m15s v1.25.7+k3s1
node3 Ready 2m16s v1.25.7+k3s1
node4 Ready 2m16s v1.25.7+k3s1
master:~ # kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system local-path-provisioner-79f67d76f8-rpj4d 1/1 Running 0 5m9s
kube-system metrics-server-5f9f776df5-rsqhb 1/1 Running 0 5m9s
kube-system coredns-597584b69b-xh4p7 1/1 Running 0 5m9s
kube-system helm-install-traefik-crd-zz2ld 0/1 Completed 0 5m10s
kube-system helm-install-traefik-ckdsr 0/1 Completed 1 5m10s
kube-system svclb-traefik-952808e4-5txd7 2/2 Running 0 3m55s
kube-system traefik-66c46d954f-pgnv8 1/1 Running 0 3m55s
kube-system svclb-traefik-952808e4-dkkp6 2/2 Running 0 2m25s
kube-system svclb-traefik-952808e4-7wk6l 2/2 Running 0 2m13s
kube-system svclb-traefik-952808e4-chmbx 2/2 Running 0 2m14s
kube-system svclb-traefik-952808e4-k7hrw 2/2 Running 0 2m14s
…and then I can make a mess with kubectl apply, helm, etc.
One thing that sesdev knows how to do is deploy VMs with extra virtual disks. This functionality is there for Ceph deployments, but there’s no reason we can’t turn it on when deploying k3s:
> sesdev create k3s --num-disks=2
> sesdev ssh k3s
master:~ # for node in \
$(kubectl get nodes -o 'jsonpath={.items[*].metadata.name}') ;
do echo $node ; ssh $node cat /proc/partitions ; done
master
major minor #blocks name
253 0 44040192 vda
253 1 2048 vda1
253 2 20480 vda2
253 3 44016623 vda3
node3
major minor #blocks name
253 0 44040192 vda
253 1 2048 vda1
253 2 20480 vda2
253 3 44016623 vda3
253 16 8388608 vdb
253 32 8388608 vdc
node2
major minor #blocks name
253 0 44040192 vda
253 1 2048 vda1
253 2 20480 vda2
253 3 44016623 vda3
253 16 8388608 vdb
253 32 8388608 vdc
node4
major minor #blocks name
253 0 44040192 vda
253 1 2048 vda1
253 2 20480 vda2
253 3 44016623 vda3
253 16 8388608 vdb
253 32 8388608 vdc
node1
major minor #blocks name
253 0 44040192 vda
253 1 2048 vda1
253 2 20480 vda2
253 3 44016623 vda3
253 16 8388608 vdb
253 32 8388608 vdc
As you can see this gives all the worker nodes an extra two 8GB virtual disks. I suspect this may make sesdev an interesting tool for testing other Kubernetes based storage systems such as Longhorn, but I haven’t tried that yet.
I recently bought an
Energica
Experia - the latest, largest and longest distance of Energica's
electric motorbike models.
The decision to do this rather than build my own was complicated, and I'm
going to mostly skip over the detail of that. At some time I might put it in
another blog post. But for now it's enough to say that I'd accidentally
cooked the motor in my Mark I, the work on the Mark II was going to take ages,
and I was in the relatively fortunate situation of being able to afford the
Experia if I sold my existing Triumph Tiger Sport and the parts for the Mark
II.
For other complicated reasons I was planning to be in Sydney after the weekend
that Bruce at Zen Motorcycles told
me the bike would be arriving. Rather than have it freighted down, and since
I would have room for my riding gear in our car, I decided to pick it up and
ride it back on the Monday. In reconnoitering the route, we discovered that
by pure coincidence Zen Motorcycles is on Euston Road in Alexandria, only
200 metres away from the entrance to WestConnex and the M8. So with one
traffic light I could be out of Sydney.
I will admit to being more than a little excited that morning. Electric
vehicles are still, in 2023, a rare enough commodity that waiting lists can be
months long; I ordered this bike in October 2022 and it arrived in March 2023.
So I'd had plenty of time to build my expectations. And likewise the thought
of riding a brand new bike - literally one of the first of its kind in the
country (it is the thirty-second Experia ever made!) - was a little daunting.
I obtained PDF copies of the manual and familiarised myself with turning the
cruise control on and off, as well as checking and setting the regen braking
levels. Didn't want to stuff anything up on the way home.
There is that weird feeling in those situations of things being both very
ordinary and completely unique. I met Bruce, we chatted, I saw the other
Experia models in the store, met Ed - who had come down to chat with Bruce,
and just happened to be the guy who rode a Harley Davidson Livewire from
Perth to Sydney and then from Sydney to Cape Tribulation and back. He shared
stories from his trip and tips on hypermiling. I signed paperwork, picked up
the keys, put on my gear, prepared myself.
Even now I still get a bit choked up just thinking of that moment. Seeing
that bike there, physically real, in front of me - after those months of
anticipation - made the excitement real as well.
So finally, after making sure I wasn't floating, and making sure I had my
ear plugs in and helmet on the right way round, I got on. Felt the bike's
weight. Turned it on. Prepared myself. Took off. My partner followed
behind, through the lights, onto the M8 toward Canberra. I gave her the
thumbs up.
We planned to stop for lunch at Mittagong, while the NRMA still offers the
free charger at the RSL there. One lady was charging her Nissan Leaf on the
ChaDeMo side; shortly after I plugged in a guy arrived in his Volvo XC40
Recharge. He had the bigger battery and would take longer; I just needed a
ten minute top up to get me to Marulan.
I got to Marulan and plugged in; a guy came thinking he needed to tell the
petrol motorbike not to park in the electric vehicle bay, but then realised
that the plug was going into my bike. Kate headed off, having charged up as
well, and I waited another ten minutes or so to get a bit more charge. Then
I rode back.
I stopped, only once more - at Mac's Reef Road. I turned off and did a U
turn, then waited for the traffic to clear before trying the bike's
acceleration. Believe me when I say this bike will absolutely do a 0-100km/hr
in under four seconds! It is not a light bike, but when you pull on the power
it gets up and goes.
Here is my basic review, given that experience and then having ridden it for
about ten weeks around town.
The absolute best feature of the Energica Experia is that it is perfectly
comfortable riding around town. Ease on the throttle and it gently takes off
at the traffic lights and keeps pace with the traffic. Ease off, and it
gently comes to rest with regenerative braking and a light touch on the rear
brake after stopping to hold it still. If you want to take off faster, wind
the throttle on more. It is not temperamental or twitchy, and you have no
annoying gears and clutch to balance.
In fact, I feel much more confident lane filtering, because before I would
have to have the clutch ready and be prepared to give the Tiger Sport lots of
throttle lest I accidentally stall it in front of an irate line of traffic.
With the Experia, I can simply wait peacefully - using no power - and then
when the light goes green I simply twist on the throttle and I am away ahead
of even the most aggressive car driver.
It is amazingly empowering.
I'm not going to bore you with the stats - you can probably look them up
yourself if you care. The main thing to me is that it has DC fast charging,
and watching 75KW go into a 22.5KWHr battery is just a little bit terrifying
as well as incredibly cool. The stated range of 250km on a charge at highway
speeds is absolutely correct, from my experience riding it down from Sydney.
And that plus the fast charging means that I think it is going to be quite
reasonable to tour on this bike, stopping off at fast or even mid-level
chargers - even a boring 22KW charger can fill the battery up in an hour.
The touring group I travel with stops often enough that if those stops can be
top ups, I will not hold anyone up.
Some time in the near future I hope to have a nice fine day where I can take
it out on the Cotter Loop. This is an 80km stretch of road that goes west of
Canberra into the foothills of the Brindabella Ranges, out past the Deep
Space Tracking Station and Tidbinbilla Nature Reserve. It's a great
combination of curving country roads and hilly terrain, and reasonably well
maintained as well. I did that on the Tiger Sport, with a GoPro, before I
sold it - and if I can ever convince PiTiVi to actually compile the video
from it I will put that hour's ride up on a platform somewhere.
I want to do that as much to show off Canberra's scenery as to show off the
bike.
And if the CATL battery capacity improvement comes through to the rest of the
industry, and we get bikes that can do 400km to 500km on a charge, then
electric motorbike touring really will be no different to petrol motorbike
touring. The Experia is definitely at the forefront of that change, but it
is definitely possible on this bike.
Rustup (the community package manage for the Rust language) was starting to really suffer : CI times were up at ~ one hour.
We’ve made some strides in bringing this down.
Caching factory for test scenarios
The first thing, which achieved about a 30% reduction in test time was to stop recreating all the test context every time.
Rustup tests the download/installation/upgrade of distributions of Rust. To avoid downloading gigabytes in the test suite, the suite creates mocks of the published Rust artifacts. These mocks are GPG signed and compressed with multiple compression methods, both of which are quite heavyweight operations to perform – and not actually the interesting code under test to execute.
Previously, every test was entirely hermetic, and usually the server state was also unmodified.
There were two cases where the state was modified. One, a small number of tests testing error conditions such as GPG signature failures. And two, quite a number of tests that were testing temporal behaviour: for instance, install nightly at time A, then with a newer server state, perform a rustup update and check a new version is downloaded and installed.
We’re partway through this migration, but compare these two tests:
The former version mutates the date with set_current_dist_date; the new version uses two scenarios, one for the earlier time, and one for the later time. This permits the server state to be constructed only once. On a per-test basis it can move as much as 50% of the time out of the test.
Single binary for the integration test suite
The next major gain was moving from having 14 separate integration test binaries to just one. This reduces the link cost of linking the test binaries, all of which link in the same library. It also permits us to see unused functions in our test support library, which helps with cleaning up cruft rather than having it accumulate.
Hard linking rather than copying ‘rustup-init’
Part of the test suite for each test is setting up an installed rustup environment. Why not start from scratch every time? Well, we obviously have tests that do that, but most tests are focused on steps beyond the new-user case. Setting up an installed rustup environment has a few steps, but particular ones are copying a binary of rustup into the test sandbox, and hard linking it under various names: cargo, rustc, rustup etc.
A debug build of rustup is ~20MB. Running 400 tests means about 8GB of IO; on some platforms most of that IO won’t hit disk, on others it will.
In review now is a PR that changes the initial copy to a hardlink: we hardlink the rustup-init built by cargo into each test, and then hardlink that to the various binaries. That saves 8GB of IO, which isn’t much from some perspectives, but it adds pressure on the page cache, and is wasted work. One wrinkle is a very low max-links limit on NTFS of 1023; to mitigate that we count the links made to rustup-init and generate a new inode for the original to avoid failures happening.
Future work
In GitHub actions this lowers our test time to 19m for Linux, 24m for Windows, which is a lot better but not great.
I plan on experimenting with separate actions for building release artifacts and doing CI tests – at the moment we have the same action do both, but they don’t share artifacts in the cache in any meaningful way, so we can probably gain parallelism there, as well as turning off release builds entirely for CI.
We should finish the cached test context work and use it everywhere.
Also we’re looking at having less integration tests and more narrow close to the code tests.
I have long said “Long Malaysians, Short Malaysia” in conversation to many. Maybe it took me a while to tweet it, but this was the first example: Dec 29, 2021. I’ve tweeted it a lot more since.
Malaysia has a 10th Prime Minister, but in general, it is a very precarious partnership. Consider it, same shit, different day?
5/n: Otherwise, there will be no change.
So change via “purported democracy” is never going to happen with a country like Malaysia, rotten to the core. It is a crazy dream.
I just have to get off the Malaysian news diet. Malaysians elsewhere, are generally very successful. Malaysians suffering by their daily doldrums, well, they just need to wake up, see the light, and succeed.
In the end, as much as people paraphrase, ask not what the country can do for you, legitimately, this is your life, and you should be taking good care of yourself and your loved ones. You succeed, despite of. Politics and the state happens, regardless of.
Me, personally? Ideas are abound for how to get Malaysians who see the light, to succeed elsewhere. And if I read, and get angry at something (tweet rage?), I’m going to pop RM50 into an investment account, which should help me get off this poor habit. I’ll probably also just cut subscriptions to Malaysian news things… Less exposure, is actually better for you. I can’t believe that it has taken me this long to realise this.
I did poorly blogging last year. Oops. I think to myself when I read, This Thing Still On?, I really have to do better in 2023. Maybe the catalyst is the fact that Twitter is becoming a shit show. I doubt people will leave the platform in droves, per se, but I think we are coming back to the need for decentralised blogs again.
I have 477 days to becoming 40. I ditched the Hobonich Techo sometime in 2022, and just focused on the Field Notes, and this year, I’ve got a Monocle x Leuchtturm1917 + Field Notes combo (though it seems my subscription lapsed Winter 2022, I should really burn down the existing collection, and resubscribe).
2022 was pretty amazing. Lots of work. Lots of fun. 256 days on the road (what a number), 339,551km travelled, 49 cities, 20 countries.
The getting back into doing, and not being afraid of experimenting in public is what 2023 is all about. The Year of The Rabbit is upon us tomorrow, hence why I don’t mind a little later Hello 2023 :)
Get back into the habit of doing. And publishing by learning and doing. No fear. Not that I wasn’t doing, but its time to be prolific with what’s been going on.
I like using Catalyst Cloud to host some of my personal sites. In the past I used to use CAcert for my TLS certificates, but more recently I've been using Let's Encrypt for my TLS certificates as they're trusted in all browsers. Currently the LoadBalancer as a Service (LBaaS) in Catalyst Cloud doesn't have built in support for Let's Encrypt. I could use an apache2/nginx proxy and handle the TLS termination there and have that manage the Let's Encrypt lifecycle, but really, I'd rather use LBaaS.
So I thought I'd set about working out how to get Dehydrated (the Let's Encrypt client I've been using) to drive LBaaS (known as Octavia). I figured this would be of interest to other people using Octavia with OpenStack in general, not just Catalyst Cloud.
There's a few things you need to do. These instructions are specific to Debian:
Install and configure Dehydrated to create the certificates for the domain(s) you want.
apt install barbican
Create the LoadBalancer (use the API, ClickOps, whatever), just forward port 80 for now (see sample Apache configs below).
Save the sample hook.sh below to /etc/dehydrated/hook.sh, you'll probably need to customise it, mine is a bit more complicated!
Insert the UUID of your LoadBalancer in hook.sh where LB_LISTENER is set.
Create /etc/dehydrated/catalystcloud/password as described in hook.sh
Save OpenRC file from the Catalyst Cloud dashboard as /etc/dehydrated/catalystcloud/openrc.sh
Install jq, openssl and the openstack tools, on Debian this is:
You should be able to rename the latest certs /var/lib/dehydrated/certs/$DOMAIN and then run dehydrated -c to have it reissue and then deploy a cert.
As we're using HTTP-01 Challenge Type here, you need to have the LoadBalancer forwarding port 80 to your website to allow for the challenge response. It is good practice to have a redirect to HTTPS, here's an example virtual host for Apache:
You all also need this in /etc/apache2/conf-enabled/letsencrypt.conf:
Alias /.well-known/acme-challenge /var/lib/dehydrated/acme-challenges
<Directory /var/lib/dehydrated/acme-challenges>
Options None
AllowOverride None
# Apache 2.x
<IfModule !mod_authz_core.c>
Order allow,deny
Allow from all
</IfModule>
# Apache 2.4
<IfModule mod_authz_core.c>
Require all granted
</IfModule>
</Directory>
And that should be all that you need to do. Now, when Dehydrated updates your certificate, it should update your LoadBalancer as well!
Sample hook.sh:
deploy_cert() {
local DOMAIN="${1}" KEYFILE="${2}" CERTFILE="${3}" FULLCHAINFILE="${4}" \
CHAINFILE="${5}" TIMESTAMP="${6}"
shift 6
# File contents should be:
# export OS_PASSWORD='your password in here'
. /etc/dehydrated/catalystcloud/password
# OpenRC file from the Catalyst Cloud dashboard
. /etc/dehydrated/catalystcloud/openrc.sh --no-token
# UUID of the LoadBalancer to be managed
LB_LISTENER='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'
# Barbican uses P12 files, we need to make one.
P12=$(readlink -f $KEYFILE \
| sed -E 's/privkey-([0-9]+)\.pem/barbican-\1.p12/')
openssl pkcs12 -export -inkey $KEYFILE -in $CERTFILE -certfile \
$FULLCHAINFILE -passout pass: -out $P12
# Keep track of existing certs for this domain (hopefully no more than 100)
EXISTING_URIS=$(openstack secret list --limit 100 \
-c Name -c 'Secret href' -f json \
| jq -r ".[]|select(.Name | startswith(\"$DOMAIN\"))|.\"Secret href\"")
# Upload the new cert
NOW=$(date +"%s")
openstack secret store --name $DOMAIN-$TIMESTAMP-$NOW -e base64 \
-t "application/octet-stream" --payload="$(base64 < $P12)"
NEW_URI=$(openstack secret list --name $DOMAIN-$TIMESTAMP-$NOW \
-c 'Secret href' -f value) \
|| unset NEW_URI
# Change LoadBalancer to use new cert - if the old one was the default,
# change the default. If the old one was in the SNI list, update the
# SNI list.
if [ -n "$EXISTING_URIS" ]; then
DEFAULT_CONTAINER=$(openstack loadbalancer listener show $LB_LISTENER \
-c default_tls_container_ref -f value)
for URI in $EXISTING_URIS; do
if [ "x$URI" = "x$DEFAULT_CONTAINER" ]; then
openstack loadbalancer listener set $LB_LISTENER \
--default-tls-container-ref $NEW_URI
fi
done
SNI_CONTAINERS=$(openstack loadbalancer listener show $LB_LISTENER \
-c sni_container_refs -f value | sed "s/'//g" | sed 's/^\[//' \
| sed 's/\]$//' | sed "s/,//g")
for URI in $EXISTING_URIS; do
if echo $SNI_CONTAINERS | grep -q $URI; then
SNI_CONTAINERS=$(echo $SNI_CONTAINERS | sed "s,$URI,$NEW_URI,")
openstack loadbalancer listener set $LB_LISTENER \
--sni-container-refs $SNI_CONTAINERS
fi
done
# Remove old certs
for URI in $EXISTING_URIS; do
openstack secret delete $URI
done
fi
}
HANDLER="$1"; shift
#if [[ "${HANDLER}" =~ ^(deploy_challenge|clean_challenge|sync_cert|deploy_cert|deploy_ocsp|unchanged_cert|invalid_challenge|request_failure|generate_csr|startup_hook|exit_hook)$ ]]; then
if [[ "${HANDLER}" =~ ^(deploy_cert)$ ]]; then
"$HANDLER" "$@"
fi
We’ve done this a number of times over the last decade, from OSDC to LCA. The idea is to provide a free psychologist or counsellor at an in-person conference. Attendees can do an anonymous booking by taking a stickynote (with the timeslot) from a signup sheet, and thus get a free appointment.
Many people find it difficult taking the first (very important) step towards getting professional help, and we’ve received good feedback that this approach indeed assists.
So far we’ve always focused on open source conferences. Now we’re moving into information security! First BrisSEC 2022 (Friday 29 April at the Hilton in Brisbane, QLD) and then AusCERT 2022 (10-13 May at the Star Hotel, Gold Coast QLD). The awesome and geek friendly Dr Carla Rogers will be at both events.
How does this get funded? Well, we’ve crowdfunded some, nudged sponsors, most mostly it gets picked up by the conference organisers (aka indirectly by the sponsors, mostly).
If you’re a conference organiser, or would like a particular upcoming conference to offer this service, do drop us a line and we’re happy to chase it up for you and help the organisers to make it happen. We know how to run that now.
In-person is best. But for virtual conferences, sure contact us as well.
The hack day didn’t go as well as I hoped, but didn’t go too badly. There was smaller attendance than hoped and the discussion was mostly about things other than FLOSS. But everyone who attended had fun and learned interesting things so generally I think it counts as a success. There was discussion on topics including military hardware, viruses (particularly Covid), rocketry, and literature. During the discussion one error in a Wikipedia page was discussed and hopefully we can get that fixed.
I think that everyone who attended will be interested in more such meetings. Overall I think this is a reasonable start to the Hack Day meetings, when I previously ran such meetings they often ended up being more social events than serious hacking events and that’s OK too.
One conclusion that we came to regarding meetings is that they should always be well announced in email and that the iCal file isn’t useful for everyone. Discussion continues on the best methods of announcing meetings but I anticipate that better email will get more attendance.
The March 2022 meeting went reasonably well. Everyone seemed to have fun and learn useful things about computers. After 2 hours my Internet connection dropped out which stopped the people who were using VMs from doing the tutorial. Fortunately most people seemed ready for a break so we ended the meeting. The early and abrupt ending of the meeting was a disappointment but it wasn’t too bad, the meeting would probably only have gone for another half hour otherwise.
The BigBlueButton system was shown to be effective for training when one person got confused with the Debian package configuration options for Postfix and they were able to share the window with everyone else to get advice. I was also confused by that stage.
Future Meetings
The main feature of the meeting was training in setting up a mailserver with Postfix, here are the lecture notes for it [1]. The consensus at the end of the meeting was that people wanted more of that for the April meeting. So for the April meeting I will add to the Postfix Training to include SpamAssassin, SPF, DKIM, and DMARC. For the start of the next meeting instead of providing bare Debian installations for the VMs I’ll provide a basic Postfix/Dovecot setup so people can get straight into SpamAssassin etc.
For the May meeting training on SE Linux was requested.
Social Media
Towards the end of the meeting we discussed Matrix and federated social media. LUV has a Matrix server and I can give accounts to anyone who’s involved in FOSS in the Australia and New Zealand area. For Mastodon the NZOSS Mastodon server [2] seems like a good option. I have an account there to try Mastodon, my Mastodon address is @etbe@mastodon.nzoss.nz .
We are going to make Matrix a primary communication method for the Flounder group, the room is #flounder:luv.asn.au . My Matrix address is @etbe:luv.asn.au .
We also have a new URL for the blog and events. See the right sidebar for the link to the iCal file which can be connected to Google Calendar and most online calendaring systems.
We just had the first Flounder meeting which went well. Had some interesting discussion of storage technology, I learnt a few new things. Some people did the ZFS training and BTRFS training and we had lots of interesting discussion.
Andrew Pam gave a summary of new things in Linux and talked about the sites lwn.net, gamingonlinux.com, and cnx-software.com that he uses to find Linux news. One thing he talked about is the latest developments with SteamDeck which is driving Linux support in Steam games. The site protondb.com tracks Linux support in Steam games.
We had some discussion of BPF, for an introduction to that technology see the BPF lecture from LCA 2022.
Next Meeting
The next meeting (Saturday 5th of March 1PM Melbourne time) will focus on running your own mail server which is always of interest to people who are interested in system administration and which is probably of more interest than usual because of Google forcing companies with “a legacy G Suite subscription” to transition to a more expensive “Business family” offering.
I “recently” wrote about obtaining a new (to me, actually quite old) computer over in The Apple Power Macintosh 7200/120 PC Compatible (Part 1). This post is a bit of a detour, but may help others understand why some images they download from the internet don’t work.
Disk partitioning is (of course) a way to divide up a single disk into multiple volumes (partitions) for different uses. While the idea is similar, computer platforms over the ages have done this in a variety of different ways, with varying formats on disk, and varying limitations. The ones that you’re most likely to be familiar with are the MBR partitioning scheme (from the IBM PC), and the GPT partitioning scheme (common for UEFI systems such as the modern PC and Mac). One you’re less likely to be familiar with is the Apple Partition Map scheme.
The way all IBM PCs and compatibles worked from the introduction of MS-DOS 2.0 in 1983 until some time after 2005 was the Master Boot Record partitioning scheme. It was outrageously simple: of the first 512 byte sector of a disk, the first 446 bytes was for the bootstrapping code (the “boot sector”), the last 2 bytes were for the magic two bytes telling the BIOS this disk was bootable, and the other 64 bytes were four entries of 16 bytes, each describing a disk partition. The Wikipedia page is a good overview of what it all looks like. Since “four partitions should be enough for anybody” wasn’t going to last, DOS 3.2 introduced “extended partitions” which was just using one of those 4 partitions as another similar data structure that could point to more partitions.
In the 1980s (similar to today), the Macintosh was, of course, different. The Apple Partition Map is significantly more flexible than the MBR on PCs. For a start, you could have more than four partitions! You could actually have a lot more than four partitions, as the Apple Partition Map is a single 512-byte sector for each partition, and the partition map is itself a partition. Instead of being block 0 (like the MBR is), it actually starts at block 1, and is contiguous (The Driver Descriptor Record is what’s at block 0). So, once created, it’s hard to extend. Typically it’d be created as 64×512-byte entries, for 32kb… which turns out is actually about enough for anyone.
The Inside Macintosh reference on the SCSI Manager goes through more detail as to these structures. If you’re wondering what language all the coding examples are in, it’s Pascal – which was fairly popular for writing Macintosh applications in back in the day.
But the actual partition map isn’t the “interesting” part of all this (and yes, the quotation marks are significant here), because Macs are pretty darn finicky about what disks to boot off, which gets to be interesting if you’re trying to find a CD-ROM image on the internet from which to boot, and then use to install an Operating System from.
I never programmed a 1980s Macintosh actually in the 1980s. It was sometime in the early 1990s that I first experienced Microsoft Basic for the Macintosh. I’d previously (unknowingly at the time as it was branded Commodore) experienced Microsoft BASIC on the Commodore 16, Commodore 64, and even the Apple ][, but the Macintosh version was something else. It let you do some pretty neat things such as construct a GUI with largely the same amount of effort as it took to construct a Text based UI on the micros I was familiar with.
Okay, to be fair, I’d also dabbled in Microsoft QBasic that came bundled with MS-DOS of the era, which let you do a whole bunch of graphics – so you could theoretically construct a GUI with it. Something I did attempt to do. Programming on the Mac was so much easier to construct a GUI.
Of course, Microsoft Basic wasn’t the preferred way to program on the Macintosh. At that time it was largely Pascal, with C being something that also existed – but you were going to see Pascal in Inside Macintosh. It was probably somewhat fortuitous that I’d poked at Pascal a bit as something alternate to look at in the high school computing classes. I can only remember using TurboPascal on DOS systems and never actually writing Pascal on the Macintosh.
By the middle part of the 1990s though, I was firmly incompetently writing C on the Mac. No doubt the quality of my code increased after I’d done some university courses actually covering the language rather than the only practical way I had to attempt to write anything useful being looking at Inside Macintosh examples in Pascal and “C for Dummies” which was very not-Macintosh. Writing C on UNIX/Linux was a lot easier – everything was made for it, including Actual Documentation!
Anyway, in the early 2000s I ran MacOS X for a bit on my white iBook G3, and did a (very) small amount of any GUI / Project Builder (the precursor to Xcode) related development – instead largely focusing on command line / X11 things. The latest coolness being to use Objective-C to program applications (unless you were bringing over your Classic MacOS Carbon based application, then you could still write C). Enter some (incompetent) Objective-C coding!
Then Apple went to x86, so the hardware ceased being interesting, and I had no reason to poke at it even as a side effect of having hardware that could run the software stack. Enter a long-ass time of Debian, Ubuntu, and Fedora on laptops.
Come 2022 though, and (for reasons I should really write up), I’m poking at a Mac again and it’s now Swift as the preferred way to write apps. So, I’m (incompetently) hacking away at Swift code. I have to admit, it’s pretty nice. I’ve managed to be somewhat productive in a relative short amount of time, and all the affordances in the language gear towards the kind of safety that is a PITA when coding in C.
So this is my WIP utility to be able to import photos from a Shotwell database into the macOS Photos app:
There’s a lot of rough edges and unknowns left, including how to actually do the import (it looks like there’s going to be Swift code doing AppleScript things as the PhotoKit API is inadequate). But hey, some incompetent hacking in not too much time has a kind-of photo browser thing going on that feels pretty snappy.
Recently I read Michael Snoyman’s post on combining Axum, Hyper, Tonic and Tower. While his solution worked, it irked me – it seemed like there should be a much tighter solution possible.
I can deep dive into the code in a later post perhaps, but I think there are four points of difference. One, since the post was written Axum has started boxing its routes : so the enum dispatch approach taken, which delivers low overheads actually has no benefits today.
Two, while writing out the entire type by hand has some benefits, async code is much more pithy.
Thirdly, the code in the post is entirely generic, except the routing function itself.
And fourth, the outer Service<AddrStream> is an unnecessary layer to abstract over: given the similar constraints – the inner Service must take Request<..>, it is possible to just not use a couple of helpers and instead work directly with Service<Request...>.
So, onto a pithier version.
First, the app server code itself.
use std::{convert::Infallible, net::SocketAddr};
use axum::routing::get;
use hyper::{server::conn::AddrStream, service::make_service_fn};
use hyper::{Body, Request};
use tonic::async_trait;
use demo::echo_server::{Echo, EchoServer};
use demo::{EchoReply, EchoRequest};
struct MyEcho;
#[async_trait]
impl Echo for MyEcho {
async fn echo(
&self,
request: tonic::Request<EchoRequest>,
) -> Result<tonic::Response<EchoReply>, tonic::Status> {
Ok(tonic::Response::new(EchoReply {
message: format!("Echoing back: {}", request.get_ref().message),
}))
}
}
#[tokio::main]
async fn main() {
let addr = SocketAddr::from(([0, 0, 0, 0], 3000));
let axum_service = axum::Router::new().route("/", get(|| async { "Hello world!" }));
let grpc_service = tonic::transport::Server::builder()
.add_service(EchoServer::new(MyEcho))
.into_service();
let both_service =
demo_router::Router::new(axum_service, grpc_service, |req: &Request<Body>| {
Ok::<bool, Infallible>(
req.headers().get("content-type").map(|x| x.as_bytes())
== Some(b"application/grpc"),
)
});
let make_service = make_service_fn(move |_conn: &AddrStream| {
let both_service = both_service.clone();
async { Ok::<_, Infallible>(both_service) }
});
let server = hyper::Server::bind(&addr).serve(make_service);
if let Err(e) = server.await {
eprintln!("server error: {}", e);
}
}
Note the Router: it takes the two services and Fn to determine which to use on any given request. Then we just drop that composed service into make_service_fn and we’re done.
Next up we have the Router implementation. This is generic across any two Service<Request<...>> types as long as they are both Into<Bytes> for their Data, and Into<Box<dyn Error>> for errors.
Interesting things here – I use boxed_unsync to abstract over the body concrete type, and I implement the future using async code rather than as a separate struct. It becomes much smaller even after a few bits of extra type constraining.
One thing that flummoxed me for a little was the need to capture the future for the underlying response outside of the async block. Failing to do so provokes a 'static requirement which was tricky to debug. Fortunately there is a bug on making this easier to diagnose in rustc already. The underlying problem is that if you create the async block, and then dereference self, the type for impl of .first has to live an arbitrary time. Whereas by capturing the future immediately, only the impl of the future has to live an arbitrary time, and that doesn’t then require changing the signature of the function.
This is almost worth turning into a crate – I couldn’t see an existing one when I looked, though it does end up rather small – < 100 lines. What do you all think?
Since PM Scott Morrison did not announce the federal election date last week, it will now be held somewhere between March and May (see the post from ABC’s Antony Green for details). Various aspects of elections are covered in the Civics & Citizenship Australian Curriculum in Years 4, 5 and 6. Students are interested in […]
I’m attending the https://linux.conf.au/ conference online this weekend, which is always a good opportunity for some sideline hacking.
I found something boneheaded doing that today.
There have been a few times while inventing the OpenHMD Rift driver where I’ve noticed something strange and followed the thread until it made sense. Sometimes that leads to improvements in the driver, sometimes not.
In this case, I wanted to generate a graph of how long the computer vision processing takes – from the moment each camera frame is captured until poses are generated for each device.
To do that, I have a some logging branches that output JSON events to log files and I write scripts to process those. I used that data and produced:
Two things caught my eye in this graph. The first is the way the baseline latency (pink lines) increases from ~20ms to ~58ms. The 2nd is the quantisation effect, where pose latencies are clearly moving in discrete steps.
Neither of those should be happening.
Camera frames are being captured from the CV1 sensors every 19.2ms, and it takes that 17-18ms for them to be delivered across the USB. Depending on how many IR sources the cameras can see, figuring out the device poses can take a different amount of time, but the baseline should always hover around 17-18ms because the fast “device tracking locked” case take as little as 1ms.
Did you see me mention 19.2ms as the interframe period? Guess what the spacing on those quantisation levels are in the graph? I recognised it as implying that something in the processing is tied to frame timing when it should not be.
OpenHMD Rift CV1 tracking timing
This 2nd graph helped me pinpoint what exactly was going on. This graph is cut from the part of the session where the latency has jumped up. What it shows is a ~1 frame delay between when the frame is received (frame-arrival-finish-local-ts) before the initial analysis even starts!
That could imply that the analysis thread is just busy processing the previous frame and doesn’t get start working on the new one yet – but the graph says that fast analysis is typically done in 1-10ms at most. It should rarely be busy when the next frame arrives.
This is where I found the bone headed code – a rookie mistake I wrote when putting in place the image analysis threads early on in the driver development and never noticed.
There are 3 threads involved:
USB service thread, reading video frame packets and assembling pixels in framebuffers
Fast analysis thread, that checks tracking lock is still acquired
Long analysis thread, which does brute-force pose searching to reacquire / match unknown IR sources to device LEDs
These 3 threads communicate using frame worker queues passing frames between each other. Each analysis thread does this pseudocode:
while driver_running:
Pop a frame from the queue
Process the frame
Sleep for new frame notification
The problem is in the 3rd line. If the driver is ever still processing the frame in line 2 when a new frame arrives – say because the computer got really busy – the thread sleeps anyway and won’t wake up until the next frame arrives. At that point, there’ll be 2 frames in the queue, but it only still processes one – so the analysis gains a 1 frame latency from that point on. If it happens a second time, it gets later by another frame! Any further and it starts reclaiming frames from the queues to keep the video capture thread fed – but it only reclaims one frame at a time, so the latency remains!
The fix is simple:
while driver_running:
Pop a frame
Process the frame
if queue_is_empty():
sleep for new frame notification
Doing that for both the fast and long analysis threads changed the profile of the pose latency graph completely.
Pose latency and inter-pose spacing after fix
This is a massive win! To be clear, this has been causing problems in the driver for at least 18 months but was never obvious from the logs alone. A single good graph is worth a thousand logs.
What does this mean in practice?
The way the fusion filter I’ve built works, in between pose updates from the cameras, the position and orientation of each device are predicted / updated using the accelerometer and gyro readings. Particularly for position, using the IMU for prediction drifts fairly quickly. The longer the driver spends ‘coasting’ on the IMU, the less accurate the position tracking is. So, the sooner the driver can get a correction from the camera to the fusion filter the less drift we’ll get – especially under fast motion. Particularly for the hand controllers that get waved around.
Before: Left Controller pose delays by sensorAfter: Left Controller pose delays by sensor
Poses are now being updated up to 40ms earlier and the baseline is consistent with the USB transfer delay.
You can also visibly see the effect of the JPEG decoding support I added over Christmas. The ‘red’ camera is directly connected to USB3, while the ‘khaki’ camera is feeding JPEG frames over USB2 that then need to be decoded, adding a few ms delay.
The latency reduction is nicely visible in the pose graphs, where the ‘drop shadow’ effect of pose updates tailing fusion predictions largely disappears and there are fewer large gaps in the pose observations when long analysis happens (visible as straight lines jumping from point to point in the trace):
Before: Left Controller posesAfter: Left Controller poses
Yes, the blog is still on. January 2004 I moved to WordPress, and it is still here January 2022. I didn’t write much last year (neither here, not experimenting with the Hey blog). I didn’t post anything to Instagram last year either from what I can tell, just a lot of stories.
August 16 2021, I realised I was 1,000 days till May 12 2024, which is when I become 40. As of today, that leads 850 days. Did I squander the last 150 days? I’m back to writing almost daily in the Hobonichi Techo (I think last year and the year before were mostly washouts; I barely scribbled anything offline).
I got a new Apple Watch Series 7 yesterday. I can say I used the Series 4 well (79% battery life), purchased in the UK when I broke my Series 0 in Edinburgh airport.
TripIt stats for last year claimed 95 days on the road. This is of course, a massive joke, but I’m glad I did get to visit London, Lisbon, New York, San Francisco, Los Angeles without issue. I spent a lot of time in Kuantan, a bunch of Langkawi trips, and also, I stayed for many months at the Grand Hyatt Kuala Lumpur during the May lockdowns (I practically stayed there all lockdown).
With 850 days to go till I’m 40, I have plenty I would like to achieve. I think I’ll write a lot more here. And elsewhere. Get back into the habit of doing. And publishing by learning and doing. No fear. Not that I wasn’t doing, but its time to be prolific with what’s been going on.
Once again time has passed, and another update on Oculus Rift support feels due! As always, it feels like I’ve been busy with work and not found enough time for Rift CV1 hacking. Nevertheless, looking back over the history since I last wrote, there’s quite a lot to tell!
In general, the controller tracking is now really good most of the time. Like, wildly-swing-your-arms-and-not-lose-track levels (most of the time). The problems I’m hunting now are intermittent and hard to identify in the moment while using the headset – hence my enthusiasm over the last updates for implementing stream recording and a simulation setup. I’ll get back to that.
Outlier Detection
Since I last wrote, the tracking improvements have mostly come from identifying and rejecting incorrect measurements. That is, if I have 2 sensors active and 1 sensor says the left controller is in one place, but the 2nd sensor says it’s somewhere else, we’ll reject one of those – choosing the pose that best matches what we already know about the controller. The last known position, the gravity direction the IMU is detecting, and the last known orientation. The tracker will now also reject observations for a time if (for example) the reported orientation is outside the range we expect. The IMU gyroscope can track the orientation of a device for quite a while, so can be relied on to identify strong pose priors once we’ve integrated a few camera observations to get the yaw correct.
It works really well, but I think improving this area is still where most future refinements will come. That and avoiding incorrect pose extractions in the first place.
Plot of headset tracking – orientation and position
The above plot is a sample of headset tracking, showing the extracted poses from the computer vision vs the pose priors / tracking from the Kalman filter. As you can see, there are excursions in both position and orientation detected from the video, but these are largely ignored by the filter, producing a steadier result.
Left Touch controller tracking – orientation and position
This plot shows the left controller being tracked during a Beat Saber session. The controller tracking plot is quite different, because controllers move a lot more than the headset, and have fewer LEDs to track against. There are larger gaps here in the timeline while the vision re-acquires the device – and in those gaps you can see the Kalman filter interpolating using IMU input only (sometimes well, sometimes less so).
Improved Pose Priors
Another nice thing I did is changes in the way the search for a tracked device is made in a video frame. Before starting looking for a particular device it always now gets the latest estimate of the previous device position from the fusion filter. Previously, it would use the estimate of the device pose as it was when the camera exposure happened – but between then and the moment we start analysis more IMU observations and other camera observations might arrive and be integrated into the filter, which will have updated the estimate of where the device was in the frame.
This is the bit where I think the Kalman filter is particularly clever: Estimates of the device position at an earlier or later exposure can improve and refine the filter’s estimate of where the device was when the camera captured the frame we’re currently analysing! So clever. That mechanism (lagged state tracking) is what allows the filter to integrate past tracking observations once the analysis is done – so even if the video frame search take 150ms (for example), it will correct the filter’s estimate of where the device was 150ms in the past, which ripples through and corrects the estimate of where the device is now.
LED visibility model
To improve the identification of devices better, I measured the actual angle from which LEDs are visible (about 75 degrees off axis) and measured the size. The pose matching now has a better idea of which LEDs should be visible for a proposed orientation and what pixel size we expect them to have at a particular distance.
Better Smoothing
I fixed a bug in the output pose smoothing filter where it would glitch as you turned completely around and crossed the point where the angle jumps from +pi to -pi or vice versa.
Improved Display Distortion Correction
I got a wide-angle hi-res webcam and took photos of a checkerboard pattern through the lens of my headset, then used OpenCV and panotools to calculate new distortion and chromatic aberration parameters for the display. For me, this has greatly improved. I’m waiting to hear if that’s true for everyone, or if I’ve just fixed it for my headset.
Persistent Config Cache
Config blocks! A long time ago, I prototyped code to create a persistent OpenHMD configuration file store in ~/.config/openhmd. The rift-kalman-filter branch now uses that to store the configuration blocks that it reads from the controllers. The first time a controller is seen, it will load the JSON calibration block as before, but it will now store it in that directory – removing a multiple second radio read process on every subsequent startup.
Persistent Room Configuration
To go along with that, I have an experimental rift-room-config branch that creates a rift-room-config.json file and stores the camera positions after the first startup. I haven’t pushed that to the rift-kalman-filter branch yet, because I’m a bit worried it’ll cause surprising problems for people. If the initial estimate of the headset pose is wrong, the code will back-project the wrong positions for the cameras, which will get written to the file and cause every subsequent run of OpenHMD to generate bad tracking until the file is removed. The goal is to have a loop that monitors whether the camera positions seem stable based on the tracking reports, and to use averaging and resetting to correct them if not – or at least to warn the user that they should re-run some (non-existent) setup utility.
Video Capture + Processing
The final big ticket item was a rewrite of how the USB video frame capture thread collects pixels and passes them to the analysis threads. This now does less work in the USB thread, so misses fewer frames, and also I made it so that every frame is now searched for LEDs and blob identities tracked with motion vectors, even when no further analysis will be done on that frame. That means that when we’re running late, it better preserves LED blob identities until the analysis threads can catch up – increasing the chances of having known LEDs to directly find device positions and avoid searching. This rewrite also opened up a path to easily support JPEG decode – which is needed to support Rift Sensors connected on USB 2.0 ports.
Session Simulator
I mentioned the recording simulator continues to progress. Since the tracking problems are now getting really tricky to figure out, this tool is becoming increasingly important. So far, I have code in OpenHMD to record all video and tracking data to a .mkv file. Then, there’s a simulator tool that loads those recordings. Currently it is capable of extracting the data back out of the recording, parsing the JSON and decoding the video, and presenting it to a partially implemented simulator that then runs the same blob analysis and tracking OpenHMD does. The end goal is a Godot based visualiser for this simulation, and to be able to step back and forth through time examining what happened at critical moments so I can improve the tracking for those situations.
To make recordings, there’s the rift-debug-gstreamer-record branch of OpenHMD. If you have GStreamer and the right plugins (gst-plugins-good) installed, and you set env vars like this, each run of OpenHMD will generate a recording in the target directory (make sure the target dir exists):
The next things that are calling to me are to improve the room configuration estimation and storage as mentioned above – to detect when the poses a camera is reporting don’t make sense because it’s been bumped or moved.
I’d also like to add back in tracking of the LEDS on the back of the headset headband, to support 360 tracking. I disabled those because they cause me trouble – the headband is adjustable relative to the headset, so the LEDs don’t appear where the 3D model says they should be and that causes jitter and pose mismatches. They need special handling.
One last thing I’m finding exciting is a new person taking an interest in Rift S and starting to look at inside-out tracking for that. That’s just happened in the last few days, so not much to report yet – but I’ll be happy to have someone looking at that while I’m still busy over here in CV1 land!
As always, if you have any questions, comments or testing feedback – hit me up at thaytan@noraisin.net or on @thaytan Twitter/IRC.
Thank you to the kind people signed up as Github Sponsors for this project!
I gave the talk On The Use and Misuse of Decorators as part of PyConline AU 2021, the second in annoyingly long sequence of not-in-person PyCon AU events. Here’s some code samples that you might be interested in:
Simple @property implementation
This shows a demo of @property-style getters. Setters are left as an exercise :)
defdemo_property(f):f.is_a_property=TruereturnfclassHasProperties:def__getattribute__(self,name):ret=super().__getattribute__(name)ifhasattr(ret,"is_a_property"):returnret()else:returnretclassDemo(HasProperties):@demo_propertydefis_a_property(self):return"I'm a property"defis_a_function(self):return"I'm a function"a=Demo()print(a.is_a_function())print(a.is_a_property)
@run (The Scoped Block)
@run is a decorator that will run the body of the decorated function, and then store the result of that function in place of the function’s name. It makes it easier to assign the results of complex statements to a variable, and get the advantages of functions having less leaky scopes than if or loop blocks.
A while ago, I wrote a post about how to build and test my Oculus CV1 tracking code in SteamVR using the SteamVR-OpenHMD driver. I have updated those instructions and moved them to https://noraisin.net/diary/?page_id=1048 – so use those if you’d like to try things out.
The pandemic continues to sap my time for OpenHMD improvements. Since my last post, I have been working on various refinements. The biggest visible improvements are:
Adding velocity and acceleration API to OpenHMD.
Rewriting the pose transformation code that maps from the IMU-centric tracking space to the device pose needed by SteamVR / apps.
Adding velocity and acceleration reporting is needed in VR apps that support throwing things. It means that throwing objects and using gravity-grab to fetch objects works in Half-Life: Alyx, making it playable now.
The rewrite to the pose transformation code fixed problems where the rotation of controller models in VR didn’t match the rotation applied in the real world. Controllers would appear attached to the wrong part of the hand, and rotate around the wrong axis. Movements feel more natural now.
Ongoing work – record and replay
My focus going forward is on fixing glitches that are caused by tracking losses or outliers. Those problems happen when the computer vision code either fails to match what the cameras see to the device LED models, or when it matches incorrectly.
Tracking failure leads to the headset view or controllers ‘flying away’ suddenly. Incorrect matching leads to controllers jumping and jittering to the wrong pose, or swapping hands. Either condition is very annoying.
Unfortunately, as the tracking has improved the remaining problems get harder to understand and there is less low-hanging fruit for improvement. Further, when the computer vision runs at 52Hz, it’s impossible to diagnose the reasons for a glitch in real time.
I’ve built a branch of OpenHMD that uses GStreamer to record the CV1 camera video, plus IMU and tracking logs into a video file.
To go with those recordings, I’ve been working on a replay and simulation tool, that uses the Godot game engine to visualise the tracking session. The goal is to show, frame-by-frame, where OpenHMD thought the cameras, headset and controllers were at each point in the session, and to be able to step back and forth through the recording.
Right now, I’m working on the simulation portion of the replay, that will use the tracking logs to recreate all the poses.
I’ve been asked more than once what it was like at the beginning of Ubuntu, before it was a company, when an email from someone I’d never heard of came into my mailbox.
We’re coming up on 20 years now since Ubuntu was founded, and I had cause to do some spelunking into IMAP archives recently… while there I took the opportunity to grab the very first email I received.
The Ubuntu long shot succeeded wildly. Of course, we liked to joke about how spammy those emails where: cold-calling a raft of Debian developers with job offers, some of them were closer to phishing attacks :). This very early one – I was the second employee (though I started at 4 days a week to transition my clients gradually) – was less so.
I think its interesting though to note how explicit a gamble this was framed as: a time limited experiment, funded for a year. As the company scaled this very rapidly became a hiring problem and the horizon had to be pushed out to 2 years to get folk to join.
And of course, while we started with arch in earnest, we rapidly hit significant usability problems, some of which were solvable with porcelain and shallow non-architectural changes, and we built initially patches, and then the bazaar VCS project to tackle those. But others were not: for instance, I recall exceeding the 32K hard link limit on ext3 due to a single long history during a VCS conversion. The sum of these challenges led us to create the bzr project, a ground up rethink of our version control needs, architecture, implementation and user-experience. While ultimately git has conquered all, bzr had – still has in fact – extremely loyal advocates, due to its laser sharp focus on usability.
Anyhow, here it is: one of the original no-name-here-yet, aka Ubuntu, introductory emails (with permission from Mark, of course). When I clicked through to the website Mark provided there was a link there to a fantastical website about a space tourist… not what I had expected to be reading in Adelaide during LCA 2004.
From: Mark Shuttleworth <xxx@xxx> To: Robert Collins <xxx@xxx> Date: Thu, 15 Jan 2004, 04:30
Tom Lord gave me your email address, I believe he’s already sent you the email that I sent him so I’m sure you have some background.
In short, I am going to fund some open source development for a year. This is part of a new project that I will be getting off the ground in the coming weeks. I don’t know where it will lead, it’s flying in the face of a stiff breeze but I think at the end of the day it will at least fund a few very good open source developers for a full year to work on the projects they like most.
One of the pieces of the puzzle is high end source code management. I’ll be looking to build an infrastructure that will manage source code for between 100 and 8000 open source projects (yes, there’s a big difference between the two, I don’t know at which end of the spectrum we will be at the end of the year but our infrastructure will have to at least be capable of scaling to the latter within two years) with upwards of 2000 developers, drawing code from a variety of sources, playing with it and spitting it out regularly in nice packages.
Arch and Subversion seem to be the two leading contenders for “next generation open source sccm”. I’d be interested in your thoughts on the two of them, and how they stack up. I’m looking to hire one person who will lead that part of the effort. They’ll work alone from home, and be responsible for two things. First, extending the tool (arch or svn) in ways that help the project. Such extensions will be released under an open source licence, and hopefully embraced by the tools maintainers and included in the mainline code for the tool. And second, they will be responsible for our large-scale implementation of SCCM, using that tool, and building the management scripts and other infrastructure to support such a large, and hopefully highly automated, set of repositories.
Would you be interested in this position? What attributes and experience do you think would make you a great person to have on the team? What would your salary expectation be, as a monthly figure, for a one year contract full time?
I’m currently on your continent, well, just off it. On Lizard Island, up North. Am headed today for Brisbane, then on the 17th to Launceston via Melbourne. If you happen to be on any of those stops, would you be interested in meeting up to discuss it further?
If you’re curious you can find out a bit more about me at www.markshuttleworth.com. This project is much lower key than some of what you’ll find there. It’s a very long shot indeed. But if at worst all that happens is a bunch of open source work gets funded at my expense I’ll feel it was money well spent.
Cheers, Mark
===== — “Good judgement comes from experience, and often experience comes from bad judgement” – Rita Mae Brown
I have always liked cryptography, and public-key cryptography in particularly. When Pretty Good Privacy (PGP) first came out in 1991, I not only started using it, also but looking at the documentation and the code to see how it worked. I created my own implementation in C using very small keys, just to better understand.
Cryptography has been running a race against both faster and cheaper computing power. And these days, with banking and most other aspects of our lives entirely relying on secure communications, it’s a very juicy target for bad actors.
About 5 years ago, the National (USA) Institute for Science and Technology (NIST) initiated a search for cryptographic algorithmic that should withstand a near-future world where quantum computers with a significant number of qubits are a reality. There have been a number of rounds, which mid 2020 saw round 3 and the finalists.
This submission caught my eye some time ago: Classic McEliece, and out of the four finalists it’s the only one that is not lattice-based [wikipedia link].
Tiny side-track, you may wonder where does the McEleice name come from? From mathematician Robert McEleice (1942-2019). McEleice developed his cryptosystem in 1978. So it’s not just named after him, he designed it. For various reasons that have nothing to do with the mathematical solidity of the ideas, it didn’t get used at the time. He’s done plenty cool other things, too. From his Caltech obituary:
He made fundamental contributions to the theory and design of channel codes for communication systems—including the interplanetary telecommunication systems that were used by the Voyager, Galileo, Mars Pathfinder, Cassini, and Mars Exploration Rover missions.
Back to lattices, there are both unknowns (aspects that have not been studied in exhaustive depth) and recent mathematical attacks, both of which create uncertainty – in the crypto sphere as well as for business and politics. Given how long it takes for crypto schemes to get widely adopted, the latter two are somewhat relevant, particularly since cyber security is a hot topic.
Lattices are definitely interesting, but given what we know so far, it is my feeling that systems based on lattices are more likely to be proven breakable than Classic McEleice, which come to this finalists’ table with 40+ years track record of in-depth analysis. Mind that all finalists are of course solid at this stage – but NIST’s thoughts on expected developments and breakthroughs is what is likely to decide the winner. NIST are not looking for shiny, they are looking for very very solid in all possible ways.
Prof Buchanan recently published implementations for the finalists, and did some benchmarks where we can directly compare them against each other.
We can see that Classic McEleice’s key generation is CPU intensive, but is that really a problem? The large size of its public key may be more of a factor (disadvantage), however the small ciphertext I think more than offsets that disadvantage.
As we’re nearing the end of the NIST process, in my opinion, fast encryption/decryption and small cyphertext, combined with the long track record of in-depth analysis, may still see Classic McEleice come out the winner.
Living in California, I’ve (sadly) grown accustomed to needing to keep track of our local air quality index (AQI) ratings, particularly as we live close to places where large wildfires happen every other year.
Last year, Josh and I bought a PurpleAir outdoor air quality meter, which has been great. We contribute our data to a collection of very local air quality meters, which is important, since the hilly nature of the North Bay means that the nearest government air quality ratings can be significantly different to what we experience here in Petaluma.
I recently went looking to pull my PurpleAir sensor data into my Home Assistant setup. Unfortunately, the PurpleAir API does not return the AQI metric for air quality, only the raw PM2.5/PM5/PM10 numbers. After some searching, I found a nice template sensor solution on the Home Assistant forums, which I’ve modernised by adding the AQI as a sub-sensor, and adding unique ID fields to each useful sensor, so that you can assign them to a location.
You’ll end up with sensors for raw PM2.5, the PM2.5 AQI value, the US EPA air quality category, air pressure, relative humidity and air pressure.
How to use this
First up, visit the PurpleAir Map, find the sensor you care about, click “get this widget�, and then “JSON�. That will give you the URL to set as the resource key in purpleair.yaml.
Adding the configuration
In HomeAssistant, add the following line to your configuration.yaml:
sensor:!includepurpleair.yaml
and then add the following contents to purpleair.yaml
-platform:restname:'PurpleAir'# Substitute in the URL of the sensor you care about. To find the URL, go# to purpleair.com/map, find your sensor, click on it, click on "Get This# Widget" then click on "JSON".resource:https://www.purpleair.com/json?key={KEY_GOES_HERE}&show={SENSOR_ID}# Only query once a minute to avoid rate limits:scan_interval:60# Set this sensor to be the AQI value.## Code translated from JavaScript found at:# https://docs.google.com/document/d/15ijz94dXJ-YAZLi9iZ_RaBwrZ4KtYeCy08goGBwnbCU/edit#value_template:>{{ value_json["results"][0]["Label"] }}unit_of_measurement:""# The value of the sensor can't be longer than 255 characters, but the# attributes can. Store away all the data for use by the templates below.json_attributes:-results-platform:templatesensors:purpleair_aqi:unique_id:'purpleair_SENSORID_aqi_pm25'friendly_name:'PurpleAirPM2.5AQI'value_template:>{% macro calcAQI(Cp, Ih, Il, BPh, BPl) -%}{{ (((Ih - Il)/(BPh - BPl)) * (Cp - BPl) + Il)|round|float }}{%- endmacro %}{% if (states('sensor.purpleair_pm25')|float) > 1000 %}invalid{% elif (states('sensor.purpleair_pm25')|float) > 350.5 %}{{ calcAQI((states('sensor.purpleair_pm25')|float), 500.0, 401.0, 500.0, 350.5) }}{% elif (states('sensor.purpleair_pm25')|float) > 250.5 %}{{ calcAQI((states('sensor.purpleair_pm25')|float), 400.0, 301.0, 350.4, 250.5) }}{% elif (states('sensor.purpleair_pm25')|float) > 150.5 %}{{ calcAQI((states('sensor.purpleair_pm25')|float), 300.0, 201.0, 250.4, 150.5) }}{% elif (states('sensor.purpleair_pm25')|float) > 55.5 %}{{ calcAQI((states('sensor.purpleair_pm25')|float), 200.0, 151.0, 150.4, 55.5) }}{% elif (states('sensor.purpleair_pm25')|float) > 35.5 %}{{ calcAQI((states('sensor.purpleair_pm25')|float), 150.0, 101.0, 55.4, 35.5) }}{% elif (states('sensor.purpleair_pm25')|float) > 12.1 %}{{ calcAQI((states('sensor.purpleair_pm25')|float), 100.0, 51.0, 35.4, 12.1) }}{% elif (states('sensor.purpleair_pm25')|float) >= 0.0 %}{{ calcAQI((states('sensor.purpleair_pm25')|float), 50.0, 0.0, 12.0, 0.0) }}{% else %}invalid{% endif %}unit_of_measurement:"bit"purpleair_description:unique_id:'purpleair_SENSORID_description'friendly_name:'PurpleAirAQIDescription'value_template:>{% if (states('sensor.purpleair_aqi')|float) >= 401.0 %}Hazardous{% elif (states('sensor.purpleair_aqi')|float) >= 301.0 %}Hazardous{% elif (states('sensor.purpleair_aqi')|float) >= 201.0 %}Very Unhealthy{% elif (states('sensor.purpleair_aqi')|float) >= 151.0 %}Unhealthy{% elif (states('sensor.purpleair_aqi')|float) >= 101.0 %}Unhealthy for Sensitive Groups{% elif (states('sensor.purpleair_aqi')|float) >= 51.0 %}Moderate{% elif (states('sensor.purpleair_aqi')|float) >= 0.0 %}Good{% else %}undefined{% endif %}entity_id:sensor.purpleairpurpleair_pm25:unique_id:'purpleair_SENSORID_pm25'friendly_name:'PurpleAirPM2.5'value_template:"{{state_attr('sensor.purpleair','results')[0]['PM2_5Value']}}"unit_of_measurement:"μg/m3"entity_id:sensor.purpleairpurpleair_temp:unique_id:'purpleair_SENSORID_temperature'friendly_name:'PurpleAirTemperature'value_template:"{{state_attr('sensor.purpleair','results')[0]['temp_f']}}"unit_of_measurement:"°F"entity_id:sensor.purpleairpurpleair_humidity:unique_id:'purpleair_SENSORID_humidity'friendly_name:'PurpleAirHumidity'value_template:"{{state_attr('sensor.purpleair','results')[0]['humidity']}}"unit_of_measurement:"%"entity_id:sensor.purpleairpurpleair_pressure:unique_id:'purpleair_SENSORID_pressure'friendly_name:'PurpleAirPressure'value_template:"{{state_attr('sensor.purpleair','results')[0]['pressure']}}"unit_of_measurement:"hPa"entity_id:sensor.purpleair
Quirks
I had difficulty getting the AQI to display as a numeric graph when I didn’t set a unit. I went with bit, and that worked just fine. 🤷�♂�
So, this idea has been brewing for a while now… try and watch all of Doctor Who. All of it. All 38 seasons. Today(ish), we started. First up, from 1963 (first aired not quite when intended due to the Kennedy assassination): An Unearthly Child. The first episode of the first serial.
A lot of iconic things are there from the start: the music, the Police Box, embarrassing moments of not quite remembering what time one is in, and normal humans accidentally finding their way into the TARDIS.
I first saw this way back when a child, where they were repeated on ABC TV in Australia for some anniversary of Doctor Who (I forget which one). Well, I saw all but the first episode as the train home was delayed and stopped outside Caulfield for no reason for ages. Some things never change.
Of course, being a show from the early 1960s, there’s some rougher spots. We’re not about to have the picture of diversity, and there’s going to be casual racism and sexism. What will be interesting is noticing these things today, and contrasting with my memory of them at the time (at least for episodes I’ve seen before), and what I know of the attitudes of the time.
“This year-ometer is not calculating properly” is a very 2020 line though (technically from the second episode).
It’s been a while since my last post about tracking support for the Oculus Rift in February. There’s been big improvements since then – working really well a lot of the time. It’s gone from “If I don’t make any sudden moves, I can finish an easy Beat Saber level” to “You can’t hide from me!” quality.
Equally, there are still enough glitches and corner cases that I think I’ll still be at this a while.
Here’s a video from 3 weeks ago of (not me) playing Beat Saber on Expert+ setting showing just how good things can be now:
Beat Saber – Skunkynator playing Expert+, Mar 16 2021
Strap in. Here’s what I’ve worked on in the last 6 weeks:
Pose Matching improvements
Most of the biggest improvements have come from improving the computer vision algorithm that’s matching the observed LEDs (blobs) in the camera frames to the 3D models of the devices.
I split the brute-force search algorithm into 2 phases. It now does a first pass looking for ‘obvious’ matches. In that pass, it does a shallow graph search of blobs and their nearest few neighbours against LEDs and their nearest neighbours, looking for a match using a “Strong” match metric. A match is considered strong if expected LEDs match observed blobs to within 1.5 pixels.
Coupled with checks on the expected orientation (matching the Gravity vector detected by the IMU) and the pose prior (expected position and orientation are within predicted error bounds) this short-circuit on the search is hit a lot of the time, and often completes within 1 frame duration.
In the remaining tricky cases, where a deeper graph search is required in order to recover the pose, the initial search reduces the number of LEDs and blobs under consideration, speeding up the remaining search.
I also added an LED size model to the mix – for a candidate pose, it tries to work out how large (in pixels) each LED should appear, and use that as a bound on matching blobs to LEDs. This helps reduce mismatches as devices move further from the camera.
LED labelling
When a brute-force search for pose recovery completes, the system now knows the identity of various blobs in the camera image. One way it avoids a search next time is to transfer the labels into future camera observations using optical-flow tracking on the visible blobs.
The problem is that even sped-up the search can still take a few frame-durations to complete. Previously LED labels would be transferred from frame to frame as they arrived, but there’s now a unique ID associated with each blob that allows the labels to be transferred even several frames later once their identity is known.
IMU Gyro scale
One of the problems with reverse engineering is the guesswork around exactly what different values mean. I was looking into why the controller movement felt “swimmy” under fast motions, and one thing I found was that the interpretation of the gyroscope readings from the IMU was incorrect.
The touch controllers report IMU angular velocity readings directly as a 16-bit signed integer. Previously the code would take the reading and divide by 1024 and use the value as radians/second.
From teardowns of the controller, I know the IMU is an Invensense MPU-6500. From the datasheet, the reported value is actually in degrees per second and appears to be configured for the +/- 2000 °/s range. That yields a calculation of Gyro-rad/s = Gyro-°/s * (2000 / 32768) * (?/180) – or a divisor of 938.734.
The 1024 divisor was under-estimating rotation speed by about 10% – close enough to work until you start moving quickly.
Limited interpolation
If we don’t find a device in the camera views, the fusion filter predicts motion using the IMU readings – but that quickly becomes inaccurate. In the worst case, the controllers fly off into the distance. To avoid that, I added a limit of 500ms for ‘coasting’. If we haven’t recovered the device pose by then, the position is frozen in place and only rotation is updated until the cameras find it again.
Exponential filtering
I implemented a 1-Euro exponential smoothing filter on the output poses for each device. This is an idea from the Project Esky driver for Project North Star/Deck-X AR headsets, and almost completely eliminates jitter in the headset view and hand controllers shown to the user. The tradeoff is against introducing lag when the user moves quickly – but there are some tunables in the exponential filter to play with for minimising that. For now I’ve picked some values that seem to work reasonably.
Non-blocking radio
Communications with the touch controllers happens through USB radio command packets sent to the headset. The main use of radio commands in OpenHMD is to read the JSON configuration block for each controller that is programmed in at the factory. The configuration block provides the 3D model of LED positions as well as initial IMU bias values.
Unfortunately, reading the configuration block takes a couple of seconds on startup, and blocks everything while it’s happening. Oculus saw that problem and added a checksum in the controller firmware. You can read the checksum first and if it hasn’t changed use a local cache of the configuration block. Eventually, I’ll implement that caching mechanism for OpenHMD but in the meantime it still reads the configuration blocks on each startup.
As an interim improvement I rewrote the radio communication logic to use a state machine that is checked in the update loop – allowing radio communications to be interleaved without blocking the regularly processing of events. It still interferes a bit, but no longer causes a full multi-second stall as each hand controller turns on.
Haptic feedback
The hand controllers have haptic feedback ‘rumble’ motors that really add to the immersiveness of VR by letting you sense collisions with objects. Until now, OpenHMD hasn’t had any support for applications to trigger haptic events. I spent a bit of time looking at USB packet traces with Philipp Zabel and we figured out the radio commands to turn the rumble motors on and off.
In the Rift CV1, the haptic motors have a mode where you schedule feedback events into a ringbuffer – effectively they operate like a low frequency audio device. However, that mode was removed for the Rift S (and presumably in the Quest devices) – and deprecated for the CV1.
With that in mind, I aimed for implementing the unbuffered mode, with explicit ‘motor on + frequency + amplitude’ and ‘motor off’ commands sent as needed. Thanks to already having rewritten the radio communications to use a state machine, adding haptic commands was fairly easy.
I’d say the biggest problem right now is unexpected tracking loss and incorrect pose extractions when I’m not expecting them. Especially my right controller will suddenly glitch and start jumping around. Looking at a video of the debug feed, it’s not obvious why that’s happening:
To fix cases like those, I plan to add code to log the raw video feed and the IMU information together so that I can replay the video analysis frame-by-frame and investigate glitches systematically. Those recordings will also work as a regression suite to test future changes.
Sensor fusion efficiency
The Kalman filter I have implemented works really nicely – it does the latency compensation, predicts motion and extracts sensor biases all in one place… but it has a big downside of being quite expensive in CPU. The Unscented Kalman Filter CPU cost grows at O(n^3) with the size of the state, and the state in this case is 43 dimensional – 22 base dimensions, and 7 per latency-compensation slot. Running 1000 updates per second for the HMD and 500 for each of the hand controllers adds up quickly.
At some point, I want to find a better / cheaper approach to the problem that still provides low-latency motion predictions for the user while still providing the same benefits around latency compensation and bias extraction.
Lens Distortion
To generate a convincing illusion of objects at a distance in a headset that’s only a few centimetres deep, VR headsets use some interesting optics. The LCD/OLED panels displaying the output get distorted heavily before they hit the users eyes. What the software generates needs to compensate by applying the right inverse distortion to the output video.
Everyone that tests the CV1 notices that the distortion is not quite correct. As you look around, the world warps and shifts annoyingly. Sooner or later that needs fixing. That’s done by taking photos of calibration patterns through the headset lenses and generating a distortion model.
Camera / USB failures
The camera feeds are captured using a custom user-space UVC driver implementation that knows how to set up the special synchronisation settings of the CV1 and DK2 cameras, and then repeatedly schedules isochronous USB packet transfers to receive the video.
Occasionally, some people experience failure to re-schedule those transfers. The kernel rejects them with an out-of-memory error failing to set aside DMA memory (even though it may have been running fine for quite some time). It’s not clear why that happens – but the end result at the moment is that the USB traffic for that camera dies completely and there’ll be no more tracking from that camera until the application is restarted.
Often once it starts happening, it will keep happening until the PC is rebooted and the kernel memory state is reset.
Occluded cases
Tracking generally works well when the cameras get a clear shot of each device, but there are cases like sighting down the barrel of a gun where we expect that the user will line up the controllers in front of one another, and in front of the headset. In that case, even though we probably have a good idea where each device is, it can be hard to figure out which LEDs belong to which device.
If we already have a good tracking lock on the devices, I think it should be possible to keep tracking even down to 1 or 2 LEDs being visible – but the pose assessment code will have to be aware that’s what is happening.
Upstreaming
April 14th marks 2 years since I first branched off OpenHMD master to start working on CV1 tracking. How hard can it be, I thought? I’ll knock this over in a few months.
Since then I’ve accumulated over 300 commits on top of OpenHMD master that eventually all need upstreaming in some way.
One thing people have expressed as a prerequisite for upstreaming is to try and remove the OpenCV dependency. The tracking relies on OpenCV to do camera distortion calculations, and for their PnP implementation. It should be possible to reimplement both of those directly in OpenHMD with a bit of work – possibly using the fast LambdaTwist P3P algorithm that Philipp Zabel wrote, that I’m already using for pose extraction in the brute-force search.
Others
I’ve picked the top issues to highlight here. https://github.com/thaytan/OpenHMD/issues has a list of all the other things that are still on the radar for fixing eventually.
Other Headsets
At some point soon, I plan to put a pin in the CV1 tracking and look at adapting it to more recent inside-out headsets like the Rift S and WMR headsets. I implemented 3DOF support for the Rift S last year, but getting to full positional tracking for that and other inside-out headsets means implementing a SLAM/VIO tracking algorithm to track the headset position.
Once the headset is tracking, the code I’m developing here for CV1 to find and track controllers will hopefully transfer across – the difference with inside-out tracking is that the cameras move around with the headset. Finding the controllers in the actual video feed should work much the same.
Sponsorship
This development happens mostly in my spare time and partly as open source contribution time at work at Centricular. I am accepting funding through Github Sponsorships to help me spend more time on it – I’d really like to keep helping Linux have top-notch support for VR/AR applications. Big thanks to the people that have helped get this far.
Why that particular date? It’s Vincent van Gogh’s birthday (1853), and there is a fairly strong argument that the Dutch painter suffered from bipolar (among other things).
The image on the side is Vincent’s drawing “Worn Out” (from 1882), and it seems to capture the feeling rather well – whether (hypo)manic, depressed, or mixed. It’s exhausting.
Bipolar is complicated, often undiagnosed or misdiagnosed, and when only treated with anti-depressants, it can trigger the (hypo)mania – essentially dragging that person into that state near-permanently.
Have you heard of Bipolar II?
Hypo-mania is the “lesser” form of mania that distinguishes Bipolar I (the classic “manic depressive” syndrome) from Bipolar II. It’s “lesser” only in the sense that rather than someone going so hyper they may think they can fly (Bipolar I is often identified when someone in manic state gets admitted to hospital – good catch!) while with Bipolar II the hypo-mania may actually exhibit as anger. Anger in general, against nothing in particular but potentially everyone and everything around them. Or, if it’s a mixed episode, anger combined with strong negative thoughts. Either way, it does not look like classic mania. It is, however, exhausting and can be very debilitating.
Bipolar II people often present to a doctor while in depressed state, and GPs (not being psychiatrists) may not do a full diagnosis. Note that D.A.S. and similar test sheets are screening tools, they are not diagnostic. A proper diagnosis is more complex than filling in a form some questions (who would have thought!)
Call to action
If you have a diagnosis of depression, only from a GP, and are on medication for this, I would strongly recommend you also get a referral to a psychiatrist to confirm that diagnosis.
Our friends at the awesome Black Dog Institute have excellent information on bipolar, as well as a quick self-test – if that shows some likelihood of bipolar, go get that referral and follow up ASAP.
I will be writing more about the topic in the coming time.
This post documented an older method of building SteamVR-OpenHMD. I moved them to a page here. That version will be kept up to date for any future changes, so go there.
I’ve had a few people ask how to test my OpenHMD development branch of Rift CV1 positional tracking in SteamVR. Here’s what I do:
It is important to configure in release mode, as the kalman filtering code is generally too slow for real-time in debug mode (it has to run 2000 times per second)
Please note – only Rift sensors on USB 3.0 ports will work right now. Supporting cameras on USB 2.0 requires someone implementing JPEG format streaming and decoding.
It can be helpful to test OpenHMD is working by running the simple example. Check that it’s finding camera sensors at startup, and that the position seems to change when you move the headset:
Calibrate your expectations for how well tracking is working right now! Hint: It’s very experimental
Start SteamVR. Hopefully it should detect your headset and the light(s) on your Rift Sensor(s) should power on.
Meson
I prefer the Meson build system here. There’s also a cmake build for SteamVR-OpenHMD you can use instead, but I haven’t tested it in a while and it sometimes breaks as I work on my development branch.
I spent some time this weekend implementing a couple of my ideas for improving the way the tracking code in OpenHMD filters and rejects (or accepts) possible poses when trying to match visible LEDs to the 3D models for each device.
In general, the tracking proceeds in several steps (in parallel for each of the 3 devices being tracked):
Do a brute-force search to match LEDs to 3D models, then (if matched)
Assign labels to each LED blob in the video frame saying what LED they are.
Send an update to the fusion filter about the position / orientation of the device
Then, as each video frame arrives:
Use motion flow between video frames to track the movement of each visible LED
Use the IMU + vision fusion filter to predict the position/orientation (pose) of each device, and calculate which LEDs are expected to be visible and where.
Try and match up and refine the poses using the predicted pose prior and labelled LEDs. In the best case, the LEDs are exactly where the fusion predicts they’ll be. More often, the orientation is mostly correct, but the position has drifted and needs correcting. In the worst case, we send the frame back to step 1 and do a brute-force search to reacquire an object.
The goal is to always assign the correct LEDs to the correct device (so you don’t end up with the right controller in your left hand), and to avoid going back to the expensive brute-force search to re-acquire devices as much as possible
What I’ve been working on this week is steps 1 and 3 – initial acquisition of correct poses, and fast validation / refinement of the pose in each video frame, and I’ve implemented two new strategies for that.
Gravity Vector matching
The first new strategy is to reject candidate poses that don’t closely match the known direction of gravity for each device. I had a previous implementation of that idea which turned out to be wrong, so I’ve re-worked it and it helps a lot with device acquisition.
The IMU accelerometer and gyro can usually tell us which way up the device is (roll and pitch) but not which way they are facing (yaw). The measure for ‘known gravity’ comes from the fusion Kalman filter covariance matrix – how certain the filter is about the orientation of the device. If that variance is small this new strategy is used to reject possible poses that don’t have the same idea of gravity (while permitting rotations around the Y axis), with the filter variance as a tolerance.
Partial tracking matches
The 2nd strategy is based around tracking with fewer LED correspondences once a tracking lock is acquired. Initial acquisition of the device pose relies on some heuristics for how many LEDs must match the 3D model. The general heuristic threshold I settled on for now is that 2/3rds of the expected LEDs must be visible to acquire a cold lock.
With the new strategy, if the pose prior has a good idea where the device is and which way it’s facing, it allows matching on far fewer LED correspondences. The idea is to keep tracking a device even down to just a couple of LEDs, and hope that more become visible soon.
While this definitely seems to help, I think the approach can use more work.
Status
With these two new approaches, tracking is improved but still quite erratic. Tracking of the headset itself is quite good now and for me rarely loses tracking lock. The controllers are better, but have a tendency to “fly off my hands” unexpectedly, especially after fast motions.
I have ideas for more tracking heuristics to implement, and I expect a continuous cycle of refinement on the existing strategies and new ones for some time to come.
For now, here’s a video of me playing Beat Saber using tonight’s code. The video shows the debug stream that OpenHMD can generate via Pipewire, showing the camera feed plus overlays of device predictions, LED device assignments and tracked device positions. Red is the headset, Green is the right controller, Blue is the left controller.
Initial tracking is completely wrong – I see some things to fix there. When the controllers go offline due to inactivity, the code keeps trying to match LEDs to them for example, and then there are some things wrong with how it’s relabelling LEDs when they get incorrect assignments.
After that, there are periods of good tracking with random tracking losses on the controllers – those show the problem cases to concentrate on.
These lack of updates are also likely because I’ve been quite caught up with stuff.
Monday I had a steak from Bay Leaf Steakhouse for dinner. It was kind of weird eating it from packs, but then I’m reminded you could do this in economy class. Tuesday I wanted to attempt to go vegetarian and by the time I was done with a workout, the only place was a chap fan shop (Leong Heng) where I had a mixture of Chinese and Indian chap fan. The Indian stall is run by an ex-Hyatt staff member who immediately recognised me! Wednesday, Alice came to visit, so we got to Hanks, got some alcohol, and managed a smorgasbord of food from Pickers/Sate Zul/Lila Wadi. Night ended very late, and on Thursday, visited Hai Tian for their famous salted egg squid and prawns in a coconut shell. Friday was back to being normal, so I grabbed a pizza from Mint Pizza (this time I tried their Aussie variant). Saturday, today, I hit up Rasa Sayang for some matcha latte, but grabbed food from Classic Pilot Cafe, which Faeeza owns! It was the famous salted egg chicken, double portion, half rice.
As for workouts, I did sign up for Mantas but found it pretty hard to do, timezone wise. I did spend a lot of time jogging on the beach (this has been almost a daily affair). Monday I also did 2 MD workouts, Tuesday 1 MD workout, Wednesday half a MD workout, Thursday I did a Ping workout at Pwrhouse (so good!), Friday 1 MD workout, and Saturday an Audrey workout at Pwrhouse and 1 MD workout.
Wednesday I also found out that Rasmus passed away. Frankly, there are no words.
Thursday, my Raspberry Pi 400 arrived. I set it up in under ten minutes, connecting it to the TV here. It “just works”. I made a video, which I should probably figure out how to upload to YouTube after I stitch it together. I have to work on using it a lot more.
COVID-19 cases are through the roof in Malaysia. This weekend we’ve seen two days of case breaking records, with today being 5,728 (yesterday was something close). Nutty. Singapore suspended the reciprocal green lane (RGL) agreement with Malaysia for the next 3 months.
I’ve managed to finish Bridgerton. I like the score. Finding something on Netflix is proving to be more difficult, regardless of having a VPN. Honestly, this is why Cable TV wins… linear programming that you’re just fed.
Stock market wise, I’ve been following the GameStop short squeeze, and even funnier is the Top Glove one, that they’re trying to repeat in Malaysia. Bitcoin seems to be doing “reasonably well” and I have to say, I think people are starting to realise decentralised services have a future. How do we get there?
What an interesting week, I look forward to more productive time. I’m still writing in my Hobonichi Techo, so at least that’s where most personal stuff ends up, I guess?
I hit an important OpenHMD milestone tonight – I completed a Beat Saber level using my Oculus Rift CV1!
I’ve been continuing to work on integrating Kalman filtering into OpenHMD, and on improving the computer vision that matches and tracks device LEDs. While I suspect noone will be completing Expert levels just yet, it’s working well enough that I was able to play through a complete level of Beat Saber. For a long time this has been my mental benchmark for tracking performance, and I’m really happy
Check it out:
I should admit at this point that completing this level took me multiple attempts. The tracking still has quite a tendency to lose track of controllers, or to get them confused and swap hands suddenly.
I have a list of more things to work on. See you at the next update!
What an unplanned day. I woke up in time to do an MD workout, despite feeling a little sore. So maybe I was about 10 minutes late and I missed the first set, but his workouts are so long, and I think there were seven sets anyway. Had a good brunch shortly thereafter.
Did a bit of reading, and then I decided to do a beach boardwalk walk… turns out they were policing the place, and you can’t hit the boardwalk. But the beach is fair game? So I went back to the hotel, dropped off my slippers, and went for a beach jog. Pretty nutty.
Came back to read a little more and figured I might as well do another MD workout. Then I headed out for dinner, trying out a new place — Mint Pizza. Opened 20.12.2020, and they’re empty, and their pizza is actually pretty good. Lamb and BBQ chicken, they did half-and-half.
Twitter was discussing Raspberry Pi’s, and all I could see is a lot of misinformation, which is truly shocking. The irony is that open source has been running the Internet for so long, and progressive web apps have come such a long way…
Learn concepts, not tools.
One ensures lifelong flexibility, the other has potential for obsolescence.
Your knowledge of doing a mail merge will spread from Word, to Pages, to Writer or Docs.
Back in the day when I did OpenOffice.org or Linux training even, we always did say you should learn concepts and not tools. From the time we ran Linux installfests in the late-90s in Sunway Pyramid (back then, yes, Linux was hard, and you had winmodems), but I had forgotten that I even did stuff for school teachers and NGOs back in 2002… I won’t forget PC Gemilang either…
Anyway, I placed an order again for another Raspberry Pi 400. I am certain that most people talk so much crap, without realising that Malaysia isn’t a developed nation and most people can’t afford a Mac let alone a PC. Laptops aren’t cheap. And there are so many other issues…. Saying Windows is still required in 2021 is the nuttiest thing I’ve heard in a long time. Easy to tweet, much harder to think about TCO, and realise where in the journey Malaysia is.
Maybe the best thing was that Malaysian Twitter learned about technology. I doubt many realised the difference between a Pi board vs the 400, but hey, the fact that they talked about tech is still a win (misinformed, but a win).
In my experience, the C programming language is still hard to beat, even 50 years after it was first developed (and I feel the same way about UNIX). When it comes to general-purpose utility, low-level systems programming, performance, and portability (even to tiny embedded systems), I would choose C over most modern or fashionable alternatives. In some cases, it is almost the only choice.
Many developers believe that it is difficult to write secure and reliable software in C, due to its free pointers, the lack of enforced memory integrity, and the lack of automatic memory management; however in my opinion it is possible to overcome these risks with discipline and a more secure system of libraries constructed on top of C and libc. Daniel J. Bernstein and Wietse Venema are two developers who have been able to write highly secure, stable, reliable software in C.
My other favourite language is Python. Although Python has numerous desirable features, my favourite is the light-weight syntax: in Python, block structure is indicated by indentation, and braces and semicolons are not required. Apart from the pleasure and relief of reading and writing such light and clear code, which almost appears to be executable pseudo-code, there are many other benefits. In C or JavaScript, if you omit a trailing brace somewhere in the code, or insert an extra brace somewhere, the compiler may tell you that there is a syntax error at the end of the file. These errors can be annoying to track down, and cannot occur in Python. Python not only looks better, the clear syntax helps to avoid errors.
The obvious disadvantage of Python, and other dynamic interpreted languages, is that most programs run extremely slower than C programs. This limits the scope and generality of Python. No AAA or performance-oriented video game engines are programmed in Python. The language is not suitable for low-level systems programming, such as operating system development, device drivers, filesystems, performance-critical networking servers, or real-time systems.
C is a great all-purpose language, but the code is uglier than Python code. Once upon a time, when I was experimenting with the Plan 9 operating system (which is built on C, but lacks Python), I missed Python’s syntax, so I decided to do something about it and write a little preprocessor for C. This converts from a “Pythonesque” indented syntax to regular C with the braces and semicolons. Having forked a little dialect of my own, I continued from there adding other modules and features (which might have been a mistake, but it has been fun and rewarding).
At first I called this translator Brace, because it added in the braces for me. I now call the language CZ. It sounds like “C-easy”. Ease-of-use for developers (DX) is the primary goal. CZ has all of the features of C, and translates cleanly into C, which is then compiled to machine code as normal (using any C compiler; I didn’t write one); and so CZ has the same features and performance as C, but enjoys a more pleasing syntax.
CZ is now self-hosted, in that the translator is written in the language CZ. I confess that originally I wrote most of it in Perl; I’m proficient at Perl, but I consider it to be a fairly ugly language, and overly complicated.
I intend for CZ’s new syntax to be “optional”, ideally a developer will be able to choose to use the normal C syntax when editing CZ, if they prefer it. For this, I need a tool to convert C back to CZ, which I have not fully implemented yet. I am aware that, in addition to traditionalists, some vision-impaired developers prefer to use braces and semicolons, as screen readers might not clearly indicate indentation. A C to CZ translator would of course also be valuable when porting an existing C program to CZ.
CZ has a number of useful features that are not found in standard C, but I did not go so far as C++, which language has been described as “an octopus made by nailing extra legs onto a dog”. I do not consider C to be a dog, at least not in a negative sense; but I think that C++ is not an improvement over plain C. I am creating CZ because I think that it is possible to improve on C, without losing any of its advantages or making it too complex.
One of the most interesting features I added is a simple syntax for fast, light coroutines. I based this on Simon Tatham’s approach to Coroutines in C, which may seem hacky at first glance, but is very efficient and can work very well in practice. I implemented a very fast web server with very clean code using these coroutines. The cost of switching coroutines with this method is little more than the cost of a function call.
CZ has hygienic macros. The regular cpp (C preprocessor) macros are not hygenic and many people consider them hacky and unsafe to use. My CZ macros are safe, and somewhat more powerful than standard C macros. They can be used to neatly add new program control structures. I have plans to further develop the macro system in interesting ways.
I added automatic prototype and header generation, as I do not like having to repeat myself when copying prototypes to separate header files. I added support for the UNIX #! scripting syntax, and for cached executables, which means that CZ can be used like a scripting language without having to use a separate compile or make command, but the programs are only recompiled when something has been changed.
For CZ, I invented a neat approach to portability without conditional compilation directives. Platform-specific library fragments are automatically included from directories having the name of that platform or platform-category. This can work very well in practice, and helps to avoid the nightmare of conditional compilation, feature detection, and Autotools. Using this method, I was able easily to implement portable interfaces to features such as asynchronous IO multiplexing (aka select / poll).
The CZ library includes flexible error handling wrappers, inspired by W. Richard Stevens’ wrappers in his books on Unix Network Programming. If these wrappers are used, there is no need to check return values for error codes, and this makes the code much safer, as an error cannot accidentally be ignored.
CZ has several major faults, which I intend to correct at some point. Some of the syntax is poorly thought out, and I need to revisit it. I developed a fairly rich library to go with the language, including safer data structures, IO, networking, graphics, and sound. There are many nice features, but my CZ library is more prototype than a finished product, there are major omissions, and some features are misconceived or poorly implemented. The misfeatures should be weeded out for the time-being, or moved to an experimental section of the library.
I think that a good software library should come in two parts, the essential low-level APIs with the minimum necessary functionality, and a rich set of high-level convenience functions built on top of the minimal API. I need to clearly separate these two parts in order to avoid polluting the namespaces with all sorts of nonsense!
CZ is lacking a good modern system of symbol namespaces. I can look to Python for a great example. I need to maintain compatibility with C, and avoid ugly symbol encodings. I think I can come up with something that will alleviate the need to type anything like gtk_window_set_default_size, and yet maintain compatibility with the library in question. I want all the power of C, but it should be easy to use, even for children. It should be as easy as BASIC or Processing, a child should be able to write short graphical demos and the like, without stumbling over tricky syntax or obscure compile errors.
Here is an example of a simple CZ program which plots the Mandelbrot set fractal. I think that the program is fairly clear and easy to understand, although there is still some potential to improve and clarify the code.
#!/usr/local/bin/cz --
use b
use ccomplex
Main:
num outside = 16, ox = -0.5, oy = 0, r = 1.5
long i, max_i = 50, rb_i = 30
space()
uint32_t *px = pixel() # CONFIGURE!
num d = 2*r/h, x0 = ox-d*w_2, y0 = oy+d*h_2
for(y, 0, h):
cmplx c = x0 + (y0-d*y)*I
repeat(w):
cmplx w = c
for i=0; i < max_i && cabs(w) < outside; ++i
w = w*w + c
*px++ = i < max_i ? rainbow(i*359 / rb_i % 360) : black
c += d
I wrote a more elaborate variant of this program, which generates images like the one shown below. There are a few tricks used: continuous colouring, rainbow colours, and plotting the logarithm of the iteration count, which makes the plot appear less busy close to the black fractal proper. I sell some T-shirts and other products with these fractal designs online.
An image from the Mandelbrot set, generated by a fairly simple CZ program.
I am interested in graph programming, and have been for three decades since I was a teenager. By graph programming, I mean programming and modelling based on mathematical graphs or diagrams. I avoid the term visual programming, because there is no necessary reason that vision impaired folks could not use a graph programming language; a graph or diagram may be perceived, understood, and manipulated without having to see it.
Mathematics is something that naturally exists, outside time and independent of our universe. We humans discover mathematics, we do not invent or create it. One of my main ideas for graph programming is to represent a mathematical (or software) model in the simplest and most natural way, using relational operators. Elementary mathematics can be reduced to just a few such operators:
+
add, subtract, disjoint union, zero
×
multiply, divide, cartesian product, one
^
power, root, logarithm
◢
sin, cos, sin-1, cos-1, hypot, atan2
δ
differential, integral
a set of minimal relational operators for elementary math
I think that a language and notation based on these few operators (and similar) can be considerably simpler and more expressive than conventional math or programming languages.
CZ is for me a stepping-stone toward this goal of an expressive relational graph language. It is more pleasant for me to develop software tools in CZ than in C or another language.
My CZ project has been stalled for quite some time. I foolishly became discouraged after receiving some negative feedback. I now know that honest negative feedback should be valued as an opportunity to improve, and I intend to continue the project until it lacks glaring faults, and is useful for other people. If this project or this article interests you, please contact me and let me know. It is much more enjoyable to work on a project when other people are actively interested in it!
Skwashd Services Pty is committed to providing quality services to
you and this policy outlines our ongoing obligations to you in respect
of how we manage your Personal Information.
We have adopted the Australian Privacy Principles (APPs) contained in
the Privacy Act 1988 (Cth) (the Privacy Act). The NPPs govern the way in
which we collect, use, disclose, store, secure and dispose of your
Personal Information.
A copy of the Australian Privacy Principles may be obtained from the
website of The Office of the Australian Information Commissioner at
www.oaic.gov.au
What is Personal Information and why do we collect it?
Personal Information is information or an opinion that
identifies an individual. Examples of Personal Information we collect
include: names, addresses, email addresses, phone and facsimile numbers.
This Personal Information is obtained in many ways including correspondence, by
telephone, by email, via our website www.davehall.com.au, from your website,
from media and publications, from other publicly available sources, from cookies
and from third parties. We don’t guarantee website links or policy of authorised
third parties.
We collect your Personal Information for the primary purpose of
providing our services to you, providing information to our clients and
marketing. We may also use your Personal Information for secondary
purposes closely related to the primary purpose, in circumstances where
you would reasonably expect such use or disclosure. You may unsubscribe
from our mailing/marketing lists at any time by contacting us in
writing.
When we collect Personal Information we will, where appropriate and
where possible, explain to you why we are collecting the information and
how we plan to use it.
Sensitive Information
Sensitive information is defined in the Privacy Act to include
information or opinion about such things as an individual's racial or
ethnic origin, political opinions, membership of a political
association, religious or philosophical beliefs, membership of a trade
union or other professional body, criminal record or health information.
Sensitive information will be used by us only:
• For the primary purpose for which it was obtained
• For a secondary purpose that is directly related to the primary
purpose
• With your consent; or where required or authorised by law.
Third Parties
Where reasonable and practicable to do so, we will collect your Personal
Information only from you. However, in some circumstances we may be
provided with information by third parties. In such a case we will take
reasonable steps to ensure that you are made aware of the information
provided to us by the third party.
Disclosure of Personal Information
Your Personal Information may be disclosed in a number of circumstances
including the following:
• Third parties where you consent to the use or disclosure; and
• Where required or authorised by law.
Security of Personal Information
Your Personal Information is stored in a manner that reasonably protects
it from misuse and loss and from unauthorised access, modification or
disclosure.
When your Personal Information is no longer needed for the purpose for
which it was obtained, we will take reasonable steps to destroy or
permanently de-identify your Personal Information. However, most of the
Personal Information is or will be stored in client files which will be
kept by us for a minimum of 7 years.
Access to your Personal Information
You may access the Personal Information we hold about you and to update
and/or correct it, subject to certain exceptions. If you wish to access
your Personal Information, please contact us in writing.
Skwashd Services Pty Ltd will not charge any fee for your access
request, but may charge an administrative fee for providing a copy of
your Personal Information.
In order to protect your Personal Information we may require
identification from you before releasing the requested information.
Maintaining the Quality of your Personal Information
It is an important to us that your Personal Information is up to date.
We will take reasonable steps to make sure that your Personal
Information is accurate, complete and up-to-date. If you find that the
information we have is not up to date or is inaccurate, please advise us
as soon as practicable so we can update our records and ensure we can
continue to provide quality services to you.
Global Privacy Control
We do not sell or share your Personal Information with third parties for
advertising or any other commercial purpose. The Global Privacy Control
(GPC) signal therefore does not change how we handle your data.
Policy Updates
This Policy may change from time to time and is available on our
website.
Privacy Policy Complaints and Enquiries
If you have any queries or complaints about our Privacy Policy please
contact us at:
In the last post I had started implementing an Unscented Kalman Filter for position and orientation tracking in OpenHMD. Over the Christmas break, I continued that work.
A Quick Recap
When reading below, keep in mind that the goal of the filtering code I’m writing is to combine 2 sources of information for tracking the headset and controllers.
The first piece of information is acceleration and rotation data from the IMU on each device, and the second is observations of the device position and orientation from 1 or more camera sensors.
The IMU motion data drifts quickly (at least for position tracking) and can’t tell which way the device is facing (yaw, but can detect gravity and get pitch/roll).
The camera observations can tell exactly where each device is, but arrive at a much lower rate (52Hz vs 500/1000Hz) and can take a long time to process (hundreds of milliseconds) to analyse to acquire or re-acquire a lock on the tracked device(s).
The goal is to acquire tracking lock, then use the motion data to predict the motion closely enough that we always hit the ‘fast path’ of vision analysis. The key here is closely enough – the more closely the filter can track and predict the motion of devices between camera frames, the better.
Integration in OpenHMD
When I wrote the last post, I had the filter running as a standalone application, processing motion trace data collected by instrumenting a running OpenHMD app and moving my headset and controllers around. That’s a really good way to work, because it lets me run modifications on the same data set and see what changed.
However, the motion traces were captured using the current fusion/prediction code, which frequently loses tracking lock when the devices move – leading to big gaps in the camera observations and more interpolation for the filter.
By integrating the Kalman filter into OpenHMD, the predictions are improved leading to generally much better results. Here’s one trace of me moving the headset around reasonably vigourously with no tracking loss at all.
Headset motion capture trace
If it worked this well all the time, I’d be ecstatic! The predicted position matched the observed position closely enough for every frame for the computer vision to match poses and track perfectly. Unfortunately, this doesn’t happen every time yet, and definitely not with the controllers – although I think the latter largely comes down to the current computer vision having more troubler matching controller poses. They have fewer LEDs to match against compared to the headset, and the LEDs are generally more side-on to a front-facing camera.
Taking a closer look at a portion of that trace, the drift between camera frames when the position is interpolated using the IMU readings is clear.
Headset motion capture – zoomed in view
This is really good. Most of the time, the drift between frames is within 1-2mm. The computer vision can only match the pose of the devices to within a pixel or two – so the observed jitter can also come from the pose extraction, not the filtering.
The worst tracking is again on the Z axis – distance from the camera in this case. Again, that makes sense – with a single camera matching LED blobs, distance is the most uncertain part of the extracted pose.
Losing Track
The trace above is good – the computer vision spots the headset and then the filtering + computer vision track it at all times. That isn’t always the case – the prediction goes wrong, or the computer vision fails to match (it’s definitely still far from perfect). When that happens, it needs to do a full pose search to reacquire the device, and there’s a big gap until the next pose report is available.
That looks more like this
Headset motion capture trace with tracking errors
This trace has 2 kinds of errors – gaps in the observed position timeline during full pose searches and erroneous position reports where the computer vision matched things incorrectly.
Fixing the errors in position reports will require improving the computer vision algorithm and would fix most of the plot above. Outlier rejection is one approach to investigate on that front.
Latency Compensation
There is inherent delay involved in processing of the camera observations. Every 19.2ms, the headset emits a radio signal that triggers each camera to capture a frame. At the same time, the headset and controller IR LEDS light up brightly to create the light constellation being tracked. After the frame is captured, it is delivered over USB over the next 18ms or so and then submitted for vision analysis. In the fast case where we’re already tracking the device the computer vision is complete in a millisecond or so. In the slow case, it’s much longer.
Overall, that means that there’s at least a 20ms offset between when the devices are observed and when the position information is available for use. In the plot above, this delay is ignored and position reports are fed into the filter when they are available. In the worst case, that means the filter is being told where the headset was hundreds of milliseconds earlier.
To compensate for that delay, I implemented a mechanism in the filter where it keeps extra position and orientation entries in the state that can be used to retroactively apply the position observations.
The way that works is to make a prediction of the position and orientation of the device at the moment the camera frame is captured and copy that prediction into the extra state variable. After that, it continues integrating IMU data as it becomes available while keeping the auxilliary state constant.
When a the camera frame analysis is complete, that delayed measurement is matched against the stored position and orientation prediction in the state and the error used to correct the overall filter. The cool thing is that in the intervening time, the filter covariance matrix has been building up the right correction terms to adjust the current position and orientation.
Here’s a good example of the difference:
Before: Position filtering with no latency compensationAfter: Latency-compensated position reports
Notice how most of the disconnected segments have now slotted back into position in the timeline. The ones that haven’t can either be attributed to incorrect pose extraction in the compute vision, or to not having enough auxilliary state slots for all the concurrent frames.
At any given moment, there can be a camera frame being analysed, one arriving over USB, and one awaiting “long term” analysis. The filter needs to track an auxilliary state variable for each frame that we expect to get pose information from later, so I implemented a slot allocation system and multiple slots.
The downside is that each slot adds 6 variables (3 position and 3 orientation) to the covariance matrix on top of the 18 base variables. Because the covariance matrix is square, the size grows quadratically with new variables. 5 new slots means 30 new variables – leading to a 48 x 48 covariance matrix instead of 18 x 18. That is a 7-fold increase in the size of the matrix (48 x 48 = 2304 vs 18 x 18 = 324) and unfortunately about a 10x slow-down in the filter run-time.
At that point, even after some optimisation and vectorisation on the matrix operations, the filter can only run about 3x real-time, which is too slow. Using fewer slots is quicker, but allows for fewer outstanding frames. With 3 slots, the slow-down is only about 2x.
There are some other possible approaches to this problem:
Running the filtering delayed, only integrating IMU reports once the camera report is available. This has the disadvantage of not reporting the most up-to-date estimate of the user pose, which isn’t great for an interactive VR system.
Keeping around IMU reports and rewinding / replaying the filter for late camera observations. This limits the overall increase in filter CPU usage to double (since we at most replay every observation twice), but potentially with large bursts when hundreds of IMU readings need replaying.
It might be possible to only keep 2 “full” delayed measurement slots with both position and orientation, and to keep some position-only slots for others. The orientation of the headset tends to drift much more slowly than position does, so when there’s a big gap in the tracking it would be more important to be able to correct the position estimate. Orientation is likely to still be close to correct.
Further optimisation in the filter implementation. I was hoping to keep everything dependency-free, so the filter implementation uses my own naive 2D matrix code, which only implements the features needed for the filter. A more sophisticated matrix library might perform better – but it’s hard to say without doing some testing on that front.
Controllers
So far in this post, I’ve only talked about the headset tracking and not mentioned controllers. The controllers are considerably harder to track right now, but most of the blame for that is in the computer vision part. Each controller has fewer LEDs than the headset, fewer are visible at any given moment, and they often aren’t pointing at the camera front-on.
Oculus Camera view of headset and left controller.
This screenshot is a prime example. The controller is the cluster of lights at the top of the image, and the headset is lower left. The computer vision has gotten confused and thinks the controller is the ring of random blue crosses near the headset. It corrected itself a moment later, but those false readings make life very hard for the filtering.
Position tracking of left controller with lots of tracking loss.
Here’s a typical example of the controller tracking right now. There are some very promising portions of good tracking, but they are interspersed with bursts of tracking losses, and wild drifting from the computer vision giving wrong poses – leading to the filter predicting incorrect acceleration and hence cascaded tracking losses. Particularly (again) on the Z axis.
Timing Improvements
One of the problems I was looking at in my last post is variability in the arrival timing of the various USB streams (Headset reports, Controller reports, camera frames). I improved things in OpenHMD on that front, to use timestamps from the devices everywhere (removing USB timing jitter from the inter-sample time).
There are still potential problems in when IMU reports from controllers get updated in the filters vs the camera frames. That can be on the order of 2-4ms jitter. Time will tell how big a problem that will be – after the other bigger tracking problems are resolved.
Sponsorships
All the work that I’m doing implementing this positional tracking is a combination of my free time, hours contributed by my employer Centricular and contributions from people via Github Sponsorships. If you’d like to help me spend more hours on this and fewer on other paying work, I appreciate any contributions immensely!
Next Steps
The next things on my todo list are:
Integrate the delayed-observation processing into OpenHMD (at the moment it is only in my standalone simulator).
Improve the filter code structure – this is my first kalman filter and there are some implementation decisions I’d like to revisit.
Publish the UKF branch for other people to try.
Circle back to the computer vision and look at ways to improve the pose extraction and better reject outlying / erroneous poses, especially for the controllers.
Think more about how to best handle / schedule analysis of frames from multiple cameras. At the moment each camera operates as a separate entity, capturing frames and analysing them in threads without considering what is happening in other cameras. That means any camera that can’t see a particular device starts doing full pose searches – which might be unnecessary if another camera still has a good view of the device. Coordinating those analyses across cameras could yield better CPU consumption, and let the filter retain fewer delayed observation slots.
While I hope to update this site again soon, here’s a photo I captured over the weekend in my back yard. The red flowering plant is attracting wattlebirds and honey-eaters. This wattlebird stayed still long enough for me to take this shot. After a little bit of editing, I think it has turned out rather well.
Photo taken with: Canon 7D Mark II & Canon 55-250mm lens.
Edited in Lightroom and Photoshop (to remove a sun glare spot off the eye).
I gave the talk Practicality Beats Purity: The Zen of Python’s Escape Hatch as part of PyConline AU 2020, the very online replacement for PyCon AU this year. In that talk, I included a few interesting links code samples which you may be interested in:
__NOT_A_MATCHER__=object()__MATCHER_SORT_KEY__=0defswitch(cls):inst=cls()methods=[]forattrindir(inst):method=getattr(inst,attr)matcher=getattr(method,"__matcher__",__NOT_A_MATCHER__)ifmatcher==__NOT_A_MATCHER__:continuemethods.append(method)methods.sort(key=lambdai:i.__matcher_sort_key__)formethodinmethods:matches=method.__matcher__()ifmatches:returnmethod()raiseValueError(f"No matcher matches value {test_value}")defcase(matcher):def__decorator__(f):global__MATCHER_SORT_KEY__f.__matcher__=matcherf.__matcher_sort_key__=__MATCHER_SORT_KEY____MATCHER_SORT_KEY__+=1returnfreturn__decorator__if__name__=="__main__":foriinrange(100):@switchclassFizzBuzz:@case(lambda:i%15==0)deffizzbuzz(self):return"fizzbuzz"@case(lambda:i%3==0)deffizz(self):return"fizz"@case(lambda:i%5==0)defbuzz(self):return"buzz"@case(lambda:True)defdefault(self):return"-"print(f"{i}{FizzBuzz}")
fuck grey text on white backgrounds
fuck grey text on black backgrounds
fuck thin, spindly fonts
fuck 10px text
fuck any size of anything in px
fuck font-weight 300
fuck unreadable web pages
fuck themes that implement this unreadable idiocy
fuck sites that don’t work without javascript
fuck reactjs and everything like it
thank fuck for Stylus. and uBlock Origin. and uMatrix.
Earlier today I launched this site. It is the result of a lot of work over the past few weeks. It began as an idea to publicise some of my photos, and morphed into the site you see now, including a store and blog that I’ve named “Photekgraddft”.
In the weirdly named blog, I want to talk about photography, the stories behind some of my more interesting shots, the gear and software I use, my technology career, my recent ADHD diagnosis and many other things.
This scares me quite a lot. I’ve never really put myself out onto the internet before. If you Google me, you’re not going to find anything much. Google Images has no photos of me. I’ve always liked it that way. Until now.
ADHD’ers are sometimes known for “oversharing”, one of the side-effects of the inability to regulate emotions well. I’ve always been the opposite, hiding, because I knew I was different, but didn’t understand why.
The combination of the COVID-19 pandemic and my recent ADHD diagnosis have given me a different perspective. I now know why I hid. And now I want to engage, and be engaged, in the world.
If I can be a force for positive change, around people’s knowledge and opinion of ADHD, then I will.
If talking about Business Analysis (my day job), and sharing my ideas for optimising organisations helps anyone at all, then I will.
If I can show my photos and brighten someone’s day by allowing them to enjoy a sunset, or a flying bird, then I will.
And if anyone buys any of my photos, then I will be shocked!
So welcome to my little vanity project. I hope it can be something positive, for me, if for noone else in this new, odd world in which we now find ourselves living together.
Some time ago, I wrote “floats, bits, and constant expressions” about converting floating point number into its representative ones and zeros as a C++ constant expression – constructing the IEEE 754 representation without being able to examine the bits directly.
I’ve been playing around with Rust recently, and rewrote that conversion code as a bit of a learning exercise for myself, with a thoroughly contrived set of constraints: using integer and single-precision floating point math, at compile time, without unsafe blocks, while using as few unstable features as possible.
I’ve included the listing below, for your bemusement and/or head-shaking, and you can play with the code in the Rust Playground and rust.godbolt.org
// Jonathan Adamczewski 2020-05-12
//
// Constructing the bit-representation of an IEEE 754 single precision floating
// point number, using integer and single-precision floating point math, at
// compile time, in rust, without unsafe blocks, while using as few unstable
// features as I can.
//
// or "What if this silly C++ thing https://brnz.org/hbr/?p=1518 but in Rust?"
// Q. Why? What is this good for?
// A. To the best of my knowledge, this code serves no useful purpose.
// But I did learn a thing or two while writing it :)
// This is needed to be able to perform floating point operations in a const
// function:
#![feature(const_fn)]
// bits_transmute(): Returns the bits representing a floating point value, by
// way of std::mem::transmute()
//
// For completeness (and validation), and to make it clear the fundamentally
// unnecessary nature of the exercise :D - here's a short, straightforward,
// library-based version. But it needs the const_transmute flag and an unsafe
// block.
#![feature(const_transmute)]
const fn bits_transmute(f: f32) -> u32 {
unsafe { std::mem::transmute::<f32, u32>(f) }
}
// get_if_u32(predicate:bool, if_true: u32, if_false: u32):
// Returns if_true if predicate is true, else if_false
//
// If and match are not able to be used in const functions (at least, not
// without #![feature(const_if_match)] - so here's a branch-free select function
// for u32s
const fn get_if_u32(predicate: bool, if_true: u32, if_false: u32) -> u32 {
let pred_mask = (-1 * (predicate as i32)) as u32;
let true_val = if_true & pred_mask;
let false_val = if_false & !pred_mask;
true_val | false_val
}
// get_if_f32(predicate, if_true, if_false):
// Returns if_true if predicate is true, else if_false
//
// A branch-free select function for f32s.
//
// If either is_true or is_false is NaN or an infinity, the result will be NaN,
// which is not ideal. I don't know of a better way to implement this function
// within the arbitrary limitations of this silly little side quest.
const fn get_if_f32(predicate: bool, if_true: f32, if_false: f32) -> f32 {
// can't convert bool to f32 - but can convert bool to i32 to f32
let pred_sel = (predicate as i32) as f32;
let pred_not_sel = ((!predicate) as i32) as f32;
let true_val = if_true * pred_sel;
let false_val = if_false * pred_not_sel;
true_val + false_val
}
// bits(): Returns the bits representing a floating point value.
const fn bits(f: f32) -> u32 {
// the result value, initialized to a NaN value that will otherwise not be
// produced by this function.
let mut r = 0xffff_ffff;
// These floation point operations (and others) cause the following error:
// only int, `bool` and `char` operations are stable in const fn
// hence #![feature(const_fn)] at the top of the file
// Identify special cases
let is_zero = f == 0_f32;
let is_inf = f == f32::INFINITY;
let is_neg_inf = f == f32::NEG_INFINITY;
let is_nan = f != f;
// Writing this as !(is_zero || is_inf || ...) cause the following error:
// Loops and conditional expressions are not stable in const fn
// so instead write this as type coversions, and bitwise operations
//
// "normalish" here means that f is a normal or subnormal value
let is_normalish = 0 == ((is_zero as u32) | (is_inf as u32) |
(is_neg_inf as u32) | (is_nan as u32));
// set the result value for each of the special cases
r = get_if_u32(is_zero, 0, r); // if (iz_zero) { r = 0; }
r = get_if_u32(is_inf, 0x7f80_0000, r); // if (is_inf) { r = 0x7f80_0000; }
r = get_if_u32(is_neg_inf, 0xff80_0000, r); // if (is_neg_inf) { r = 0xff80_0000; }
r = get_if_u32(is_nan, 0x7fc0_0000, r); // if (is_nan) { r = 0x7fc0_0000; }
// It was tempting at this point to try setting f to a "normalish" placeholder
// value so that special cases do not have to be handled in the code that
// follows, like so:
// f = get_if_f32(is_normal, f, 1_f32);
//
// Unfortunately, get_if_f32() returns NaN if either input is NaN or infinite.
// Instead of switching the value, we work around the non-normalish cases
// later.
//
// (This whole function is branch-free, so all of it is executed regardless of
// the input value)
// extract the sign bit
let sign_bit = get_if_u32(f < 0_f32, 1, 0);
// compute the absolute value of f
let mut abs_f = get_if_f32(f < 0_f32, -f, f);
// This part is a little complicated. The algorithm is functionally the same
// as the C++ version linked from the top of the file.
//
// Because of the various contrived constraints on thie problem, we compute
// the exponent and significand, rather than extract the bits directly.
//
// The idea is this:
// Every finite single precision float point number can be represented as a
// series of (at most) 24 significant digits as a 128.149 fixed point number
// (128: 126 exponent values >= 0, plus one for the implicit leading 1, plus
// one more so that the decimal point falls on a power-of-two boundary :)
// 149: 126 negative exponent values, plus 23 for the bits of precision in the
// significand.)
//
// If we are able to scale the number such that all of the precision bits fall
// in the upper-most 64 bits of that fixed-point representation (while
// tracking our effective manipulation of the exponent), we can then
// predictably and simply scale that computed value back to a range than can
// be converted safely to a u64, count the leading zeros to determine the
// exact exponent, and then shift the result into position for the final u32
// representation.
// Start with the largest possible exponent - subsequent steps will reduce
// this number as appropriate
let mut exponent: u32 = 254;
{
// Hex float literals are really nice. I miss them.
// The threshold is 2^87 (think: 64+23 bits) to ensure that the number will
// be large enough that, when scaled down by 2^64, all the precision will
// fit nicely in a u64
const THRESHOLD: f32 = 154742504910672534362390528_f32; // 0x1p87f == 2^87
// The scaling factor is 2^41 (think: 64-23 bits) to ensure that a number
// between 2^87 and 2^64 will not overflow in a single scaling step.
const SCALE_UP: f32 = 2199023255552_f32; // 0x1p41f == 2^41
// Because loops are not available (no #![feature(const_loops)], and 'if' is
// not available (no #![feature(const_if_match)]), perform repeated branch-
// free conditional multiplication of abs_f.
// use a macro, because why not :D It's the most compact, simplest option I
// could find.
macro_rules! maybe_scale {
() => {{
// care is needed: if abs_f is above the threshold, multiplying by 2^41
// will cause it to overflow (INFINITY) which will cause get_if_f32() to
// return NaN, which will destroy the value in abs_f. So compute a safe
// scaling factor for each iteration.
//
// Roughly equivalent to :
// if (abs_f < THRESHOLD) {
// exponent -= 41;
// abs_f += SCALE_UP;
// }
let scale = get_if_f32(abs_f < THRESHOLD, SCALE_UP, 1_f32);
exponent = get_if_u32(abs_f < THRESHOLD, exponent - 41, exponent);
abs_f = get_if_f32(abs_f < THRESHOLD, abs_f * scale, abs_f);
}}
}
// 41 bits per iteration means up to 246 bits shifted.
// Even the smallest subnormal value will end up in the desired range.
maybe_scale!(); maybe_scale!(); maybe_scale!();
maybe_scale!(); maybe_scale!(); maybe_scale!();
}
// Now that we know that abs_f is in the desired range (2^87 <= abs_f < 2^128)
// scale it down to be in the range (2^23 <= _ < 2^64), and convert without
// loss of precision to u64.
const INV_2_64: f32 = 5.42101086242752217003726400434970855712890625e-20_f32; // 0x1p-64f == 2^64
let a = (abs_f * INV_2_64) as u64;
// Count the leading zeros.
// (C++ doesn't provide a compile-time constant function for this. It's nice
// that rust does :)
let mut lz = a.leading_zeros();
// if the number isn't normalish, lz is meaningless: we stomp it with
// something that will not cause problems in the computation that follows -
// the result of which is meaningless, and will be ignored in the end for
// non-normalish values.
lz = get_if_u32(!is_normalish, 0, lz); // if (!is_normalish) { lz = 0; }
{
// This step accounts for subnormal numbers, where there are more leading
// zeros than can be accounted for in a valid exponent value, and leading
// zeros that must remain in the final significand.
//
// If lz < exponent, reduce exponent to its final correct value - lz will be
// used to remove all of the leading zeros.
//
// Otherwise, clamp exponent to zero, and adjust lz to ensure that the
// correct number of bits will remain (after multiplying by 2^41 six times -
// 2^246 - there are 7 leading zeros ahead of the original subnormal's
// computed significand of 0.sss...)
//
// The following is roughly equivalent to:
// if (lz < exponent) {
// exponent = exponent - lz;
// } else {
// exponent = 0;
// lz = 7;
// }
// we're about to mess with lz and exponent - compute and store the relative
// value of the two
let lz_is_less_than_exponent = lz < exponent;
lz = get_if_u32(!lz_is_less_than_exponent, 7, lz);
exponent = get_if_u32( lz_is_less_than_exponent, exponent - lz, 0);
}
// compute the final significand.
// + 1 shifts away a leading 1-bit for normal, and 0-bit for subnormal values
// Shifts are done in u64 (that leading bit is shifted into the void), then
// the resulting bits are shifted back to their final resting place.
let significand = ((a << (lz + 1)) >> (64 - 23)) as u32;
// combine the bits
let computed_bits = (sign_bit << 31) | (exponent << 23) | significand;
// return the normalish result, or the non-normalish result, as appopriate
get_if_u32(is_normalish, computed_bits, r)
}
// Compile-time validation - able to be examined in rust.godbolt.org output
pub static BITS_BIGNUM: u32 = bits(std::f32::MAX);
pub static TBITS_BIGNUM: u32 = bits_transmute(std::f32::MAX);
pub static BITS_LOWER_THAN_MIN: u32 = bits(7.0064923217e-46_f32);
pub static TBITS_LOWER_THAN_MIN: u32 = bits_transmute(7.0064923217e-46_f32);
pub static BITS_ZERO: u32 = bits(0.0f32);
pub static TBITS_ZERO: u32 = bits_transmute(0.0f32);
pub static BITS_ONE: u32 = bits(1.0f32);
pub static TBITS_ONE: u32 = bits_transmute(1.0f32);
pub static BITS_NEG_ONE: u32 = bits(-1.0f32);
pub static TBITS_NEG_ONE: u32 = bits_transmute(-1.0f32);
pub static BITS_INF: u32 = bits(std::f32::INFINITY);
pub static TBITS_INF: u32 = bits_transmute(std::f32::INFINITY);
pub static BITS_NEG_INF: u32 = bits(std::f32::NEG_INFINITY);
pub static TBITS_NEG_INF: u32 = bits_transmute(std::f32::NEG_INFINITY);
pub static BITS_NAN: u32 = bits(std::f32::NAN);
pub static TBITS_NAN: u32 = bits_transmute(std::f32::NAN);
pub static BITS_COMPUTED_NAN: u32 = bits(std::f32::INFINITY/std::f32::INFINITY);
pub static TBITS_COMPUTED_NAN: u32 = bits_transmute(std::f32::INFINITY/std::f32::INFINITY);
// Run-time validation of many more values
fn main() {
let end: usize = 0xffff_ffff;
let count = 9_876_543; // number of values to test
let step = end / count;
for u in (0..=end).step_by(step) {
let v = u as u32;
// reference
let f = unsafe { std::mem::transmute::<u32, f32>(v) };
// compute
let c = bits(f);
// validation
if c != v &&
!(f.is_nan() && c == 0x7fc0_0000) && // nans
!(v == 0x8000_0000 && c == 0) { // negative 0
println!("{:x?} {:x?}", v, c);
}
}
}
Over the weekend, the boredom of COVID-19 isolation motivated me to move my personal website from WordPress on a self-managed 10-year-old virtual private server to a generated static site on a static site hosting platform with a content delivery network.
This decision was overdue. WordPress never fit my brain particularly well, and it was definitely getting to a point where I wasn’t updating my website at all (my last post was two weeks before I moved from Hobart; I’ve been living in Petaluma for more than three years now).
Settling on which website framework wasn’t a terribly difficult choice (I chose Jekyll, everyone else seems to be using it), and I’ve had friends who’ve had success moving their blogs over. The difficulty I ended up facing was that the standard exporter that everyone to move from WordPress to Jekyll uses does not expect Debian’s package layout.
Backing up a bit: I made a choice, 10 years ago, to deploy WordPress on a machine that I ran myself, using the Debian system wordpress package, a simple aptitude install wordpress away. That decision was not particularly consequential then, but it chewed up 3 hours of my time on Saturday.
Why? The exporter plugin assumes that it will be able to find all of the standard WordPress files in the usual WordPress places, and when it didn’t find that, it broke in unexpected ways. And why couldn’t it find it?
Debian makes packaging choices that prioritise all the software on a system living side-by-side with minimal difficulty. It sets strict permissions. It separates application code from configuration from user data (which in the case of WordPress, includes plugins), in a way that is consistent between applications. This choice makes it easy for Debian admins to understand how to find bits of an application. It also minimises the chance of one PHP application from clobbering another.
10 years later, the install that I had set up was still working, having survived 3-4 Debian versions, and so 3-4 new WordPress versions. I don’t recall the last time I had to think about keeping my WordPress instance secure and updated. That’s quite a good run. I’ve had a working website despite not caring about keeping it updated for at least three years.
The same decisions that meant I spent 3 hours on Saturday doing a simple WordPress export saved me a bunch of time that I didn’t incrementally spend over the course a decade. Am I even? I have no idea.
Anyway, the least I can do is provide some help to people who might run into this same problem, so here’s a 5-step howto.
How to migrate a Debian WordPress site to Jekyll
Should you find the Jekyll exporter not working on your Debian WordPress install:
Use the standard WordPress export to export an XML feel of your site.
Spin up a new instance of WordPress (using WordPress.com, or on a new Virtual Private Server, whatever, really).
Import the exported XML feed.
Install the Jekyll exporter plugin.
Follow the documentation and receive a Jekyll export of your site.
Basically, the plugin works with a stock WordPress install. If you don’t have one of those, it’s easy to move it over.
I've spent the last couple of days trying to deploy Fedora CoreOS to some physical hardware/bare metal for a colleague using the official PXE installer from Fedora CoreOS. It wasn't very pleasant, and just wouldn't work reliably.
Maybe my expectations were to high, in that I thought I could use Ignition to prepare more of the system for me, as my colleague has been able to bare metal installs correctly. I just tried to use Ignition as documented.
A few interesting aspects I encountered:
The PXE installer for it has a 618MB initrd file. This takes quite a while to transfer via tftp!
It can't build software RAID for the main install device (and the developers have no intention of adding this), and it seems very finicky to build other RAID sets for other partitions.
And, well, I just kept having problems where the built systems would hang during boot for no obvious reason.
The time to do an installation was incredibly long.
The initrd image is really just running coreos-installer against the nominated device.
During the night I got feed up with that process and wrote a Fully Automatic Installer (FAI) profile that'd install CoreOS instead. I can now use setup-storage from FAI using it's standard disk_config files. This allows me to build complicated disk configurations with software RAID and LVM easily.
A big bonus is that a rebuild is a lot faster, timed from typing reboot to a fresh login prompt is 10 minutes - and this is on physical hardware so includes BIOS POST and RAID controller set up, twice each.
FAI was initially developed to deploy Debian systems, it has since been extended to be able to install a number of other operating systems, however I think this is a good example of how easy it is to deploy non-Debian derived operating systems using FAI without having to modify FAI itself.
For the last year I’ve been incrementally moving away from lifting static weights and towards body weight based exercises, or callisthenics. I’ve been doing this for a number of reasons, including better avoidance of injury (if I collapse, the entire stack is dynamic, if a bar held above my head drops on me, most of the weight is just dead weight – ouch), accessibility during travel – most hotel gyms are very poor, and functional relevance – I literally never need to put 100 kg on my back, but I do climb stairs, for instance.
Covid-19 shutting down the gym where I train is a mild inconvenience for me as a result, because even though I don’t do it, I am able to do nearly all my workouts entirely from home. And I thought a post about this approach might be of interest to other folk newly separated from their training facilities.
I’ve gotten most of my information from a few different youtube channels:
There are many more channels out there, and I encourage you to go and look and read and find out what works for you. Those 5 are my greatest hits, if you will. I’ve bought the FitnessFAQs exercise programs to help me with my my training, and they are indeed very effective.
While you don’t need a gymnasium, you do need some equipment, particularly if you can’t go and use a local park. Exactly what you need will depend on what you choose to do – for instance, doing dips on the edge of a chair can avoid needing any equipment, but doing them with some portable parallel bars can be much easier. Similarly, doing pull ups on the edge of a door frame is doable, but doing them with a pull-up bar is much nicer on your fingers.
Depending on your existing strength you may not need bands, but I certainly did. Buying rings is optional – I love them, but they aren’t needed to have a good solid workout.
I bought parallettes for working on the planche.Parallel bars for dips and rows. A pull-up bar for pull-ups and chin-ups, though with the rings you can add flys, rows, face-pulls, unstable push-ups and more. The rings. And a set of 3 bands that combine for 7 different support amounts.
In terms of routine, I do a upper/lower split, with 3 days on upper body, one day off, one day on lower, and the weekends off entirely. I was doing 2 days on lower body, but found I was over-training with Aikido later that same day.
On upper body days I’ll do (roughly) chin ups or pull ups, push ups, rows, dips, hollow body and arch body holds, handstands and some grip work. Today, as I write this on Sunday evening, 2 days after my last training day on Friday, I can still feel my lats and biceps from training Friday afternoon. Zero issue keeping the intensity up.
For lower body, I’ll do pistol squats, nordic drops, quad extensions, wall sits, single leg calf raises, bent leg calf raises. Again, zero issues hitting enough intensity to achieve growth / strength increases. The only issue at home is having a stable enough step to get a good heel drop for the calf raises.
If you haven’t done bodyweight training at all before, when starting, don’t assume it will be easy – even if you’re a gym junkie, our bodies are surprisingly heavy, and there’s a lot of resistance just moving them around.
The OpenSTEMâ„¢ materials are ideally suited to online teaching. In these times of new challenges and requirements, there are a lot of technological possibilities. Schools and teachers are increasingly being asked to deliver material online to students. Our materials can assist with that process, especially for Humanities and Science subjects from Prep/Kindy/Foundation to Year 6. […]
If a person tests positive to the virus today, that means they were infected at some time in the past. So, what is the lag between infection and a positive test result?
Incubation Lag – about 5 days
When you are infected you don’t show symptoms immediately. Rather, there’s an incubation period before symptoms become apparent. The time between being infected and developing symptoms varies from person to person, but most of the time a person shows symptoms after about 5 days (I recall seeing somewhere that 1 in a 1000 cases will develop symptoms after 14 days).
Presentation Lag – about 2 days
I think it’s fair to also assume that people are not presenting at testing immediately they become ill. It is probably taking them a couple of days from developing symptoms to actually get to the doctor – I read a story somewhere (have since lost the reference) about a young man who went to a party, then felt bad for days but didn’t go for a test until someone else from the party had returned a positive test. Let’s assume there’s a mix of worried well and stoic types and call it 2 days from becoming symptomatic to seeking a test.
Referral Lag – about a day
Assuming that a GP is available straight away and recommends a test immediately, logistically there will still be most of a day taken up between deciding to see a doctor and having a test carried out.
Testing lag – about 2 days
The graph of infections “epi graph” today looks like this:
One thing you notice about the graph is that the new cases bars seem to increase for a couple of days, then decrease – so about 100 new cases in the last 24 hours, but almost 200 in the 24 hours before that. From the graph, the last 3 “dips” have been today (Sunday), last Thursday and last Sunday. This seems to be happening every 3 to 4 days. I initially thought that the dips might mean fewer (or more) people presenting over weekends, but the period is inconsistent with that. I suspect, instead, that this actually means that testing is being batched.
That would mean that neither the peaks nor troughs is representative of infection surges/retreats, but is simply reflecting when tests are being processed. This seems to be a 4 day cycle, so, on average it seems that it would be about 2 days between having the test conducted and receiving a result. So a confirmed case count published today is actually showing confirmed cases as at about 2 days earlier.
Total lag
From the date someone is infected to the time that they receive a positive confirmation is about:
lag = time for symptoms to show+time to seek a test+referral time + time for the test to return a result
So, the published figures on confirmed infections are probably lagging actual infections in the community by about 10 days (5+2+1+2).
If there’s about a 10 day lag between infection and confirmation, then what a figure published today says is that about a week and a half ago there were about this many cases in the community. So, the 22 March figure of 1098 infections is actually really a 12 March figure.
What the lag means for Physical (ie Social) Distancing
The main thing that the lag means is that if we were able to wave a magic wand today and stop all further infections, we would continue to record new infections for about 10 days (and the tail for longer). In practical terms, implementing physical distancing measures will not show any effect on new cases for about a week and a half. That’s because today there are infected people who are yet to be tested.
The silver lining to that is that the physical distancing measures that have been gaining prominence since 15 March should start to show up in the daily case numbers from the middle of the coming week, possibly offset by overseas entrants rushing to make the 20 March entry deadline.
Estimating Actual Infections as at Today
How many people are infected, but unconfirmed as at today? To estimate actual infections you’d need to have some idea of the rate at which infections are increasing. For example, if infections increased by 10% per day for 10 days, then you’d multiply the most recent figure by 1.1 raised to the power of 10 (ie about 2.5). Unfortunately, the daily rate of increase (see table on the wiki page) has varied a fair bit (from 20% to 27%) over the most recent 10 days of data (that is, over the 10 days prior to 12 March, since the 22 March figures roughly correspond to 12 March infections) and there’s no guarantee that since that time the daily increase in infections will have remained stable, particularly in light of the implementation of physical distancing measures. At 23.5% per day, the factor is about 8.
There aren’t any reliable figures we can use to estimate the rate of infection during the current lag period (ie from 12 March to 22 March). This is because the vast majority of cases have not been from unexplained community transmission. Most of the cases are from people who have been overseas in the previous fortnight and they’re the cohort that has been most significantly impacted by recent physical distancing measures. From 15 March, they have been required to self isolate and from 20 March most of their entry into the country has stopped. So I’d expect a surge in numbers up to about 30 March – ie reflecting infections in the cohort of people rushing to get into the country before the borders closed followed by a flattening. With the lag factor above, you’ll need to wait until 1 April or thereabouts to know for sure.
Note:
This post is just about accounting for the time lag between becoming infected and receiving a positive test result. It assumes, for example, that everyone who is infected seeks a test, and that everyone who is infected and seeks a test is, in fact, tested. As at today, neither of these things is true.
As I was an organiser of the conference this year, I didn’t get to see many talks, fortunately many of the talks were recorded, so i get to watch the conference well after the fact.
Conference Opening
That white balance on the lectern slides is indeed bad, I really should get around to adding this as a suggestion on the logos documentation. (With some help, I put up all the lectern covers, it was therapeutic and rush free).
I actually think there was a lot of information in this introduction. Perhaps too much?
OpenZFS and Linux
A nice update on where zfs is these days.
Dev/Ops relationships, status: It’s Complicated
A bit of a war story about production systems, leading to a moment of empathy.
Samba 2020: Why are we still in the 1980s for authentication?
There are a lot of old security standards that are showing there age, there are a lot of modern security standards, but which to choose?
Tyranny of the Clock
A very interesting problem solving adventure, with a few nuggets of interesting information about tools and techniques.
Configuration Is (riskier than?) Code
Because configuration files are parsed by a program, and the program changes how it runs depending on the contents of that configuration file, every program that parses configuration files is basically an interpreter, and thus every configuration file is basically a program. So, configuation is code, and we should be treating configuration like we do code, e.g. revision control, commenting, testing, review.
Easy Geo-Redundant Handover + Failover with MARS + systemd
Using a local process organiser to handle a cluster, interesting, not something I’d really promote. Not the best video cutting in this video, lots of time with the speaker pointing to his slides offscreen.

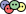









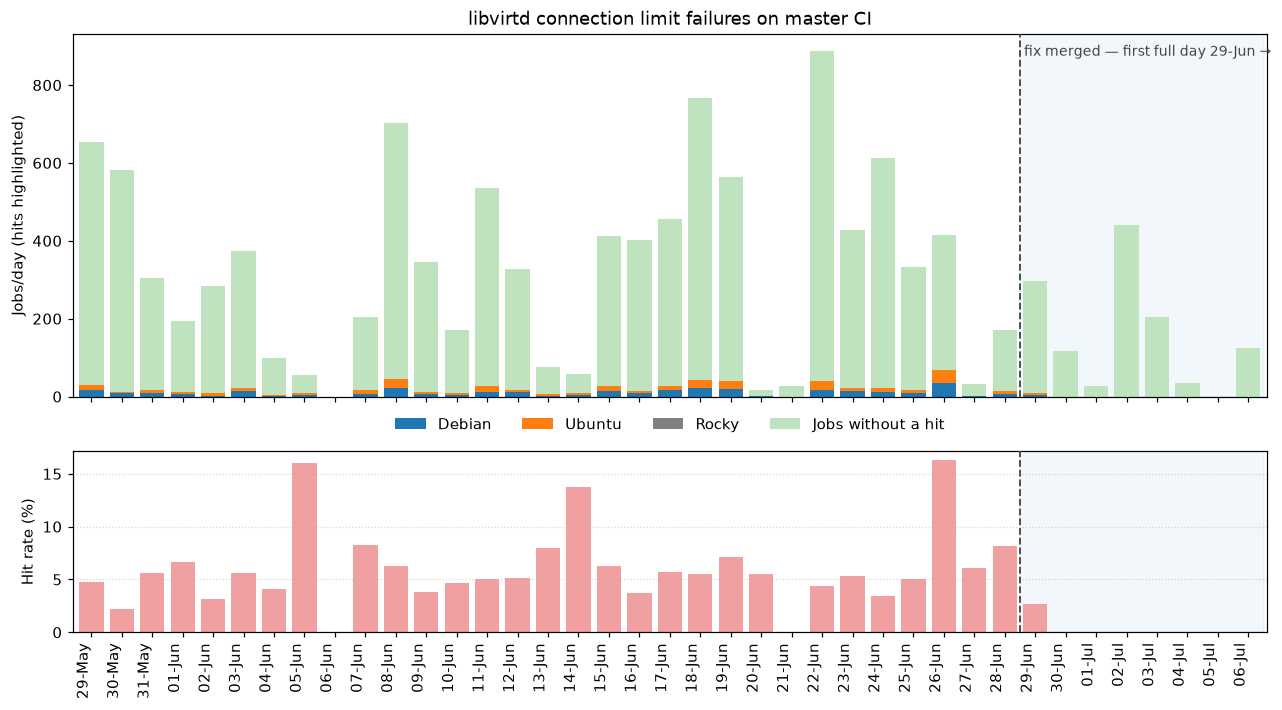




 Wuxi is home to China's
Wuxi is home to China's  A few weeks ago, I had the opportunity to visit Guizhou, China's
A few weeks ago, I had the opportunity to visit Guizhou, China's 

















































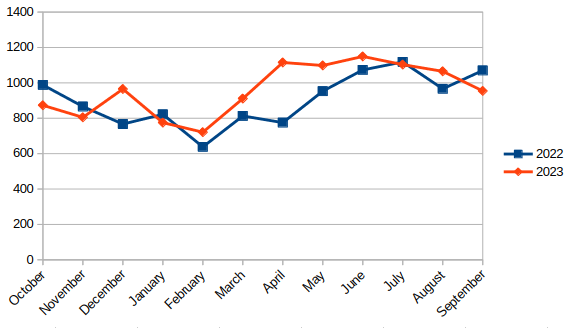




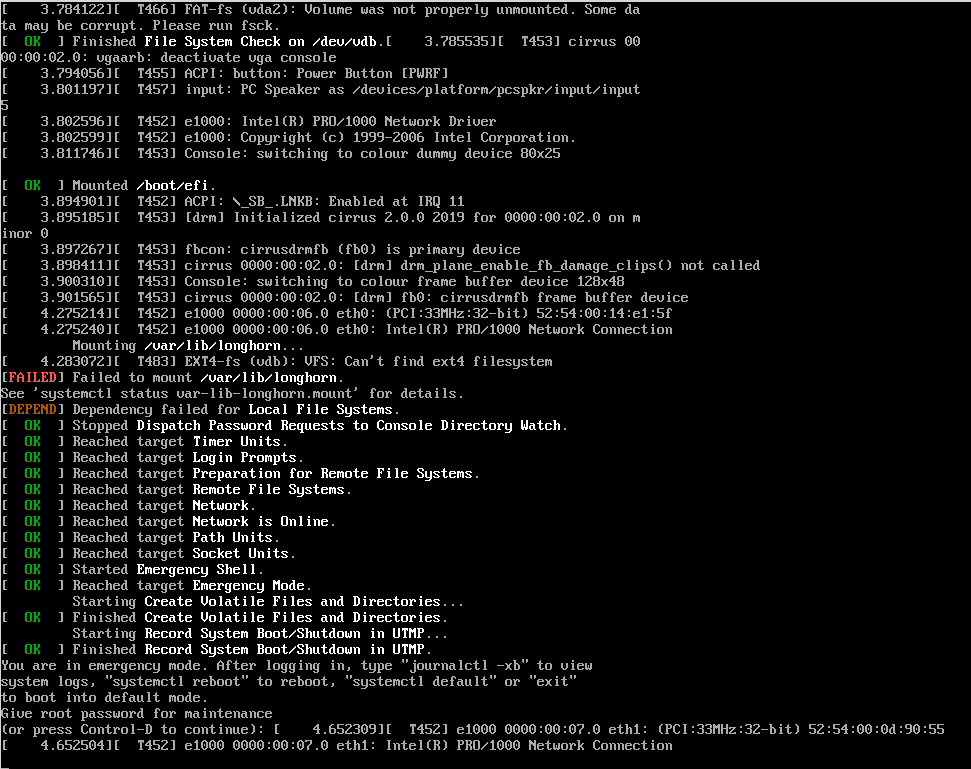
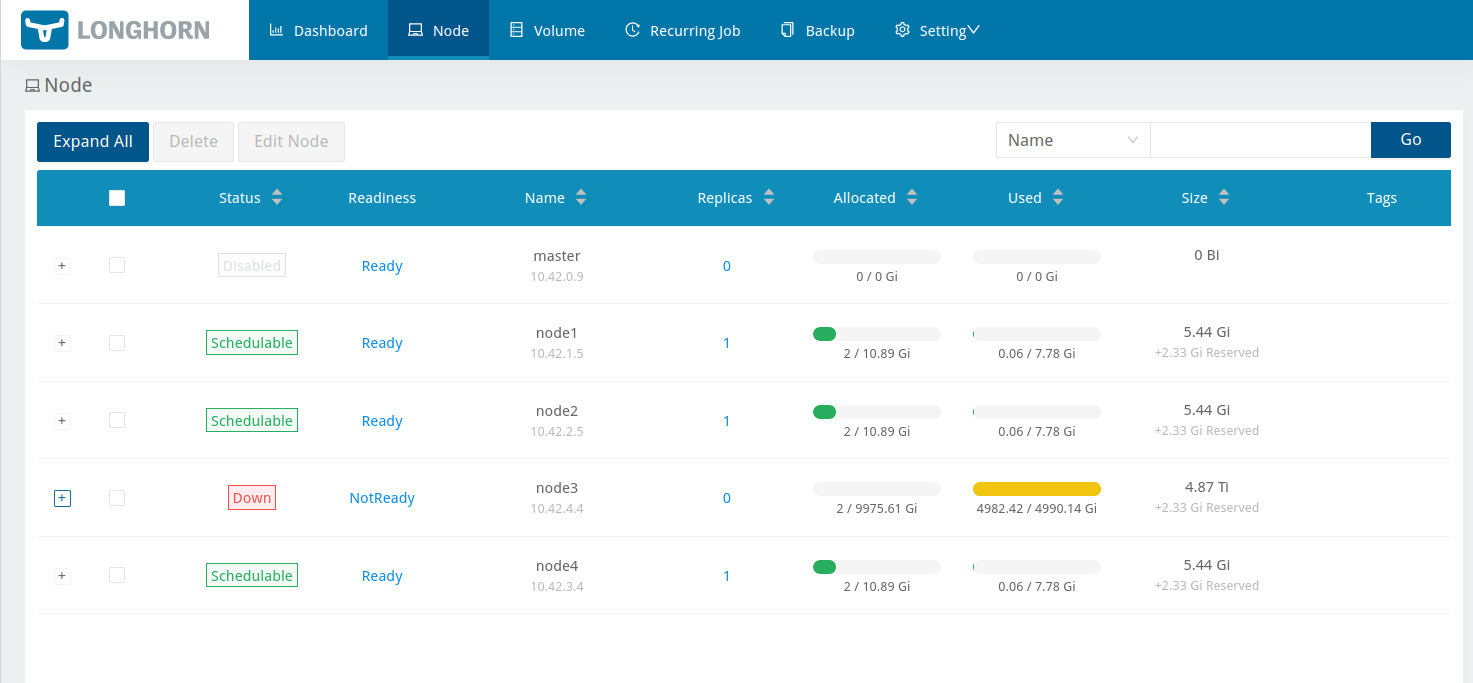
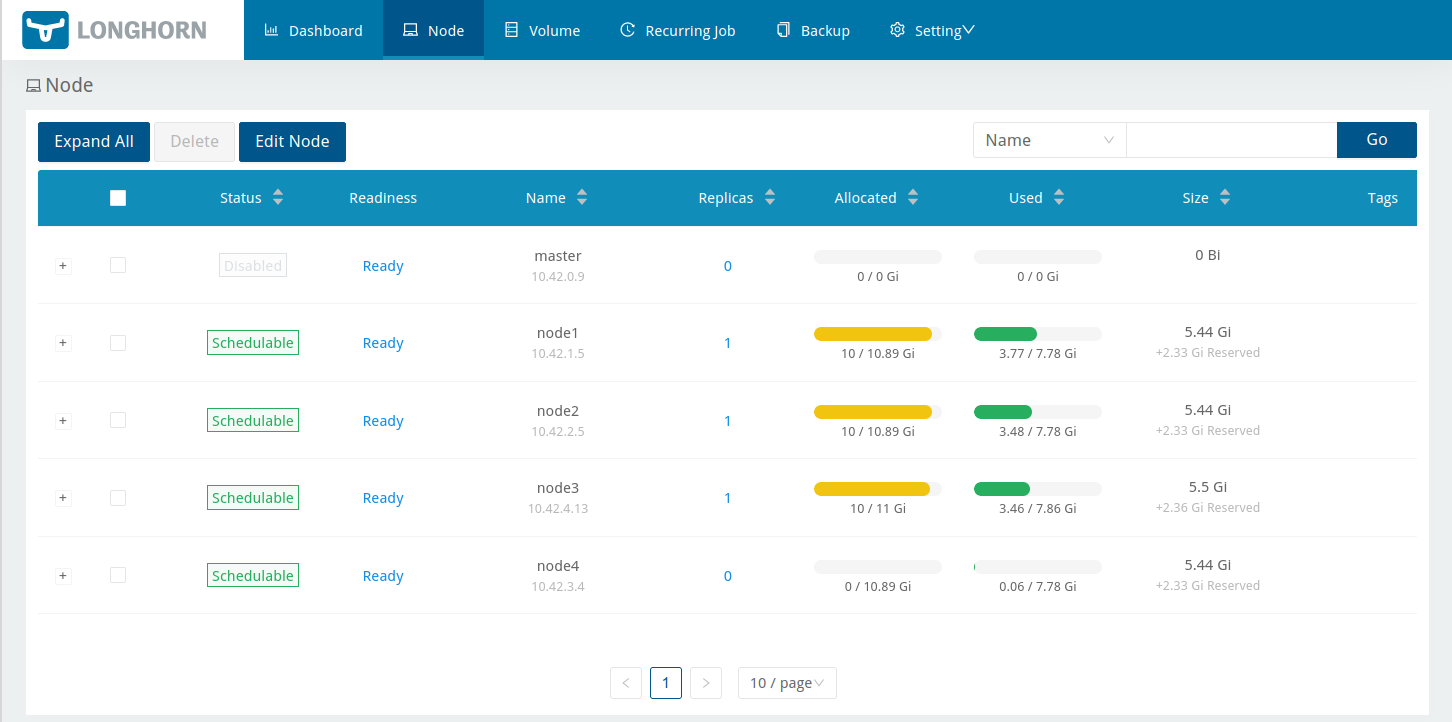
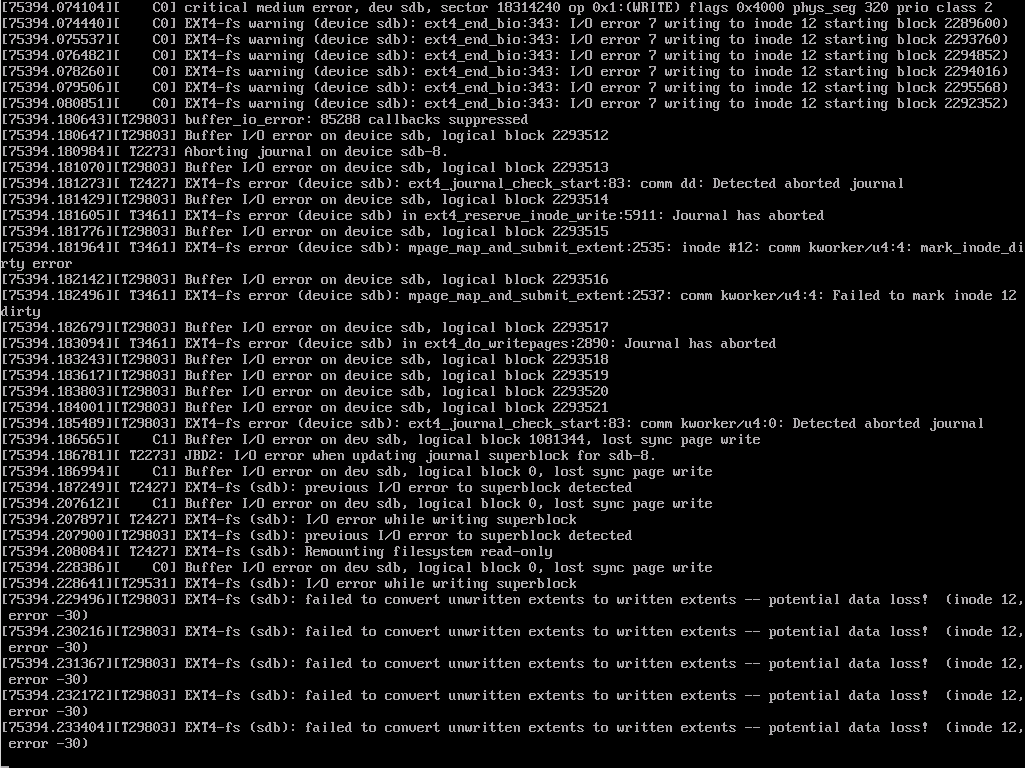
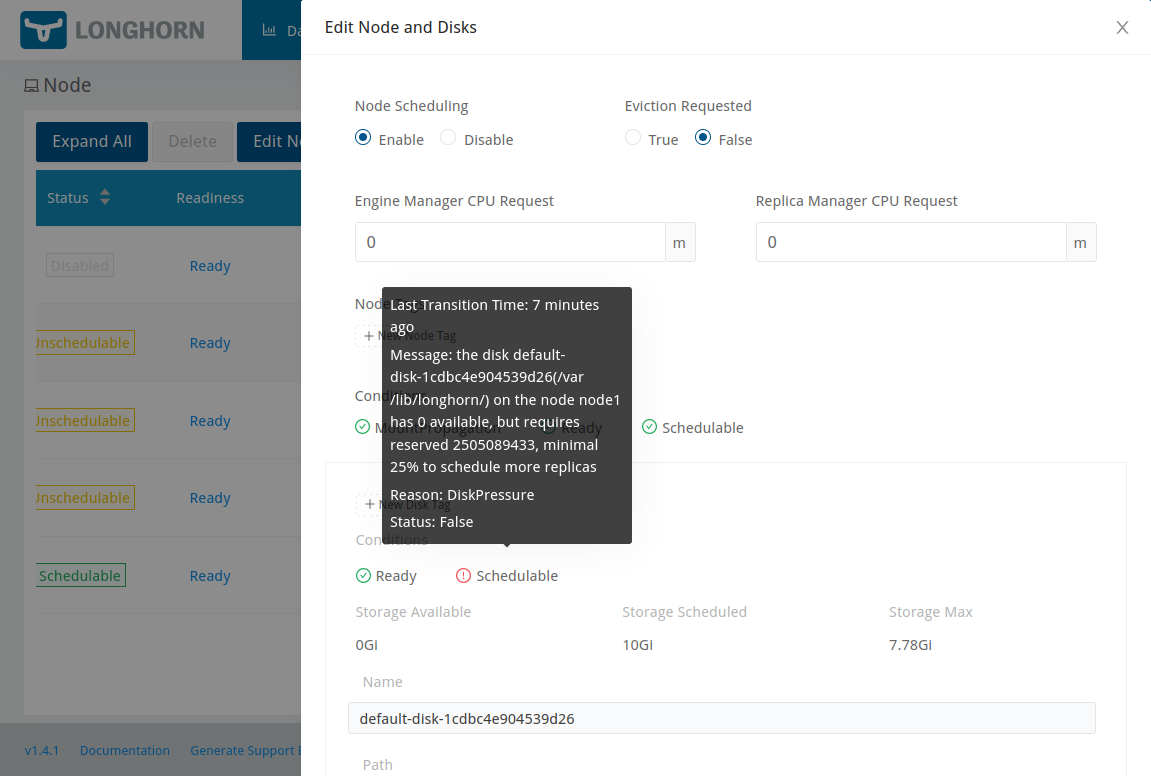







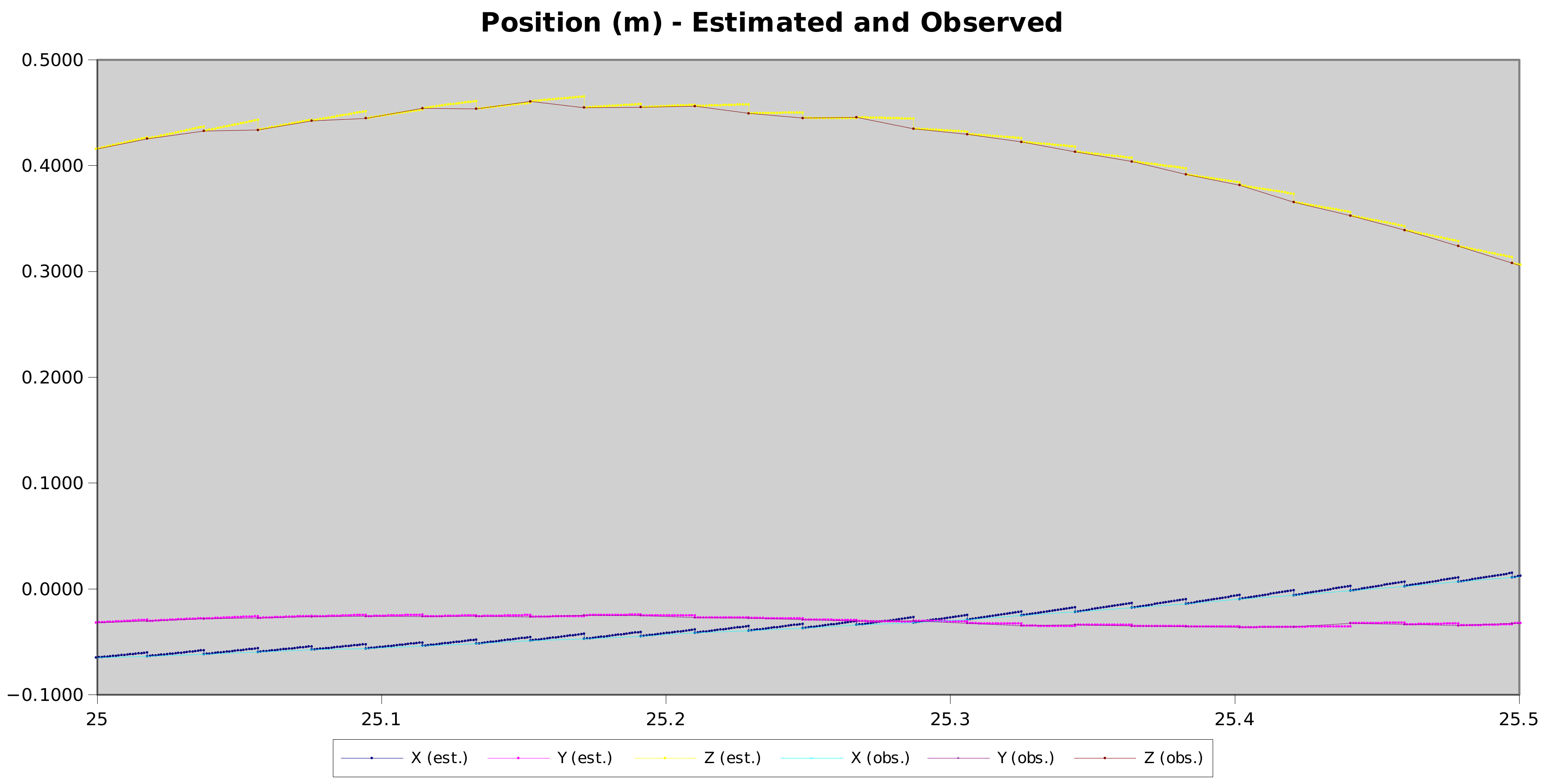






 A
A 

